In episode 71 of The AI Fix, a giant robot spider goes backpacking for a year before starting its job in lunar construction, DoorDash builds a delivery Minion, and a TikToker punishes an AI by making it talk to condiments. GPT-5 crushes the humans at the ICPC World Finals, Claude Sonnet 4.5 codes for 30 hours straight, and someone builds a 5-million-parameter transformer entirely inside Minecraft.
Plus: Graham investigates how a simple security flaw left fleets of Unitree robots wide open to hackers, and Mark learns that we’re going to need five nuclear power plants to train just one frontier model by 2028.
Homebrew’s project lead Mike McQuaid joins Abby and Andrea to unpack what it really takes to sustain one of the most-used developer tools on macOS and Linux. From early GitHub workflows to today’s automation and guardrails, Mike details the soft-power leadership that keeps volunteers motivated, and shares insights on how to scale contributions, keep a small maintainer team effective, and triage with empathy (and boundaries). This episode covers governance, “saying no,” using AI responsibly, and how IRL feedback at Universe turned into performance wins.
Nearly two decades ago, my curiosity about ASP.NET sparked something bigger than just learning a framework. I started writing technical articles, not just to document what I was learning, but because I wanted to make the path smoother for developers coming after me. To my surprise, some of those articles became the most-read in their categories.
That success pushed me to take a bigger leap. I founded DotNetSlackers, one of the earliest community hubs for .NET, built in ASP.NET 1.0 with MS SQLServer as the backend and dozens of SSIS packages to automate SQL jobs. The site ultimately reached more than 33 million views and hosted contributions from over 100 authors. For many developers, it became their first doorway into ASP.NET and modern web practices. I eventually retired the platform after more than a decade of activity, and I am no longer affiliated with the domain that exists today, but its legacy remains part of the shared history of the .NET community.
This commitment to community earned me recognition as a Microsoft MVP for ASP.NET in 2005, a distinction I proudly held for several consecutive years. More than the award itself, it symbolized that my contributions were making a global impact through mentorship, writing, and building spaces where developers could thrive.
Growing Through Enterprise Experience
As my career advanced, I carried that same mindset into the enterprise world. At Citigroup, Cisco, Sony, and American Apparel, I wasn’t just building systems; I was solving problems that impacted thousands of users and billions of dollars in transactions. From global trading platforms for bonds and swaps to RFID-enabled enterprise retail systems, my “why” was about reliability and trust: creating mission-critical software people could depend on just as developers depended on the knowledge I shared through community work.
Coming Full Circle
In 2024, more than a decade after my first MVP, I was re-awarded the MVP in Developer Technologies this time for my work with Angular and AI-powered applications. By then, my “why” had expanded. It wasn’t just about teaching anymore; it was about shaping the tools themselves.
I helped co-author Angular’s Typed Forms (the most upvoted feature request in Angular history), authored multiple books, including AI-Powered App Development, Beginning JavaScript Syntax, and Practical Angular Signals. I have also joined the ranks of both Google Developer Experts (GDE) and the exclusive Angular Collaborators program (one of only 11 worldwide). Besides that, I became the core maintainer of ngx-layout, an open-source Angular library that now receives over 25,000 weekly downloads, helping developers across the globe structure applications more effectively.
Why keep pushing forward? Because the ecosystem is bigger than any one of us. If I can influence a framework used by millions, or an open-source project relied on by tens of thousands each week, I can multiply my impact in ways I never imagined back when I was writing my first ASP.NET articles.
A Legacy of Mentorship and Innovation
Today, I continue to balance writing, mentoring, and enterprise engineering while also speaking at international conferences to share what I’ve learned with the wider community. I’ve seen firsthand that a single article, a single community, or a single open-source feature can change the course of someone’s career.
My journey from creating DotNetSlackers to contributing to Angular is not just about recognition. It’s about building a culture of sharing, mentorship, and innovation that will outlast me.
The MVP award has been an incredible honour, but I’ve always seen it as a milestone in a much larger journey of lifting others and shaping the future of technology.
Want to join Sonu and others to make a difference?
Nominate someone, share your journey, or encourage the next generation of innovators to join the MVP community. Learn more about the MVP Program on the MVP Communities site. Follow us on social media on X and LinkedIn.
We’d like to inform you about an update to how inline images are represented in the HTML body of Outlook emails in Outlook on the web and the new Outlook for Windows. This change may impact how your add-in identifies and processes inline images when using the attachment ID.
What’s changing?
Previously, inline images in the HTML mail body were represented with a URL containing the attachment ID as a query parameter. The following is an example of an inline image represented in HTML code.
<img src="https://attachments-sdf.office.net/owa/arpitsangwan%40microsoft.com/service.svc/s/GetAttachmentThumbnail?id=AAkALgAAAAAAHYQDEapmEc2byACqAC%2FEWg0AW4xUByFbp0CroCNphMYEEAADMWhyiwAAARIAEAA3P0Tub6RfQaxOX%2Fjz3FlX &thumbnailType=2&token=XYZ… style="max-width: 1281px;" originalsrc="cid:ee058cc2-ad96-485f-95c7-44b2f40cb987" size="19720" contenttype="image/png >
Developers could parse the HTML and do one of the following.
Extract the ID from the URL and match it with the attachment ID they already had.
Use the entire URL in the src attribute to get the Base64 value of the inline image.
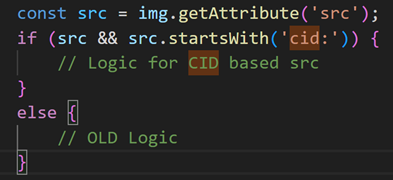
Going forward, the URL for inline images will no longer contain the attachment ID. Instead, the image will be represented by a content ID (cid) in the src attribute. As a result, your current parsing logic won’t be able to correlate the inline image in the mail body with the attachment ID or Base64 value of the image.
The following sample shows the updated representation of inline images in HTML code.
This update applies to Outlook on the web and the new Outlook on Windows. Other Outlook platforms will continue to operate as they do today.
Why is it changing?
As part of our ongoing security efforts, we’re updating how inline images are loaded. Previously, images were retrieved via a GET request with the token embedded in the URL. We’re transitioning to a fetch call that includes the token in the request header. This change could impact you if you do one of the following to identify where the inline image appears in the message body.
Parse the attachment ID from the HTML editor.
Get the Base64 value of the image using the URL in the src attribute.
Solution
To restore inline image correlation, we’re introducing the content ID that represents the image in the src attribute of the corresponding <img> element. Placing the content ID in the src attribute matches how classic Outlook on Windows represents inline images.
Action required
Update your parsing logic
Instead of extracting the attachment ID from the URL, parse the HTML message body and retrieve the cid value from the src attribute of the applicable <img> element. Then, call Office.context.mailbox.item.getAttachmentsAsync. The getAttachmentsAsync method returns an AttachmentDetailsCompose object that contains the content ID property to help identify and match images. The following is a sample AttachmentDetailsCompose object.
To ensure your add-in continues to correctly correlate inline images during the rollout of these changes, we recommend that your add-in handle both previous and updated implementations. The following code is an example.
Test your add-in
Ensure your add-in correctly identifies and processes inline images using the updated src attribute.
Timeline
Starting November 15, 2025, the updated inline image representation will begin rolling out to production users. Please make the necessary changes before then to avoid regressions to your add-in experience.
This incredible growth is thanks to the thousands of educators, companies, and projects that have contributed to the development of React. The community is the heart of React, and we’re proud to play a part in the cycle of open source innovation throughout the ecosystem that benefits everyone. We’re pleased to give a seat at the table to the people and companies that have made React what it is today.
Today, we are excited to announce the next step for React. Several projects within the React ecosystem, including React and React Native, as well as supporting projects such as JSX, will transition to the React Foundation. The React Foundation’s mission is to help the React community and its members. The React Foundation will maintain React’s infrastructure, organizeReact Conf, and create initiatives to support the React ecosystem. The React Foundation will be part of the Linux Foundation, which has long fostered a vendor-neutral environment for open source projects.
Formalizing Governance
The React Foundation’s governing board will consist of representatives from Amazon, Callstack, Expo, Meta, Microsoft, Software Mansion, and Vercel, with the intention to expand further over time.
There will be a clear separation between the business and technical governance of React. Releases, features, and technical direction will be governed by a new structure driven by the maintainers and contributors of React. This new technical governance structure will be independent of the React Foundation. The React team is actively working on this new technical governance structure and will share more details in a future post on the React blog.
Meta and the React Foundation
Meta is committing to a five-year partnership with the React Foundation, including over $3 million in funding and dedicated engineering support. This investment will ensure React’s smooth transition to independent governance while maintaining the stability and innovation the community expects. Meta will continue to invest in React and use it as our primary tool for building UI on the web and across many of Meta’s apps. Meta will also continue to have a dedicated team of engineers working full-time on React and React Native.
We believe the best of React is yet to come. The React Foundation will unlock new opportunities for collaboration, innovation, and growth that will benefit the entire ecosystem. We’re excited to see what the community will build together under this new model. With strengthened governance, broader industry participation, and continued technical excellence, React is positioned to tackle the next generation of challenges in UI development.
It’s mid 2023 and we’ve identified some opportunities to improve our reliability. Fast forward to January 2025. Customer impact hours are reduced from the peak by 90% and continuing to trend downward. We’re a year and half into the Deploy Safety Program at Slack, improving the way we deploy, uplifting our safety culture and continuing our rate of change to meet business needs.
Defining the problem
System requirements change as businesses evolve whether that be due to changes in customer expectations, load & scale or response to business needs.
In this case analysis showed two critical trends:
Slack has become more mission critical for our customers, increasing expectations of reliability for the product as a whole and for specific features each company relies on.
The increasing majority (73%) of customer facing incidents were triggered by Slack-induced change, particularly code deploys.
We use our incident management process heavily and frequently at Slack to ensure we have a strong and rapid response to issues of all shapes and sizes based on impact and severity. A portion of those incidents are customer impacting, many of which showed variable impact depending on which features they used in the product. Change-triggered incidents were occurring in a wide variety of systems and deployment processes.
Finally, we also received customer feedback that interruptions became more disruptive after about 10 minutes – something they would treat as a “blip” – and this would continue to reduce with the introduction of Agentforce in 2025.
All this was occurring in a software engineering environment with 100s of internal services and many different deployment systems & practices.
In the past, our approach to reliability often zeroed in on individual deploy systems or services. This led to manual change processes that bogged down our pace of innovation. The increased time and effort required for changes not only dampened engineering morale but also hindered our ability to swiftly meet business objectives.
This led us to set some initial “North Star” goals across all deployment methods for our highest importance services:
Reducing impact time from deployments
Automated detection & remediation within 10 minutes
Manual detection & remediation within 20 minutes
Reducing severity of impact
Detect problematic deployments prior to reaching 10% of the fleet
Maintaining Slack’s development velocity
The initial North Star goals evolved and expanded into a Deploy Safety Manifesto that now applies to all Slack’s deployment systems & processes.
These goals encourage implementing automated system improvements, safety guardrails and cultural changes.
The metric
Programs are run to invoke change and change must be measured. Selecting a metric that serves as an imperfect analog has continued to be a constant source of discussion.
The North Star goals could be measured against engineering efforts, but were not a direct measure of the end goal: improving customer sentiment of their experience of Slack’s reliability. What we needed was a metric that was a reasonable (though imperfect) analog of customer sentiment. We had the internal data to design such a metric.
The Deploy Safety metric:
Hours of customer impact from high severity and selected medium severity change-triggered incidents.
What does “selected” mean? That seems pretty ambiguous. We found that the incident dataset didn’t exactly match what we needed. Severity levels at Slack convey current or impending customer impact rather than the final impact which often requires careful post-hoc analysis. This means we need to filter medium severity incidents based on a relevant level of customer impact.
The on-going discussion around what metric to use relates to the semi-loose connection between:
Customer sentiment <-> Program Metric <-> Project Metric
They’re all connected, but it’s challenging to know for a specific project how much it is going to move the top line metric. How much does the Program metric reflect individual customer experience? This flow is especially difficult for engineers who prefer a more concrete feedback loop with hard data – i.e., “How much does my work or concept change customer sentiment?”
Important criteria for designing the Deploy Safety metric:
Measure results
Understand what is measured (real vs analog)
Consistency in measurement, especially subjective portions
Continually validate the measurement matches customer sentiment with the leaders having the direct conversations with customers
Which projects to invest in?
The two largest unknowns we had at the start of the program were predicting which projects would have the highest likelihood of success given multiple sources of incidents and when each project would deliver impact. Incident data is a trailing dataset meaning that there is a time delay before we know the result. On top of this, customers were experiencing pain right now.
This influenced our investment strategy to be:
Invest widely initially and bias for action
Focus on areas of known pain first
Invest further in projects or patterns based on results
Curtail investment in the least impactful areas
Set a flexible shorter-term roadmap which may change based on results.
Our goals directed us to look for projects that would therefore influence one or more the following:
Detection of an issue earlier in the deployment process
Improved automatic remediation time
Improved manual remediation time
Reduced issue severity through design of isolation boundaries (blast radius control)
We attributed Webapp backend as the largest source of change-triggered incidents. The following is an example investment flow to address our Webapp backend deployments.
A quarter of work to engineer automatic metric monitoring
Another quarter to confirm customer impact alignment via automatic alerts and manual rollback actions
Proving success with many automatic rollbacks keeping customer impact below 10 minutes
Further investment to monitor additional metrics and invest in manual rollback optimisations
Investing in a manual Frontend rollback capability
Aligned further investment toward Slack’s centralised deployment orchestration system inspired by ReleaseBot and the AWS Pipelines deployment system to unify the use of metrics-based deployments with automatic remediation beyond Slack Bedrock / Kubernetes to many other deployment systems
Achieved success criteria: Webapp backend, frontend, and a portion of infra deployments are now significantly safer and showing continual improvement quarter-over-quarter
This pattern of trying something, finding success, then iterating + copying the pattern to other systems continues to serve us well.
There have been too many projects to list, some more successful (e.g., faster Mobile App issue detection) and others where the impact hasn’t been as noticeable. In some cases we had reduced impact due to the greater success of automation over manual remediation improvements. It’s very important to note that projects that didn’t have the desired impact are not failures, they’re a critical input to our success through guiding investment and understanding which areas are of greater value. Not all projects will be as impactful, and this is by design.
Results
Customer impact by quarter vs progressive targets
Please note: our internal metric tracking of “impact” is much more granular and sensitive than disruptions that might qualify for the Slack Status Site.
The bar chart above tells quite a story of non-linear progress and the difficulties with using trailing metrics based on waiting for incident occurrence.
After the first quarter of work we had already seen improvement, but hadn’t yet deployed any changes other than communicating with the engineering teams about the program. Once projects started to deliver changes, we then had the peak quarter of impact between February and April of 2024. Was this working?
There was still confidence that the work we were doing was going to have the desired impact based on the early results from Webapp backend metrics based deploy alerts with manual remediation – the peak of impact in 2024 would have otherwise been even higher. What we needed was automatic instead of manual remediation. Once automatic rollbacks were introduced we observed dramatic improvement in results. We’ve continued to experience a 3-6 month lag time to observe each project’s full impact.
Over time the target number has been continually adjusted. Due to the metric requiring trailing incident data, the target was set based on expected potential results through the work delivered the previous quarter. This was notably different from expecting to be able to measure results as soon as work is delivered.
We’ve reduced our target number again for 2025 and expect lower customer impact with a focus on mitigating the risk of infrequent spikes through deployment system consistency.
Lessons learned
This program required continual learning and iteration. We learned many important lessons. Each were critical for a successful program:
Ensuring prioritisation and alignment
Executive reviews every 4-6 weeks to ensure continued alignment and to seek support where needed
High-level priority in company/engineering goals (OKR, V2MOM etc.)
Solid support from executive leadership with active project alignment, encouragement, and customer feedback (huge thanks to SVP Milena Talavera, SVP Peter Secor, and VP Cisco Vila)
Patience with trailing metrics and faith that you have the right process even when some projects don’t succeed
Using a measurement with multiple months of delay from work delivery will need patience.
Gather metrics to know if the improvement is at least functioning well (e.g., issue detection) whilst waiting for full results.
Faith that you’ve made the best decisions you can with the information you have at the time and the agility to change the path once results are confirmed.
Folks will delay adoption of a practice until they’re familiar or comfortable with it
They’re worried they’ll make the problem worse if they follow an unknown path even with the reassurance it is better and is recommended.
Provide direct training (multiple times if necessary) to many groups to help them become comfortable with the new tooling – “Just roll back!”
Continual improvement of manual rollback tooling in response to experience during incidents.
Use the tooling often, not just for the infrequent worst case scenarios. Incidents are stressful and we found that without frequent use to build fluency, confidence, and comfort the processes and tools won’t become routine. It would be as if you didn’t build the tool/capability in the first place.
Direct outreach to engineering teams is critical
The Deploy Safety program team engaged directly with individual teams to understand their systems and processes, provide improvement guidance, and encourage innovation and prioritization. (A huge thanks to Petr Pchelko & Harrison Page for so much of this work.)
Not all teams and systems are the same. Some teams know their areas of pain well and have ideas, others want to improve but need additional resources.
Keep the top line metric as consistent as possible
Pick a metric, be consistent, and make refinements based on validation of results
It’s very easy to burn time on deliberating the best metric (there isn’t a perfect one)
Maintain consistent, direct communication with engineering staff
This is an area we’re working to improve on
Management understood prioritisation and results and were well aligned as a group. However, it hasn’t always been clear to general engineering staff revealing an opportunity for better alignment.
Into the future
Trust is the #1 value for Salesforce and Slack. As reliability is a key portion of that trust we intend to have ongoing investment into Deploy Safety at Slack.
Improvements in automatic metrics based deployments & remediation to keep the positive trend going
More consistency in our use of Deploy Safe processes for all deployments at Slack to mitigate unexpected or infrequent spikes of customer impact
Change of the program’s scope to include migrating remaining manual deploy processes to code-based deploys using Deploy Safe processes
Examples of some of the ongoing projects in this space include:
Centralised deployment orchestration tooling expansion into other infrastructure deployment patterns: EC2, Terraform and many more
Automatic rollbacks for Frontend
Metric quality improvements – do we have the right metrics for each system/service?
AI metric-based anomaly detection
Further rollout of AI generated pre-production tests
Acknowledgements
Many thanks to all the Deploy Safety team over this first year and a half: Dave Harrington, Sam Bailey, Sreedevi Rai, Petr Pchelko, Harrison Page, Vani Anantha, Matt Jennings, Nathan Steele, Sriganesh Krishnan.
And a huge huge thanks to the too many to name teams that have picked up Deploy Safety projects large and small to improve the product experience for our customers.