Microsoft Loop has added support for filters to Tables and Boards.
Users can now easily organize and analyze large quantities of data within Loop Tables and Boards.
The filters feature also extends to Board components and third-party integrations such as JIRA and Trello.
Microsoft has released a new update for its Loop app that should make it easier for users to find and access relevant information. Microsoft Loop users can now apply filters to the content in Loop Tables and Boards.
Microsoft first announced its Loop app in November 2021. The new productivity app, which is built on the Fluid framework, helps users manage tasks, projects, and documents with team members. Microsoft Loop has three main elements: Loop components, Loop workspaces, and Loop pages.
Microsoft highlights that the new filters feature is designed to promote efficient data exploration and analysis within Loop Tables and Boards. Filters improve the overall user experience and promote deeper insights extraction from large quantities of data.
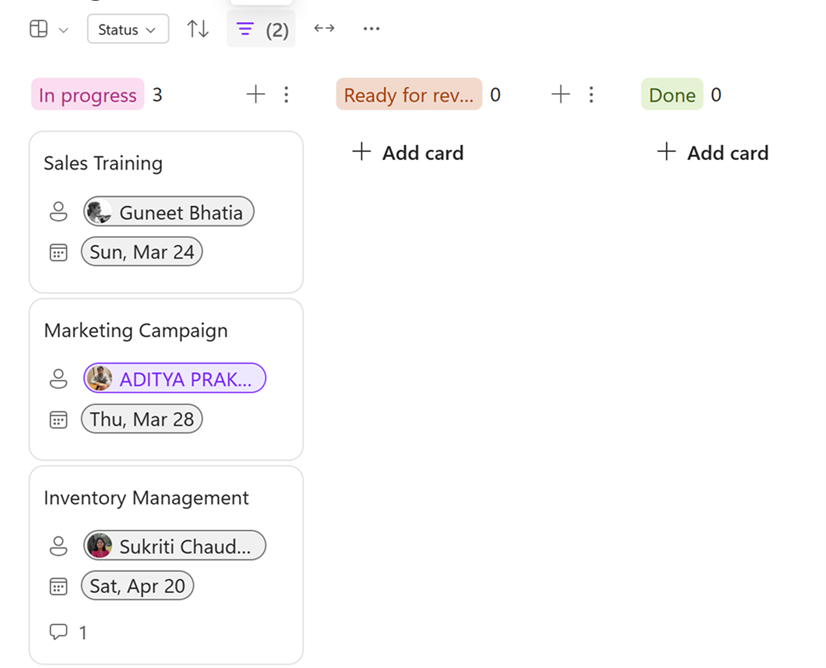
Microsoft Loop filters (Image credits: Microsoft)
How to use filters in Microsoft Loop Tables and Boards
To use filters in Microsoft Loop Tables and Boards, users will need to follow the steps mentioned below:
Log into the Microsoft Loop app and select a table-based component in an existing Loop page or create one.
Navigate to the operations bar at the top of the Table and click the Filter option.
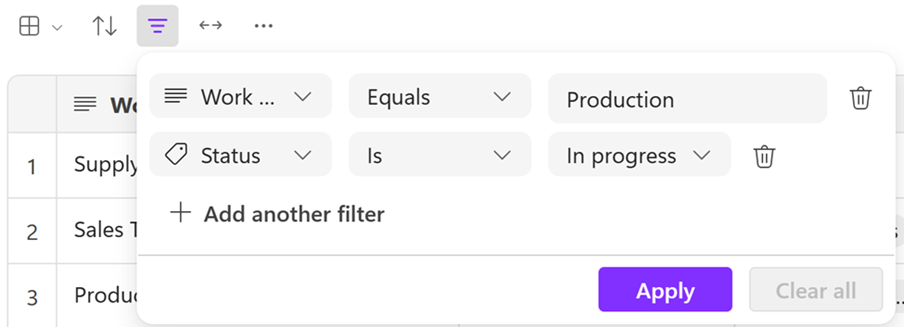
Choose a column, condition, and value to create one or more rules for the filter.
Create rules for filters (Image credits: Microsoft)
Click the Apply button and observe the filter icon, which displays the number of rules applied to a specific Table.
When users add or update rows in a filtered Table, the filter is flagged as “dirty” until they update it.
Microsoft Loop users can apply filters within the Board view as well as on all tabular and Board components.
Filters can also be applied to Task Lists and integrations like GitHub, JIRA, and Trello.
If users define multiple rules for filtering data, the filter will only display the data that satisfies all of these rules. Moreover, the filter will remain active even when switching between different layouts, such as the Table view and the Board view.
The new filters feature is currently available for all Microsoft 365 subscribers. It lets Microsoft Loop users quickly apply filters to streamline data management within Tables or Boards. Users can also easily update/remove filters as required and add rows within filtered tables. Microsoft Loop users have the flexibility to extend this filtering functionality to synced components (like a Task List) or third-party integrations such as GitHub, Trello, and JIRA.
Last month, Microsoft released a new update that allows users to create Power Automate-backed rules to automate time-consuming tasks. The process automation capability is supported in tables, table-based components (like voting tables and task lists), and board-based components in Microsoft Loop.
I live in West London, not San Francisco, so I never expected to enjoy any Artificial Intelligence firsts. But the first Amazon Fresh opened in Ealing in 2021. When I visited late one night, it was largely devoid of customers. There were quite a few staff stacking shelves and milling around, but none at the checkout; because of course, there were no checkouts. You had to confirm you were an Amazon customer via an app when you came in, but after that, you were tracked and your shopping was automatically registered to your Amazon account, and you could “just walk out”. The story at the time was the large number of hidden cameras spying on customers — about a thousand — and we knew that AI was behind the process of logging our shopping habits. The store, which was hemmed in by bigger and more popular supermarkets, shut last summer.
There was some disappointment in the tech community on hearing about Amazon ditching the technology altogether at the start of this month. Some colleagues working with sensors have been somewhat surprised at such a large company giving up on its own technology goals, and there has been the continued whisper of AI still not finding ways to contribute substantially to company profitability.
In his Guardian article last week, the highly respected tech critic James Bridle covered the social dimension — that is, using AI to hide low-paid employment. He reported that about 70% of sales were “reviewed” by a thousand-strong remote team based in India. Apparently, Amazon will be pivoting to smart shopping carts, but this loses the “just walk out” proposition completely. It also proves that there has been no decision to leave the bricks and mortar retail sector; so there has been no radical direction change. It is likely a specific problem with the project.
Fail Faster and Other Software Lessons
From a software developer viewpoint, how did this project from one of the richest businesses on the planet fail? It didn’t fail fast either, clearly. Deciding to discontinue the idea before deployment would have just been chalked down to experience. But this type of public failure is share affecting.
It could be that there were too few project milestones, or some were cut. This could have led to some of the smaller staged rollouts being omitted, leaving insufficient data available to spot upcoming hurdles. When testing, changes to the environment need to be carefully managed, otherwise results can be much harder to interpret. For example, if there were surges of customers at the same time as more theft attempts, it would be much harder to adapt to one of these issues independently.
It could be the team was hoping for generative AI to produce a magic bullet. While research and testing should always improve efficiency for a specific task, maybe an exponential breakthrough was needed in one area. Even with AI improving in leaps and bounds, there still needs to be a stable working position to jump up from. Amazon is big enough to wait and then quickly exploit a change, but that needs careful explanation to stakeholders. This can be trivially disrupted by outside factors.
Scaling back the technology by using a backend human team to override decisions was technically a good idea, but if it was not announced then there were obvious political ramifications. This is an important point for both seniors and product managers to take into consideration — the risks to the company of negative impact from hiding information. Using “mechanical turks” for a short period, and reducing the need for them over time against agreed thresholds, feels like a sane tactic — but it needs transparency and humility. Stating upfront that Amazon Fresh had a human backstop would surely have been sensible. We know that pilots of autonomous car schemes have to have a human ready to take over. However good the AI driving was, this will remain.
There are other ways to lighten the cognitive load for the AI, for example by changing the store layout to make it easier for the sensors. The shelf design in stores is clearly based on known optimal stacking standards, but this makes shoplifting fairly straightforward. While developing the technology, a less combative setup might have helped.
It could be that the feedback elements that agile needs were simply not available by the time the project was installed. Working with staff used to a conventional physical store may have vastly reduced the feedback loop or altered expectations. Projects that cannot improve with feedback are obviously problematic.
When to release and deploy a product has to be a business decision, but it should not be a “fire and forget” affair — especially with novel products. The development team (not just the “operations” part) must be involved because they can spot where assumptions at development can no longer be relied upon in a live environment. They can also bring up forgotten ideas given new circumstances.
AI and Agile
We know that AI still cannot fully appreciate context, nuances, and subtle cues in communication. If one looks at Yann LeCun’s definition of Objective-driven AI systems, what Amazon Fresh was doing seemed to fit in — working towards limited goals and objectives, learning through sensors, and training on video data. But it is possible that doing everything at once was too ambitious. Tracking both an individual’s entrance and exit and tracking their shopping may have been better treated as separate problems for a longer period of time.
Does any of this mean that there won’t be any use of AI in the retail sector? Quite the reverse. There are known projects in retail concerning shelf filling (Morrisons in the UK) and checkout theft (Target, in the US). These projects prove that successful AI-based projects can be designed, developed and rolled out on the shop floor. Because the public has been exposed to the wonders of ChatGPT, there probably still exists a small reservoir of trust in its abilities.
In summary, there is no particular issue with machine learning (other than it might have been easy to fool the leadership team initially regarding any project with the term “AI” in it). Rather, there’s clearly a need to treat AI as a tool like any other and run projects in an agile manner — like any other. Use increasingly larger-scale trials and observe new issues as they arise. Fail fast if some basic assumptions are wrong. Scale back and fix showstopper issues before moving up.
But I’m sure another company is busy continuing where Amazon left off.
When copying text from a website to your device’s clipboard, there’s a good chance that you will get the formatted HTML when pasting it. Some apps and operating systems have a “Paste Special” feature that will strip those tags out for you to maintain the current style, but what do you do if that’s unavailable?
Same goes for converting plain text into formatted HTML. One of the closest ways we can convert plain text into HTML is writing in Markdown as an abstraction. You may have seen examples of this in many comment forms in articles just like this one. Write the comment in Markdown and it is parsed as HTML.
Even better would be no abstraction at all! You may have also seen (and used) a number of online tools that take plainly written text and convert it into formatted HTML. The UI makes the conversion and previews the formatted result in real time.
Providing a way for users to author basic web content — like comments — without knowing even the first thing about HTML, is a novel pursuit as it lowers barriers to communicating and collaborating on the web. Saying it helps “democratize” the web may be heavy-handed, but it doesn’t conflict with that vision!
We can build a tool like this ourselves. I’m all for using existing resources where possible, but I’m also for demonstrating how these things work and maybe learning something new in the process.
Defining The Scope
There are plenty of assumptions and considerations that could go into a plain-text-to-HTML converter. For example, should we assume that the first line of text entered into the tool is a title that needs corresponding <h1> tags? Is each new line truly a paragraph, and how does linking content fit into this?
Again, the idea is that a user should be able to write without knowing Markdown or HTML syntax. This is a big constraint, and there are far too many HTML elements we might encounter, so it’s worth knowing the context in which the content is being used. For example, if this is a tool for writing blog posts, then we can limit the scope of which elements are supported based on those that are commonly used in long-form content: <h1>, <p>, <a>, and <img>. In other words, it will be possible to include top-level headings, body text, linked text, and images. There will be no support for bulleted or ordered lists, tables, or any other elements for this particular tool.
The front-end implementation will rely on vanilla HTML, CSS, and JavaScript to establish a small form with a simple layout and functionality that converts the text to HTML. There is a server-side aspect to this if you plan on deploying it to a production environment, but our focus is purely on the front end.
Looking At Existing Solutions
There are existing ways to accomplish this. For example, some libraries offer a WYSIWYG editor. Import a library like TinyMCE with a single <script> and you’re good to go. WYSIWYG editors are powerful and support all kinds of formatting, even applying CSS classes to content for styling.
But TinyMCE isn’t the most efficient package at about 500 KB minified. That’s not a criticism as much as an indication of how much functionality it covers. We want something more “barebones” than that for our simple purpose. Searching GitHub surfaces more possibilities. The solutions, however, seem to fall into one of two categories:
The input accepts plain text, but the generated HTML only supports the HTML <h1> and <p> tags.
The input converts plain text into formatted HTML, but by ”plain text,” the tool seems to mean “Markdown” (or a variety of it) instead. The txt2html Perl module (from 1994!) would fall under this category.
Even if a perfect solution for what we want was already out there, I’d still want to pick apart the concept of converting text to HTML to understand how it works and hopefully learn something new in the process. So, let’s proceed with our own homespun solution.
Setting Up The HTML
We’ll start with the HTML structure for the input and output. For the input element, we’re probably best off using a <textarea>. For the output element and related styling, choices abound. The following is merely one example with some very basic CSS to place the input <textarea> on the left and an output <div> on the right:
You can further develop the CSS, but that isn’t the focus of this article. There is no question that the design can be prettier than what I am providing here!
Capture The Plain Text Input
We’ll set an onkeyup event handler on the <textarea> to call a JavaScript function called convert() that does what it says: convert the plain text into HTML. The conversion function should accept one parameter, a string, for the user’s plain text input entered into the <textarea> element:
onkeyup is a better choice than onkeydown in this case, as onkeyup will call the conversion function after the user completes each keystroke, as opposed to before it happens. This way, the output, which is refreshed with each keystroke, always includes the latest typed character. If the conversion is triggered with an onkeydown handler, the output will exclude the most recent character the user typed. This can be frustrating when, for example, the user has finished typing a sentence but cannot yet see the final punctuation mark, say a period (.), in the output until typing another character first. This creates the impression of a typo, glitch, or lag when there is none.
In JavaScript, the convert() function has the following responsibilities:
Encode the input in HTML.
Process the input line-by-line and wrap each individual line in either a <h1> or <p> HTML tag, whichever is most appropriate.
Process the output of the transformations as a single string, wrap URLs in HTML <a> tags, and replace image file names with <img> elements.
And from there, we display the output. We can create separate functions for each responsibility. Let’s name them accordingly:
html_encode()
convert_text_to_HTML()
convert_images_and_links_to_HTML()
Each function accepts one parameter, a string, and returns a string.
Encoding The Input Into HTML
Use the html_encode() function to HTML encode/sanitize the input. HTML encoding refers to the process of escaping or replacing certain characters in a string input to prevent users from inserting their own HTML into the output. At a minimum, we should replace the following characters:
< with <
> with >
& with &
' with '
" with "
JavaScript does not provide a built-in way to HTML encode input as other languages do. For example, PHP has htmlspecialchars(), htmlentities(), and strip_tags() functions. That said, it is relatively easy to write our own function that does this, which is what we’ll use the html_encode() function for that we defined earlier:
HTML encoding of the input is a critical security consideration. It prevents unwanted scripts or other HTML manipulations from getting injected into our work. Granted, front-end input sanitization and validation are both merely deterrents because bad actors can bypass them. But we may as well make them work a little harder.
As long as we are on the topic of securing our work, make sure to HTML-encode the input on the back end, where the user cannot interfere. At the same time, take care not to encode the input more than once. Encoding text that is already HTML-encoded will break the output functionality. The best approach for back-end storage is for the front end to pass the raw, unencoded input to the back end, then ask the back-end to HTML-encode the input before inserting it into a database.
That said, this only accounts for sanitizing and storing the input on the back end. We still have to display the encoded HTML output on the front end. There are at least two approaches to consider:
Convert the input to HTML after HTML-encoding it and before it is inserted into a database. This is efficient, as the input only needs to be converted once. However, this is also an inflexible approach, as updating the HTML becomes difficult if the output requirements happen to change in the future.
Store only the HTML-encoded input text in the database and dynamically convert it to HTML before displaying the output for each content request. This is less efficient, as the conversion will occur on each request. However, it is also more flexible since it’s possible to update how the input text is converted to HTML if requirements change.
Applying Semantic HTML Tags
Let’s use the convert_text_to_HTML() function we defined earlier to wrap each line in their respective HTML tags, which are going to be either <h1> or <p>. To determine which tag to use, we will split the text input on the newline character (\n) so that the text is processed as an array of lines rather than a single string, allowing us to evaluate them individually.
function convert_text_to_HTML(txt) {
// Output variable
let out = '';
// Split text at the newline character into an array
const txt_array = txt.split("\n");
// Get the number of lines in the array
const txt_array_length = txt_array.length;
// Variable to keep track of the (non-blank) line number
let non_blank_line_count = 0;
for (let i = 0; i < txt_array_length; i++) {
// Get the current line
const line = txt_array[i];
// Continue if a line contains no text characters
if (line === ''){
continue;
}
non_blank_line_count++;
// If a line is the first line that contains text
if (non_blank_line_count === 1){
// ...wrap the line of text in a Heading 1 tag
out += <h1>${line}</h1>;
// ...otherwise, wrap the line of text in a Paragraph tag.
} else {
out += <p>${line}</p>;
}
}
return out;
}
In short, this little snippet loops through the array of split text lines and ignores lines that do not contain any text characters. From there, we can evaluate whether a line is the first one in the series. If it is, we slap a <h1> tag on it; otherwise, we mark it up in a <p> tag.
This logic could be used to account for other types of elements that you may want to include in the output. For example, perhaps the second line is assumed to be a byline that names the author and links up to an archive of all author posts.
Tagging URLs And Images With Regular Expressions
Next, we’re going to create our convert_images_and_links_to_HTML() function to encode URLs and images as HTML elements. It’s a good chunk of code, so I’ll drop it in and we’ll immediately start picking it apart together to explain how it all works.
function convert_images_and_links_to_HTML(string){
let urls_unique = [];
let images_unique = [];
const urls = string.match(/https*:\/\/[^\s<),]+[^\s<),.]/gmi) ?? [];
const imgs = string.match(/[^"'>\s]+.(jpg|jpeg|gif|png|webp)/gmi) ?? [];
const urls_length = urls.length;
const images_length = imgs.length;
for (let i = 0; i < urls_length; i++){
const url = urls[i];
if (!urls_unique.includes(url)){
urls_unique.push(url);
}
}
for (let i = 0; i < images_length; i++){
const img = imgs[i];
if (!images_unique.includes(img)){
images_unique.push(img);
}
}
const urls_unique_length = urls_unique.length;
const images_unique_length = images_unique.length;
for (let i = 0; i < urls_unique_length; i++){
const url = urls_unique[i];
if (images_unique_length === 0 || !images_unique.includes(url)){
const a_tag = <a href="${url}" target="_blank">${url}</a>;
string = string.replace(url, a_tag);
}
}
for (let i = 0; i < images_unique_length; i++){
const img = images_unique[i];
const img_tag = <img src="${img}" alt="">;
const img_link = <a href="${img}">${img_tag}</a>;
string = string.replace(img, img_link);
}
return string;
}
Unlike the convert_text_to_HTML() function, here we use regular expressions to identify the terms that need to be wrapped and/or replaced with <a> or <img> tags. We do this for a couple of reasons:
The previous convert_text_to_HTML() function handles text that would be transformed to the HTML block-level elements <h1> and <p>, and, if you want, other block-level elements such as <address>. Block-level elements in the HTML output correspond to discrete lines of text in the input, which you can think of as paragraphs, the text entered between presses of the Enter key.
On the other hand, URLs in the text input are often included in the middle of a sentence rather than on a separate line. Images that occur in the input text are often included on a separate line, but not always. While you could identify text that represents URLs and images by processing the input line-by-line — or even word-by-word, if necessary — it is easier to use regular expressions and process the entire input as a single string rather than by individual lines.
Regular expressions, though they are powerful and the appropriate tool to use for this job, come with a performance cost, which is another reason to use each expression only once for the entire text input.
Remember: All the JavaScript in this example runs each time the user types a character, so it is important to keep things as lightweight and efficient as possible.
I also want to make a note about the variable names in our convert_images_and_links_to_HTML() function. images (plural), image (singular), and link are reserved words in JavaScript. Consequently, imgs, img, and a_tag were used for naming. Interestingly, these specific reserved words are not listed on the relevant MDN page, but they are on W3Schools.
We’re using the String.prototype.match() function for each of the two regular expressions, then storing the results for each call in an array. From there, we use the nullish coalescing operator (??) on each call so that, if no matches are found, the result will be an empty array. If we do not do this and no matches are found, the result of each match() call will be null and will cause problems downstream.
Next up, we filter the arrays of results so that each array contains only unique results. This is a critical step. If we don’t filter out duplicate results and the input text contains multiple instances of the same URL or image file name, then we break the HTML tags in the output. JavaScript does not provide a simple, built-in method to get unique items in an array that’s akin to the PHP array_unique() function.
The code snippet works around this limitation using an admittedly ugly but straightforward procedural approach. The same problem is solved using a more functional approach if you prefer. There are many articles on the web describing various ways to filter a JavaScript array in order to keep only the unique items.
We’re also checking if the URL is matched as an image before replacing a URL with an appropriate <a> tag and performing the replacement only if the URL doesn’t match an image. We may be able to avoid having to perform this check by using a more intricate regular expression. The example code deliberately uses regular expressions that are perhaps less precise but hopefully easier to understand in an effort to keep things as simple as possible.
And, finally, we’re replacing image file names in the input text with <img> tags that have the src attribute set to the image file name. For example, my_image.png in the input is transformed into <img src='my_image.png'> in the output. We wrap each <img> tag with an <a> tag that links to the image file and opens it in a new tab when clicked.
There are a couple of benefits to this approach:
In a real-world scenario, you will likely use a CSS rule to constrain the size of the rendered image. By making the images clickable, you provide users with a convenient way to view the full-size image.
If the image is not a local file but is instead a URL to an image from a third party, this is a way to implicitly provide attribution. Ideally, you should not rely solely on this method but, instead, provide explicit attribution underneath the image in a <figcaption>, <cite>, or similar element. But if, for whatever reason, you are unable to provide explicit attribution, you are at least providing a link to the image source.
It may go without saying, but “hotlinking” images is something to avoid. Use only locally hosted images wherever possible, and provide attribution if you do not hold the copyright for them.
Before we move on to displaying the converted output, let’s talk a bit about accessibility, specifically the image alt attribute. The example code I provided does add an alt attribute in the conversion but does not populate it with a value, as there is no easy way to automatically calculate what that value should be. An empty alt attribute can be acceptable if the image is considered “decorative,” i.e., purely supplementary to the surrounding text. But one may argue that there is no such thing as a purely decorative image.
That said, I consider this to be a limitation of what we’re building.
Displaying the Output HTML
We’re at the point where we can finally work on displaying the HTML-encoded output! We've already handled all the work of converting the text, so all we really need to do now is call it:
function convert(input_string) {
output.innerHTML = convert_images_and_links_to_HTML(convert_text_to_HTML(html_encode(input_string)));
}
If you would rather display the output string as raw HTML markup, use a <pre> tag as the output element instead of a <div>:
<pre id='output'></pre>
The only thing to note about this approach is that you would target the <pre> element’s textContent instead of innerHTML:
function convert(input_string) {
output.textContent = convert_images_and_links_to_HTML(convert_text_to_HTML(html_encode(input_string)));
}
Conclusion
We did it! We built one of the same sort of copy-paste tool that converts plain text on the spot. In this case, we’ve configured it so that plain text entered into a <textarea> is parsed line-by-line and encoded into HTML that we format and display inside another element.
We were even able to keep the solution fairly simple, i.e., vanilla HTML, CSS, and JavaScript, without reaching for a third-party library or framework. Does this simple solution do everything a ready-made tool like a framework can do? Absolutely not. But a solution as simple as this is often all you need: nothing more and nothing less.
As far as scaling this further, the code could be modified to POST what’s entered into the <form> using a PHP script or the like. That would be a great exercise, and if you do it, please share your work with me in the comments because I’d love to check it out.
There’s no doubt that code quality plays an important role in any team’s output. Whether you’re weeding out critical issues, improving your skills, or simply establishing standards as a team, it’s paramount to be on the same page when it comes to defining and executing high-quality projects. Having the right tools along the way can also be a huge help.
JetBrains Qodana is a powerful static code analysis platform that enables teams to analyze code quality and find issues before runtime. In this post, we’ll give an in-depth demonstration of how to analyze JavaScript code with Qodana, using a Keystone project as an example.
As you’ll see, this approach enabled us to identify “Critical” and “High-Severity” issues first and then explore any other issues that needed to be addressed. Let’s dive in!
Setup
To start, we used a custom qodana.yaml file, which you can find here: (via the Configuration tab).
In this instance, we used TeamCity to launch the analysis, but you can use whichever CI/CD tool you prefer. You also have the option to use the Qodana Plugin in WebStorm – where we viewed issues and corrected code at times. You’ll see some of this below.
Results
After getting set up, launching, and waiting briefly for the analysis to finish, we examined our results. Let’s take a look at the results of this project, from most to least critical.
In most cases, we ignore problems in generated files and suggest excluding these files from the analysis. Let’s take a look at the most critical issues first.
Critical Issues
Qodana found two issues with “Critical” severity. Both of these were incorrect CSS property names. Take a look here.
It’s possible that the authors wanted to use a CSS property text-decoration-skip-ink, but something went wrong. Luckily, this particular instance has turned out not to be critical, because it only affects underlined text on the error and loading pages, but this won’t always be the case.
Sometimes, problems like these could break the layout of the page. Just imagine if you had typed something like display: plex instead of display: flex in CSS styles for the root container of your layout. This could easily crash your site layout.
In this case, the issue turned out to be an easy fix. Qodana highlighted it, and all we had to do was use the correct property name:
text-decoration-skip-ink: auto;
High-severity issues
In this example, there are a lot of “High-severity” issues. Let’s take a closer look at them:
Comma expression
In this case, we’re using WebStorm (The JavaScript and TypeScript IDE by JetBrains) with Qodana.
Qodana says:
“Reports a comma expression. Such expressions are often a sign of overly clever code and may lead to subtle bugs. Comma expressions in the initializer or in the update section of for loops are ignored”.
You can view the result here. This is a real mistake where the author typed a comma instead of a period.
Due to this typo, we won’t see this message the next time prepare-release.js is called:
…because we will get an error, such as Uncaught ReferenceError: push is not defined.
Again, this is an easy fix. We just have to change the comma to a period. Let’s do that immediately.
Unused global symbol
We identified multiple “Unused global symbol” issues. Sometimes, issues like these mean we removed a chunk of code but forgot about interfaces, public class props, etc., that were only used in that chunk of code. These issues can occasionally be false positives, but you should always look into them just to be on the safe side.
For example, let’s say you’re writing the code for the documentation interface. You define headings for H1 to H6 but then only use H1 to H3. In this case, you will get “Unused global symbol” issues, because Qodana can’t find evidence of other heading levels. It’s up to you whether you want to delete the unused headings to make your code clearer or whether you choose to keep it. Both options are fine, but a decision needs to be made.
Unused local symbol
An unused local symbol is much easier to address. This type of issue indicates that you have declared but not used a local variable. In our analysis of these problems, all of them relate to unused function args. You can just remove these unused args or use _arg notation (of course, only if your linter allows it).
Function with inconsistent returns
This is a bit of a tricky one. An issue like this doesn’t always indicate an error in your code. Sometimes, it’s more about clarity and simplicity. But sometimes, it can lead to unexpected and unclear errors.
Of course, from time to time, we use return to simplify code or to return earlier from our function without additional constructions. Regardless, you need to be prepared to deal with scenarios like this, especially when you use these functions in other places.
How do we fix it? Usually, you can rewrite your code to avoid this problem. See the example below:
dir
.filter(x => x !== '.next')
.map(x => {
return fs.rm(Path.join(projectAdminPath, x), { recursive: true })
})
In some cases, this issue isn’t important, and you may opt not to make any changes to your code. Qodana can highlight these potential issues in your code, but you need to examine the result and decide whether to fix it or not.
Overwritten property
There were a few “Overwritten property” problems highlighted. These can crop up either because CSS properties have literally been overwritten or because some properties have merely been duplicated. Ignoring them can lead to unexpected UI style bugs.
Reserved word used as name
We have three problems here, all of which are caused by using the reserved word enum as a variable name. In most cases, the code still works perfectly, but some keywords can cause errors. Some developers prefer to avoid situations like this because, at the very least, it will affect code highlighting in the IDE.
Unused assignment
In the project we analyzed, Qodana reports this issue in three scenarios:
1. When we try to use a variable before initialization, as was done here. The code in the example will work normally because we have an undefined value included in the array, and in JS, a construction like [].includes(undefined) generally works like a charm. But in other cases using a variable before initialization can cause bugs.
2. Redundant variable initialization, as can be seen here. Language services or static analysis tools can control the variable initialization flow and report an error when you try to use an uninitialized variable (like in p.1). But in this case, it’s mostly about code style. Some developers prefer initialization variables with a default value like let str = ''
If we want to secure a variable type for TS typings, we can use:
let str: string;
if (condition) {
str = 'a';
} else {
str = 'b';
}
3. Redundant value assignment to a variable, as seen here. In this code, we try to get a person. If we’re unsuccessful ( if (!person) ), we try to create one. And here we assign a value to a variable but don’t use this variable anymore.
Exception used for local control-flow
This is an interesting one. In this code, we throw an error in the try block that will always be caught in the catch block.
There’s actually something of a heated debate about this – some people think it’s an anti-pattern (or at least a code smell), but other people just use it with no qualms.
Some developers in our team prefer this way (the article is for C# but works perfectly with other languages) when working with exceptions but still allow themselves to “misbehave”, as in our example.
Single character alternation
Here, we have the same issue in different files. In this code, the following regular expression is used:
<strong>/(>|<)/gi</strong>
What does it mean? We just want to find > or < . Regular expressions have character classes to help us with this, and we can simply rewrite this RegExp (exactly as Qodana suggests).
<strong>/[><]/gi</strong>
This is more readable and should be faster (there may be some fluctuations with different regular expression engines).
Redundant local variable
Here we see cases like this – issues that can be discussed and debated. In this case, it’s mostly about code style. However, we’ve used it both ways – with a redundant variable and without. This is why: If you need to debug code often, creating a variable can be more convenient because it’s easier to work with it in the debugger. In other cases, it’s not as important. Ultimately, it’s up to you and your team.
Unsound type guard check
This is a tricky issue. Here’s a simplified version of the code that will generate this warning:
const func = (value: number) => {
if (typeof value !== "number") {
throw new Error("Oh, no");
}
// do smth
...
}
From the TS point of view, this if statement doesn’t make sense because you can constrain the type for the function arg value – the value can have only the number type, and you can remove this statement to reduce the amount of code. Less code, fewer bugs. Of course, the arg type cannot protect us from something like func(”string” as any), but that’s truly evil, don’t do that.
What if somebody uses your TS code inside a JS codebase? They don’t have type checking, and this kind of if statement can help prevent bugs.
In other words, the decision about this issue should take into account how the code will be used in the future.
Moderate-severity issues
Now let’s look at “Moderate-severity” issues:
Deprecated symbol used
We have about 80 issues like this in the report. In general, these aren’t urgent and don’t need to be fixed right away. But from time to time, we need to deal with them to avoid problems when we want to upgrade the dependencies they affect.
Usually, these are easy to fix, especially if your dependency code has good JSDoc comments like:
Of course, sometimes you need to rewrite a bit of your code when changing deprecation usages.
This is another situation where Qodana can help you highlight points where changes are needed and estimate the time you will need to upgrade your code.
Duplicates
Every team has its own tolerance level for duplicate code. Sometimes, duplicate code is okay, but other times, it needs to be addressed, depending on team standards.
Redundant ‘await’ expression
In these cases, we wait for a non-promise result. Something like:
In cases like these, we can omit <string> as a solution because it equals the default value.
Expression statement which is not assignment or call
This is the only issue in this category – but it’s a bug. Nothing serious, but important to consider nonetheless. For some reason, this orphaned header ended up alone and didn’t make it into the return block. Let’s fix this!
export default function Index ({ authors }: { authors: Author[] }) {
return (
<>
<h1>Keystone Blog Project - Home</h1>
<ul>
// ... other code
From here, we create a PR again and keep going until we’re happy with our progress.
All told, our Qodana analysis helped us identify issues by severity and address them step by step. Your team can do the same on projects with various license types.
Do you want to try running Qodana analysis for yourself?
If you have any questions or need assistance, submit a ticket to our issue tracker in YouTrack by clicking on New Issue in the top right-hand corner of the screen or let us know in the comments. You can also tag us on Twitter or contact us at qodana-support@jetbrains.com. We’re always here to help you get set up.