 The latest episode of the Google AI: Release Notes podcast focuses on how Gemini was built from the ground up as a multimodal model — meaning a model that works with tex…
The latest episode of the Google AI: Release Notes podcast focuses on how Gemini was built from the ground up as a multimodal model — meaning a model that works with tex…

|
Sr. Content Developer at Microsoft, working remotely in PA, TechBash conference organizer, former Microsoft MVP, Husband, Dad and Geek.
|
The latest episode of the Google AI: Release Notes podcast focuses on how Gemini was built from the ground up as a multimodal model — meaning a model that works with tex…

Pennsylvania, USA


Being able to read others’ code is essential for maintaining, improving and collaborating on any meaningful software project. It’s rare to write all the original code in an application yourself, and even rarer for an application to be completely rewritten from scratch. More likely, your workflow will involve working with code that was written by someone else (who may no longer be available to explain it) and iterated on by others (who also might be out of reach) long before it ever appears on your screen.
This makes reading and understanding existing code just as important as writing it yourself. Without knowing what’s going on, line by line, character by character, you won’t be able to debug, enhance features, evolve a product or collaborate effectively with anyone. Sometimes the code is neat, organized and well-documented. Sometimes less so. Your ability to make sense of it shouldn’t depend on how polished it is.
In this tutorial, we’ll walk through a small application with unclear naming. Using a checklist as our guide, we’ll take it step by step to decode what’s going on.
The file below is called script.py:
View the code on Gist.
This file is data.json:
View the code on Gist.
We’ll Use a 5-Step Checklist To Identify What This Code Is Doing
Item 1: What Does the Program Do Overall?
Uncovering the program’s big-picture purpose provides the blueprint to understanding its details.
A good place to start is by looking for its main function and seeing how the other functions interact with it. In our example, runner() is the main function. We can tell it’s the main function because it calls f1, f2 and f3, respectively.
View the code on Gist.
In runner(), we can interpret the following workflow:
- f1(‘data.json’) is the very first thing that happens.
- f2(data) processes the data returned by f1.
- f3(grouped) processes the result of f2.
- Finally, it loops over stats.items() and prints something formatted like a number ({v:.2f}).
We can also make the reasonable conclusion that:
f1 loads data (we can tell this by json.load()).
View the code on Gist.
f2 groups or reorganizes it using defaultdict(list) and append(i) per category.
View the code on Gist.
f3 computes numeric summaries or aggregates using sum(...) and dividing by len(v).
View the code on Gist.
The loop prints results:
View the code on Gist.
We’re ready to answer the next question…
Item 2: How Is the Code Organized?
Understanding the structure tells you where to look for each piece of logic.
A great starting point for understanding how code is organized is to look for imports, functions and entry points.
The top of the file identifies imports:
View the code on Gist.
This means our script is using functionality from other modules. Through understanding the imports, you can anticipate data types or methods used in the code.
You can identify functions by looking for lines that start with def. Breaking the code into functions helps you read and understand one piece at a time.
You can identify the entry point in this special block near the bottom of the script:
View the code on Gist.
Understanding where the program begins helps you trace the flow from start to finish. This means when you run the script directly (python script.py), Python runs the code inside this block. The function or code called here (runner() in this case) is the starting point of execution.
In our example, the script imports json and defaultdict, so you can expect it to handle JSON data and perform grouping operations. It defines the functions f1, f2, f3 and runner(). Building off of what we learned in the last section, this suggests the code is organized into modular tasks such as file reading, data processing and running the main logic.
The entry point calls runner(), indicating that this function is the main routine coordinating the program’s execution.
Item 3: What Are the Main Inputs and Outputs?
Understanding what goes into the program (input) and what comes out (output) helps you mentally frame what the script is doing at a high level.
Here’s how to find the inputs.
Look at the first function called in runner(): data = f1(‘data.json’). This tells us the following:
- The script reads from a file called
data.json. - If we peek inside
f1(), we see it usesjson.load(f), which confirms the input is a JSON-formatted file. - The actual contents (in
data.json) are a list of dictionaries, each with acategoryand avaluefield. - This structured input is parsed into a Python list of dictionaries, each dictionary representing a single data point.
Here’s how to find the outputs.
This loop is at the end of runner():
View the code on Gist.
The loop prints each key (likely a category name) and a floating-point number with two decimal places. Based on the earlier functions, we can infer that this is the average value for each category.
Example output from this loop:
View the code on Gist.
This confirms the script is summarizing values by category and printing the results.
From all these details, we can understand the inputs and outputs. The main input is a JSON file containing a list of items, each with a category and a value. The output is plain text printed to the console (specifically, a summary showing the average value for each category).
Item 4: How Does Data Flow Through Functions?
Tracing how data moves and changes step by step is one of the most important ways to understand what code does. It helps you see not just what each function does in isolation, but how they work together to transform input into output.
Let’s follow the data through each function in the order it’s called.
f1('data.json')
The input is data.json
The function opens the file called data.json in read mode. It uses json.load() to parse the contents. The result is returned as a list of dictionaries like this (json.load() always outputs dictionaries and lists).
Output:
View the code on Gist.
This then becomes the input for f2.
f2(items)
This function creates an empty defaultdict with lists as the default value. It loops over every dictionary in the list returned by f1. It looks up the ’category’ key for each item. If no category exists, it returns ’Unknown’. It then appends the entire dictionary to the corresponding category’s list.
Output:
View the code on Gist.
This data becomes the input for f3.
f3(d)
This function takes the grouped dictionary from f2. It creates an empty dictionary called out. In each key-value pair, k is the category and v is the list of items in that category.
It computes the following:
s = sum(x['value'] for x in v): The total of allvaluefieldsm = s / len(v): The average
It stores the average in out[k].
Output:
View the code on Gist.
It becomes the variable stats in runner(), which is then printed.
runner()
runner() calls f1, f2 and f3 in their proper sequence. It receives the final dictionary of averages. It then loops over stats.items() and prints each category and its average, formatted to 2 decimal places.
Output:
View the code on Gist.
What does this mean?
Following the data through each function shows you the progressive transformation:
The raw JSON list becomes grouped by category, which becomes averaged per category, and is finally printed as summaries.
To work through this on your own and see what any function returns, add print() statements after each call:
View the code on Gist.
Item 5: Run the Code and See What Happens
Running the script is the quickest way to validate your mental model of what the code is doing. You can do this step really at any time in this process. Running the code also helps you catch missing files, date format problems and all other unexpected errors.
How to run this file:
- Make sure you saved your script as
script.py. - Make sure your
data.jsonfile is in the same folder asscript.py. - Open your terminal or command prompt.
- Navigate to the folder containing both files.
- Run:
python script.py.
Actual output:
View the code on Gist.
When the expected output matches the actual output, it confirms that you don’t have any errors and your environment is set up correctly. It also confirms you have the correct understanding of what the code is doing.
Helpful Tips
Here are some things you can do in addition to the checklist to aid in your understanding of code:
- Use tools to inspect variables. Inspecting variables lets you see exactly what’s in memory.
- Make notes and diagrams based on the code. Notes and diagrams help you keep track of relationships between data structures.
- Learn which libraries are being used. Understanding libraries helps you know what helpers are available.
And finally: Be patient! Even experienced developers take time to decode unclear names.
Conclusion
Reading someone else’s Python code, especially when names are unclear, can be challenging, especially at first. But by breaking it down step by step, you can turn confusing scripts into something you fully understand.
The post Decode Any Python Code With This 5-Step Method appeared first on The New Stack.
Pennsylvania, USA

Generative AI presents a unique challenge and opportunity to reexamine governance practices for the responsible development, deployment, and use of AI. To advance thinking in this space, Microsoft has tapped into the experience and knowledge of experts across domains—from genome editing to cybersecurity—to investigate the role of testing and evaluation as a governance tool. AI Testing and Evaluation: Learnings from Science and Industry, hosted by Microsoft Research’s Kathleen Sullivan, explores what the technology industry and policymakers can learn from these fields and how that might help shape the course of AI development.
In this episode, Daniel Carpenter, the Allie S. Freed Professor of Government and chair of the department of government at Harvard University, explains how the US Food and Drug Administration’s rigorous, multi-phase drug approval process serves as a gatekeeper that builds public trust and scientific credibility, while Timo Minssen, professor of law and founding director of the Center for Advanced Studies in Bioscience Innovation Law at the University of Copenhagen, explores the evolving regulatory landscape of medical devices with a focus on the challenges of balancing innovation with public safety. Later, Microsoft’s Chad Atalla, an applied scientist in responsible AI, discusses the sociotechnical nature of AI models and systems, their team’s work building an evaluation framework inspired by social science, and where AI researchers, developers, and policymakers might find inspiration from the approach to governance and testing in pharmaceuticals and medical devices.
Learn more:
Learning from other Domains to Advance AI Evaluation and Testing: The History and Evolution of Testing in Pharmaceutical Regulation
Case study | January 2025
Learning from other Domains to Advance AI Evaluation and Testing: Medical Device Testing: Regulatory Requirements, Evolution and Lessons for AI Governance
Case study | January 2025
Learning from other domains to advance AI evaluation and testing
Microsoft Research Blog | June 2025
Evaluating Generative AI Systems is a Social Science Measurement Challenge
Publication | November 2024
STAC: Sociotechnical Alignment Center
Responsible AI: Ethical policies and practices | Microsoft AI
Subscribe to the Microsoft Research Podcast:
Transcript
[MUSIC]
KATHLEEN SULLIVAN: Welcome to AI Testing and Evaluation: Learnings from Science and Industry. I’m your host, Kathleen Sullivan.
As generative AI continues to advance, Microsoft has gathered a range of experts—from genome editing to cybersecurity—to share how their fields approach evaluation and risk assessment. Our goal is to learn from their successes and their stumbles to move the science and practice of AI testing forward. In this series, we’ll explore how these insights might help guide the future of AI development, deployment, and responsible use.
[MUSIC ENDS]
SULLIVAN: Today, I’m excited to welcome Dan Carpenter and Timo Minssen to the podcast to explore testing and risk assessment in the areas of pharmaceuticals and medical devices, respectively.
Dan Carpenter is chair of the Department of Government at Harvard University. His research spans the sphere of social and political science, from petitioning in democratic society to regulation and government organizations. His recent work includes the FDA Project, which examines pharmaceutical regulation in the United States.
Timo is a professor of law at the University of Copenhagen, where he is also director of the Center for Advanced Studies in Bioscience Innovation Law. He specializes in legal aspects of biomedical innovation, including intellectual property law and regulatory law. He’s exercised his expertise as an advisor to such organizations as the World Health Organization and the European Commission.
And after our conversations, we’ll talk to Microsoft’s Chad Atalla, an applied scientist in responsible AI, about how we should think about these insights in the context of AI.
Daniel, it’s a pleasure to welcome you to the podcast. I’m just so appreciative of you being here. Thanks for joining us today.
DANIEL CARPENTER: Thanks for having me.
SULLIVAN: Dan, before we dissect policy, let’s rewind the tape to your origin story. Can you take us to the moment that you first became fascinated with regulators rather than, say, politicians? Was there a spark that pulled you toward the FDA story?
CARPENTER: At one point during graduate school, I was studying a combination of American politics and political theory, and I did a summer interning at the Department of Housing and Urban Development. And I began to think, why don’t people study these administrators more and the rules they make, the, you know, inefficiencies, the efficiencies? Really more from, kind of, a descriptive standpoint, less from a normative standpoint. And I was reading a lot that summer about the Food and Drug Administration and some of the decisions it was making on AIDS drugs. That was a, sort of, a major, …
SULLIVAN: Right.
CARPENTER: … sort of, you know, moment in the news, in the global news as well as the national news during, I would say, what? The late ’80s, early ’90s? And so I began to look into that.
SULLIVAN: So now that we know what pulled you in, let’s zoom out for our listeners. Give us the whirlwind tour. I think most of us know pharma involves years of trials, but what’s the part we don’t know?
CARPENTER: So I think when most businesses develop a product, they all go through some phases of research and development and testing. And I think what’s different about the FDA is, sort of, two- or three-fold.
First, a lot of those tests are much more stringently specified and regulated by the government, and second, one of the reasons for that is that the FDA imposes not simply safety requirements upon drugs in particular but also efficacy requirements. The FDA wants you to prove not simply that it’s safe and non-toxic but also that it’s effective. And the final thing, I think, that makes the FDA different is that it stands as what I would call the “veto player” over R&D [research and development] to the marketplace. The FDA basically has, sort of, this control over entry to the marketplace.
And so what that involves is usually first, a set of human trials where people who have no disease take it. And you’re only looking for toxicity generally. Then there’s a set of Phase 2 trials, where they look more at safety and a little bit at efficacy, and you’re now examining people who have the disease that the drug claims to treat. And you’re also basically comparing people who get the drug, often with those who do not.
And then finally, Phase 3 involves a much more direct and large-scale attack, if you will, or assessment of efficacy, and that’s where you get the sort of large randomized clinical trials that are very expensive for pharmaceutical companies, biomedical companies to launch, to execute, to analyze. And those are often the sort of core evidence base for the decisions that the FDA makes about whether or not to approve a new drug for marketing in the United States.
SULLIVAN: Are there differences in how that process has, you know, changed through other countries and maybe just how that’s evolved as you’ve seen it play out?
CARPENTER: Yeah, for a long time, I would say that the United States had probably the most stringent regime of regulation for biopharmaceutical products until, I would say, about the 1990s and early 2000s. It used to be the case that a number of other countries, especially in Europe but around the world, basically waited for the FDA to mandate tests on a drug and only after the drug was approved in the United States would they deem it approvable and marketable in their own countries. And then after the formation of the European Union and the creation of the European Medicines Agency, gradually the European Medicines Agency began to get a bit more stringent.
But, you know, over the long run, there’s been a lot of, sort of, heterogeneity, a lot of variation over time and space, in the way that the FDA has approached these problems. And I’d say in the last 20 years, it’s begun to partially deregulate, namely, you know, trying to find all sorts of mechanisms or pathways for really innovative drugs for deadly diseases without a lot of treatments to basically get through the process at lower cost. For many people, that has not been sufficient. They’re concerned about the cost of the system. Of course, then the agency also gets criticized by those who believe it’s too lax. It is potentially letting ineffective and unsafe therapies on the market.
SULLIVAN: In your view, when does the structured model genuinely safeguard patients and where do you think it maybe slows or limits innovation?
CARPENTER: So I think the worry is that if you approach pharmaceutical approval as a world where only things can go wrong, then you’re really at a risk of limiting innovation. And even if you end up letting a lot of things through, if by your regulations you end up basically slowing down the development process or making it very, very costly, then there’s just a whole bunch of drugs that either come to market too slowly or they come to market not at all because they just aren’t worth the kind of cost-benefit or, sort of, profit analysis of the firm. You know, so that’s been a concern. And I think it’s been one of the reasons that the Food and Drug Administration as well as other world regulators have begun to basically try to smooth the process and accelerate the process at the margins.
The other thing is that they’ve started to basically make approvals on the basis of what are called surrogate endpoints. So the idea is that a cancer drug, we really want to know whether that drug saves lives, but if we wait to see whose lives are saved or prolonged by that drug, we might miss the opportunity to make judgments on the basis of, well, are we detecting tumors in the bloodstream? Or can we measure the size of those tumors in, say, a solid cancer? And then the further question is, is the size of the tumor basically a really good correlate or predictor of whether people will die or not, right? Generally, the FDA tends to be less stringent when you’ve got, you know, a remarkably innovative new therapy and the disease being treated is one that just doesn’t have a lot of available treatments, right.
The one thing that people often think about when they’re thinking about pharmaceutical regulation is they often contrast, kind of, speed versus safety …
SULLIVAN: Right.
CARPENTER: … right. And that’s useful as a tradeoff, but I often try to remind people that it’s not simply about whether the drug gets out there and it’s unsafe. You know, you and I as patients and even doctors have a hard time knowing whether something works and whether it should be prescribed. And the evidence for knowing whether something works isn’t just, well, you know, Sally took it or Dan took it or Kathleen took it, and they seem to get better or they didn’t seem to get better.
The really rigorous evidence comes from randomized clinical trials. And I think it’s fair to say that if you didn’t have the FDA there as a veto player, you wouldn’t get as many randomized clinical trials and the evidence probably wouldn’t be as rigorous for whether these things work. And as I like to put it, basically there’s a whole ecology of expectations and beliefs around the biopharmaceutical industry in the United States and globally, and to some extent, it’s undergirded by all of these tests that happen.
SULLIVAN: Right.
CARPENTER: And in part, that means it’s undergirded by regulation. Would there still be a market without regulation? Yes. But it would be a market in which people had far less information in and confidence about the drugs that are being taken. And so I think it’s important to recognize that kind of confidence-boosting potential of, kind of, a scientific regulation base.
SULLIVAN: Actually, if we could double-click on that for a minute, I’d love to hear your perspective on, testing has been completed; there’s results. Can you walk us through how those results actually shape the next steps and decisions of a particular drug and just, like, how regulators actually think about using that data to influence really what happens next with it?
CARPENTER: Right. So it’s important to understand that every drug is approved for what’s called an indication. It can have a first primary indication, which is the main disease that it treats, and then others can be added as more evidence is shown. But a drug is not something that just kind of exists out there in the ether. It has to have the right form of administration. Maybe it should be injected. Maybe it should be ingested. Maybe it should be administered only at a clinic because it needs to be kind of administered in just the right way. As doctors will tell you, dosage is everything, right.
And so one of the reasons that you want those trials is not simply a, you know, yes or no answer about whether the drug works, right. It’s not simply if-then. It’s literally what goes into what you might call the dose response curve. You know, how much of this drug do we need to basically, you know, get the benefit? At what point does that fall off significantly that we can basically say, we can stop there? All that evidence comes from trials. And that’s the kind of evidence that is required on the basis of regulation.
Because it’s not simply a drug that’s approved. It’s a drug and a frequency of administration. It’s a method of administration. And so the drug isn’t just, there’s something to be taken off the shelf and popped into your mouth. I mean, sometimes that’s what happens, but even then, we want to know what the dosage is, right. We want to know what to look for in terms of side effects, things like that.
SULLIVAN: Going back to that point, I mean, it sounds like we’re making a lot of progress from a regulation perspective in, you know, sort of speed and getting things approved but doing it in a really balanced way. I mean, any other kind of closing thoughts on the tradeoffs there or where you’re seeing that going?
CARPENTER: I think you’re going to see some move in the coming years—there’s already been some of it—to say, do we always need a really large Phase 3 clinical trial? And to what degree do we need the, like, you know, all the i’s dotted and the t’s crossed or a really, really large sample size? And I’m open to innovation there. I’m also open to the idea that we consider, again, things like accelerated approvals or pathways for looking at different kinds of surrogate endpoints. I do think, once we do that, then we also have to have some degree of follow-up.
SULLIVAN: So I know we’re getting close to out of time, but maybe just a quick rapid fire if you’re open to it. Biggest myth about clinical trials?
CARPENTER: Well, some people tend to think that the FDA performs them. You know, it’s companies that do it. And the only other thing I would say is the company that does a lot of the testing and even the innovating is not always the company that takes the drug to market, and it tells you something about how powerful regulation is in our system, in our world, that you often need a company that has dealt with the FDA quite a bit and knows all the regulations and knows how to dot the i’s and cross the t’s in order to get a drug across the finish line.
SULLIVAN: If you had a magic wand, what’s the one thing you’d change in regulation today?
CARPENTER: I would like people to think a little bit less about just speed versus safety and, again, more about this basic issue of confidence. I think it’s fundamental to everything that happens in markets but especially in biopharmaceuticals.
SULLIVAN: Such a great point. This has been really fun. Just thanks so much for being here today. We’re really excited to share your thoughts out to our listeners. Thanks.
[TRANSITION MUSIC]
CARPENTER: Likewise.
SULLIVAN: Now to the world of medical devices, I’m joined by Professor Timo Minssen. Professor Minssen, it’s great to have you here. Thank you for joining us today.
TIMO MINSSEN: Yeah, thank you very much, it’s a pleasure.
SULLIVAN: Before getting into the regulatory world of medical devices, tell our audience a bit about your personal journey or your origin story, as we’re asking our guests. How did you land in regulation, and what’s kept you hooked in this space?
MINSSEN: So I started out as a patent expert in the biomedical area, starting with my PhD thesis on patenting biologics in Europe and in the US. So during that time, I was mostly interested in patent and trade secret questions. But at the same time, I also developed and taught courses in regulatory law and held talks on regulating advanced medical therapy medicinal products. I then started to lead large research projects on legal challenges in a wide variety of health and life science innovation frontiers. I also started to focus increasingly on AI-enabled medical devices and software as a medical device, resulting in several academic articles in this area and also in the regulatory area and a book on the future of medical device regulation.
SULLIVAN: Yeah, what’s kept you hooked in the space?
MINSSEN: It’s just incredibly exciting, in particular right now with everything that is going on, you know, in the software arena, in the marriage between AI and medical devices. And this is really challenging not only societies but also regulators and authorities in Europe and in the US.
SULLIVAN: Yeah, it’s a super exciting time to be in this space. You know, we talked to Daniel a little earlier and, you know, I think similar to pharmaceuticals, people have a general sense of what we mean when we say medical devices, but most listeners may picture like a stethoscope or a hip implant. The word “medical device” reaches much wider. Can you give us a quick, kind of, range from perhaps very simple to even, I don’t know, sci-fi and then your 90-second tour of how risk assessment works and why a framework is essential?
MINSSEN: Let me start out by saying that the WHO [World Health Organization] estimates that today there are approximately 2 million different kinds of medical devices on the world market, and as of the FDA’s latest update that I’m aware of, the FDA has authorized more than 1,000 AI-, machine learning-enabled medical devices, and that number is rising rapidly.
So in that context, I think it is important to understand that medical devices can be any instrument, apparatus, implement, machine, appliance, implant, reagent for in vitro use, software, material, or other similar or related articles that are intended by the manufacturer to be used alone or in combination for a medical purpose. And the spectrum of what constitutes a medical device can thus range from very simple devices such as tongue depressors, contact lenses, and thermometers to more complex devices such as blood pressure monitors, insulin pumps, MRI machines, implantable pacemakers, and even software as a medical device or AI-enabled monitors or drug device combinations, as well.
So talking about regulation, I think it is also very important to stress that medical devices are used in many diverse situations by very different stakeholders. And testing has to take this variety into consideration, and it is intrinsically tied to regulatory requirements across various jurisdictions.
During the pre-market phase, medical testing establishes baseline safety and effectiveness metrics through bench testing, performance standards, and clinical studies. And post-market testing ensures that real-world data informs ongoing compliance and safety improvements. So testing is indispensable in translating technological innovation into safe and effective medical devices. And while particular details of pre-market and post-market review procedures may slightly differ among countries, most developed jurisdictions regulate medical devices similarly to the US or European models.
So most jurisdictions with medical device regulation classify devices based on their risk profile, intended use, indications for use, technological characteristics, and the regulatory controls necessary to provide a reasonable assurance of safety and effectiveness.
SULLIVAN: So medical devices face a pretty prescriptive multi-level testing path before they hit the market. From your vantage point, what are some of the downsides of that system and when does it make the most sense?
MINSSEN: One primary drawback is, of course, the lengthy and expensive approval process. High-risk devices, for example, often undergo years of clinical trials, which can cost millions of dollars, and this can create a significant barrier for startups and small companies with limited resources. And even for moderate-risk devices, the regulatory burden can slow product development and time to the market.
And the approach can also limit flexibility. Prescriptive requirements may not accommodate emerging innovations like digital therapeutics or AI-based diagnostics in a feasible way. And in such cases, the framework can unintentionally [stiffen] innovation by discouraging creative solutions or iterative improvements, which as matter of fact can also put patients at risk when you don’t use new technologies and AI. And additionally, the same level of scrutiny may be applied to low-risk devices, where the extensive testing and documentation may also be disproportionate to the actual patient risk.
However, the prescriptive model is highly appropriate where we have high testing standards for high-risk medical devices, in my view, particularly those that are life-sustaining, implanted, or involve new materials or mechanisms.
I also wanted to say that I think that these higher compliance thresholds can be OK and necessary if you have a system where authorities and stakeholders also have the capacity and funding to enforce, monitor, and achieve compliance with such rules in a feasible, time-effective, and straightforward manner. And this, of course, requires resources, novel solutions, and investments.
SULLIVAN: A range of tests are undertaken across the life cycle of medical devices. How do these testing requirements vary across different stages of development and across various applications?
MINSSEN: Yes, that’s a good question. So I think first it is important to realize that testing is conducted by various entities, including manufacturers, independent third-party laboratories, and regulatory agencies. And it occurs throughout the device life cycle, beginning with iterative testing during the research and development stage, advancing to pre-market evaluations, and continuing into post-market monitoring. And the outcomes of these tests directly impact regulatory approvals, market access, and device design refinements, as well. So the testing results are typically shared with regulatory authorities and in some cases with healthcare providers and the broader public to enhance transparency and trust.
So if you talk about the different phases that play a role here … so let’s turn to the pre-market phase, where manufacturers must demonstrate that the device is conformed to safety and performance benchmarks defined by regulatory authorities. Pre-market evaluations include functional bench testing, biocompatibility, for example, assessments and software validation, all of which are integral components of a manufacturer’s submission.
But, yes, but, testing also, and we touched already up on that, extends into the post-market phase, where it continues to ensure device safety and efficacy, and post-market surveillance relies on testing to monitor real-world performance and identify emerging risks on the post-market phase. By integrating real-world evidence into ongoing assessments, manufacturers can address unforeseen issues, update devices as needed, and maintain compliance with evolving regulatory expectations. And I think this is particularly important in this new generation of medical devices that are AI-enabled or machine-learning enabled.
I think we have to understand that in this AI-enabled medical devices field, you know, the devices and the algorithms that are working with them, they can improve in the lifetime of a product. So actually, not only you could assess them and make sure that they maintain safe, you could also sometimes lower the risk category by finding evidence that these devices are actually becoming more precise and safer. So it can both, you know, heighten the risk category or lower the risk category, and that’s why this continuous testing is so important.
SULLIVAN: Given what you just said, how should regulators handle a device whose algorithm keeps updating itself after approval?
MINSSEN: Well, it has to be an iterative process that is feasible and straightforward and that is based on a very efficient, both time efficient and performance efficient, communication between the regulatory authorities and the medical device developers, right. We need to have the sensors in place that spot potential changes, and we need to have the mechanisms in place that allow us to quickly react to these changes both regulatory wise and also in the technological way.
So I think communication is important, and we need to have the pathways and the feedback loops in the regulation that quickly allow us to monitor these self-learning algorithms and devices.
SULLIVAN: It sounds like it’s just … there’s such a delicate balance between advancing technology and really ensuring public safety. You know, if we clamp down too hard, we stifle that innovation. You already touched upon this a bit. But if we’re too lax, we risk unintended consequences. And I’d just love to hear how you think the field is balancing that and any learnings you can share.
MINSSEN: So this is very true, and you just touched upon a very central question also in our research and our writing. And this is also the reason why medical device regulation is so fascinating and continues to evolve in response to rapid advancements in technologies, particularly dual technologies regarding digital health, artificial intelligence, for example, and personalized medicine.
And finding the balance is tricky because also [a] related major future challenge relates to the increasing regulatory jungle and the complex interplay between evolving regulatory landscapes that regulate AI more generally.
We really need to make sure that the regulatory authorities that deal with this, that need to find the right balance to promote innovation and mitigate and prevent risks, need to have the capacity to do this. So this requires investments, and it also requires new ways to regulate this technology more flexibly, for example through regulatory sandboxes and so on.
SULLIVAN: Could you just expand upon that a bit and double-click on what it is you’re seeing there? What excites you about what’s happening in that space?
MINSSEN: Yes, well, the research of my group at the Center for Advanced Studies in Bioscience Innovation Law is very broad. I mean, we are looking into gene editing technologies. We are looking into new biologics. We are looking into medical devices, as well, obviously, but also other technologies in advanced medical computing.
And what we see across the line here is that there is an increasing demand for having more adaptive and flexible regulatory frameworks in these new technologies, in particular when they have new uses, regulations that are focusing more on the product rather than the process. And I have recently written a report, for example, for emerging biotechnologies and bio-solutions for the EU commission. And even in that area, regulatory sandboxes are increasingly important, increasingly considered.
So this idea of regulatory sandboxes has been developing originally in the financial sector, and it is now penetrating into other sectors, including synthetic biology, emerging biotechnologies, gene editing, AI, quantum technology, as well. This is basically creating an environment where actors can test new ideas in close collaboration and under the oversight of regulatory authorities.
But to implement this in the AI sector now also leads us to a lot of questions and challenges. For example, you need to have the capacities of authorities that are governing and monitoring and deciding on these regulatory sandboxes. There are issues relating to competition law, for example, which you call antitrust law in the US, because the question is, who can enter the sandbox and how may they compete after they exit the sandbox? And there are many questions relating to, how should we work with these sandboxes and how should we implement these sandboxes?
[TRANSITION MUSIC]
SULLIVAN: Well, Timo, it has just been such a pleasure to speak with you today.
MINSSEN: Yes, thank you very much.
And now I’m happy to introduce Chad Atalla.
Chad is senior applied scientist in Microsoft Research New York City’s Sociotechnical Alignment Center, where they contribute to foundational responsible AI research and practical responsible AI solutions for teams across Microsoft.
Chad, welcome!
CHAD ATALLA: Thank you.
SULLIVAN: So we’ll kick off with a couple questions just to dive right in. So tell me a little bit more about the Sociotechnical Alignment Center, or STAC? I know it was founded in 2022. I’d love to just learn a little bit more about what the group does, how you’re thinking about evaluating AI, and maybe just give us a sense of some of the projects you’re working on.
ATALLA: Yeah, absolutely. The name is quite a mouthful.
SULLIVAN: It is! [LAUGHS]
ATALLA: So let’s start by breaking that down and seeing what that means.
SULLIVAN: Great.
ATALLA: So modern AI systems are sociotechnical systems, meaning that the social and technical aspects are deeply intertwined. And we’re interested in aligning the behaviors of these sociotechnical systems with some values. Those could be societal values; they could be regulatory values, organizational values, etc. And to make this alignment happen, we need the ability to evaluate the systems.
So my team is broadly working on an evaluation framework that acknowledges the sociotechnical nature of the technology and the often-abstract nature of the concepts we’re actually interested in evaluating. As you noted, it’s an applied science team, so we split our time between some fundamental research and time to bridge the work into real products across the company. And I also want to note that to power this sort of work, we have an interdisciplinary team drawing upon the social sciences, linguistics, statistics, and, of course, computer science.
SULLIVAN: Well, I’m eager to get into our takeaways from the conversation with both Daniel and Timo. But maybe just to double-click on this for a minute, can you talk a bit about some of the overarching goals of the AI evaluations that you noted?
ATALLA: So evaluation is really the act of making valuative judgments based on some evidence, and in the case of AI evaluation, that evidence might be from tests or measurements, right. And the goal of why we’re doing this in the first place is to make decisions and claims most often.
So perhaps I am going to make a claim about a model that I’m producing, and I want to say that it’s better than this other model. Or we are asking whether a certain product is safe to ship. All of these decisions need to be informed by good evaluation and therefore good measurement or testing. And I’ll also note that in the regulatory conversation, risk is often what we want to evaluate. So that is a goal in and of itself. And I’ll touch more on that later.
SULLIVAN: I read a recent paper that you had put out with some of our colleagues from Microsoft Research, from the University of Michigan, and Stanford, and you were arguing that evaluating generative AI is the social-science measurement challenge. Maybe for those who haven’t read the paper, what does this mean? And can you tell us a little bit more about what motivated you and your coauthors?
ATALLA: So the measurement tasks involved in evaluating generative AI systems are often abstract and contested. So that means they cannot be directly measured and must instead [be] indirectly measured via other observable phenomena. So this is very different than the older machine learning paradigm, where, let’s say, for example, I had a system that took a picture of a traffic light and told you whether it was green, yellow, or red at a given time.
If we wanted to evaluate that system, the task is much simpler. But with the modern generative AI systems that are also general purpose, they have open-ended output, and language in a whole chat or multiple paragraphs being outputted can have a lot of different properties. And as I noted, these are general-purpose systems, so we don’t know exactly what task they’re supposed to be carrying out.
So then the question becomes, if I want to make some decision or claim—maybe I want to make a claim that this system has human-level reasoning capabilities—well, what does that mean? Do I have the same impression of what that means as you do? And how do we know whether the downstream, you know, measurements and tests that I’m conducting actually will support my notion of what it means to have human-level reasoning, right? Difficult questions. But luckily, social scientists have been dealing with these exact sorts of challenges for multiple decades in fields like education, political science, and psychometrics. So we’re really attempting to avoid reinventing the wheel here and trying to learn from their past methodologies.
And so the rest of the paper goes on to delve into a four-level framework, a measurement framework, that’s grounded in the measurement theory from the quantitative social sciences that takes us all the way from these abstract and contested concepts through processes to get much clearer and eventually reach reliable and valid measurements that can power our evaluations.
SULLIVAN: I love that. I mean, that’s the whole point of this podcast, too, right. Is to really build on those other learnings and frameworks that we’re taking from industries that have been thinking about this for much longer. Maybe from your vantage point, what are some of the biggest day-to-day hurdles in building solid AI evaluations and, I don’t know, do we need more shared standards? Are there bespoke methods? Are those the way to go? I would love to just hear your thoughts on that.
ATALLA: So let’s talk about some of those practical challenges. And I want to briefly go back to what I mentioned about risk before, all right. Oftentimes, some of the regulatory environment is requiring practitioners to measure the risk involved in deploying one of their models or AI systems. Now, risk is importantly a concept that includes both event and impact, right. So there’s the probability of some event occurring. For the case of AI evaluation, perhaps this is us seeing a certain AI behavior exhibited. Then there’s also the severity of the impacts, and this is a complex chain of effects in the real world that happen to people, organizations, systems, etc., and it’s a lot more challenging to observe the impacts, right.
So if we’re saying that we need to measure risk, we have to measure both the event and the impacts. But realistically, right now, the field is not doing a very good job of actually measuring the impacts. This requires vastly different techniques and methodologies where if I just wanted to measure something about the event itself, I can, you know, do that in a technical sandbox environment and perhaps have some automated methods to detect whether a certain AI behavior is being exhibited. But if I want to measure the impacts? Now, we’re in the realm of needing to have real people involved, and perhaps a longitudinal study where you have interviews, questionnaires, and more qualitative evidence-gathering techniques to truly understand the long-term impacts. So that’s a significant challenge.
Another is that, you know, let’s say we forget about the impacts for now and we focus on the event side of things. Still, we need datasets, we need annotations, and we need metrics to make this whole thing work. When I say we need datasets, if I want to test whether my system has good mathematical reasoning, what questions should I ask? What are my set of inputs that are relevant? And then when I get the response from the system, how do I annotate them? How do I know if it was a good response that did demonstrate mathematical reasoning or if it was a mediocre response? And then once I have an annotation of all of these outputs from the AI system, how do I aggregate those all up into a single informative number?
SULLIVAN: Earlier in this episode, we heard Daniel and Timo walk through the regulatory frameworks in pharma and medical devices. I’d be curious what pieces of those mature systems are already showing up or at least may be bubbling up in AI governance.
ATALLA: Great question. You know, Timo was talking about the pre-market and post-market testing difference. Of course, this is similarly important in the AI evaluation space. But again, these have different methodologies and serve different purposes.
So within the pre-deployment phase, we don’t have evidence of how people are going to use the system. And when we have these general-purpose AI systems, to understand what the risks are, we really need to have a sense of what might happen and how they might be used. So there are significant challenges there where I think we can learn from other fields and how they do pre-market testing. And the difference in that pre- versus post-market testing also ties to testing at different stages in the life cycle.
For AI systems, we already see some regulations saying you need to start with the base model and do some evaluation of the base model, some basic attributes, some core attributes, of that base model before you start putting it into any real products. But once we have a product in mind, we have a user base in mind, we have a specific task—like maybe we’re going to integrate this model into Outlook and it’s going to help you write emails—now we suddenly have a much crisper picture of how the system will interact with the world around it. And again, at that stage, we need to think about another round of evaluation.
Another part that jumped out to me in what they were saying about pharmaceuticals is that sometimes approvals can be based on surrogate endpoints. So this is like we’re choosing some heuristic. Instead of measuring the long-term impact, which is what we actually care about, perhaps we have a proxy that we feel like is a good enough indicator of what that long-term impact might look like.
This is occurring in the AI evaluation space right now and is often perhaps even the default here since we’re not seeing that many studies of the long-term impact itself. We are seeing, instead, folks constructing these heuristics or proxies and saying if I see this behavior happen, I’m going to assume that it indicates this sort of impact will happen downstream. And that’s great. It’s one of the techniques that was used to speed up and reduce the barrier to innovation in the other fields. And I think it’s great that we are applying that in the AI evaluation space. But special care is, of course, needed to ensure that those heuristics and proxies you’re using are reasonable indicators of the greater outcome you’re looking for.
SULLIVAN: What are some of the promising ideas from maybe pharma or med device regulation that maybe haven’t made it to AI testing yet and maybe should? And where would you urge technologists, policymakers, and researchers to focus their energy next?
ATALLA: Well, one of the key things that jumped out to me in the discussion about pharmaceuticals was driving home the emphasis that there is a holistic focus on safety and efficacy. These go hand in hand and decisions must be made while considering both pieces of the picture. I would like to see that further emphasized in the AI evaluation space.
Often, we are seeing evaluations of risk being separated from evaluations of performance or quality or efficacy, but these two pieces of the puzzle really are not enough for us to make informed decisions independently. And that ties back into my desire to really also see us measuring the impacts.
So we see Phase 3 trials as something that occurs in the medical devices and pharmaceuticals field. That’s not something that we are doing an equivalent of in the AI evaluation space at this time. These are really cost intensive. They can last years and really involve careful monitoring of that holistic picture of safety and efficacy. And realistically, we are not going to be able to put that on the critical path to getting specific individual AI models or AI systems vetted before they go out into the world. However, I would love to see a world in which this sort of work is prioritized and funded or required. Think of how, with social media, it took quite a long time for us to understand that there are some long-term negative impacts on mental health, and we have the opportunity now, while the AI wave is still building, to start prioritizing and funding this sort of work. Let it run in the background and as soon as possible develop a good understanding of the subtle, long-term effects.
More broadly, I would love to see us focus on reliability and validity of the evaluations we’re conducting because trust in these decisions and claims is important. If we don’t focus on building reliable, valid, and trustworthy evaluations, we’re just going to continue to be flooded by a bunch of competing, conflicting, and largely meaningless AI evaluations.
SULLIVAN: In a number of the discussions we’ve had on this podcast, we talked about how it’s not just one entity that really needs to ensure safety across the board, and I’d just love to hear from you how you think about some of those ecosystem collaborations, and you know, from across … where we think about ourselves as more of a platform company or places that these AI models are being deployed more at the application level. Tell me a little bit about how you think about, sort of, stakeholders in that mix and where responsibility lies across the board.
ATALLA: It’s interesting. In this age of general-purpose AI technologies, we’re often seeing one company or organization being responsible for building the foundational model. And then many, many other people will take that model and build it into specific products that are designed for specific tasks and contexts.
Of course, in that, we already see that there is a responsibility of the owners of that foundational model to do some testing of the central model before they distribute it broadly. And then again, there is responsibility of all of the downstream individuals digesting that and turning it into products to consider the specific contexts that they are deploying into and how that may affect the risks we’re concerned with or the types of quality and safety and performance we need to evaluate.
Again, because that field of risks we may be concerned with is so broad, some of them also require an immense amount of expertise. Let’s think about whether AI systems can enable people to create dangerous chemicals or dangerous weapons at home. It’s not that every AI practitioner is going to have the knowledge to evaluate this, so in some of those cases, we really need third-party experts, people who are experts in chemistry, biology, etc., to come in and evaluate certain systems and models for those specific risks, as well.
So I think there are many reasons why multiple stakeholders need to be involved, partly from who owns what and is responsible for what and partly from the perspective of who has the expertise to meaningfully construct the evaluations that we need.
SULLIVAN: Well, Chad, this has just been great to connect, and in a few of our discussions, we’ve done a bit of a lightning round, so I’d love to just hear your 30-second responses to a few of these questions. Perhaps favorite evaluation you’ve run so far this year?
ATALLA: So I’ve been involved in trying to evaluate some language models for whether they infer sensitive attributes about people. So perhaps you’re chatting with a chatbot, and it infers your religion or sexuality based on things you’re saying or how you sound, right. And in working to evaluate this, we encounter a lot of interesting questions. Or, like, what is a sensitive attribute? What makes these attributes sensitive, and what are the differences that make it inappropriate for an AI system to infer these things about a person? Whereas realistically, whenever I meet a person on the street, my brain is immediately forming first impressions and some assumptions about these people. So it’s a very interesting and thought-provoking evaluation to conduct and think about the norms that we place upon people interacting with other people and the norms we place upon AI systems interacting with other people.
SULLIVAN: That’s fascinating! I’d love to hear the AI buzzword you’d retire tomorrow. [LAUGHTER]
ATALLA: I would love to see the term “bias” being used less when referring to fairness-related issues and systems. Bias happens to be a highly overloaded term in statistics and machine learning and has a lot of technical meanings and just fails to perfectly capture what we mean in the AI risk sense.
SULLIVAN: And last one. One metric we’re not tracking enough.
ATALLA: I would say over-blocking, and this comes into that connection between the holistic picture of safety and efficacy. It’s too easy to produce systems that throw safety to the wind and focus purely on utility or achieving some goal, but simultaneously, the other side of the picture is possible, where we can clamp down too hard and reduce the utility of our systems and block even benign and useful outputs just because they border on something sensitive. So it’s important for us to track that over-blocking and actively track that tradeoff between safety and efficacy.
SULLIVAN: Yeah, we talk a lot about this on the podcast, too, of how do you both make things safe but also ensure innovation can thrive, and I think you hit the nail on the head with that last piece.
[MUSIC]
Well, Chad, this was really terrific. Thanks for joining us and thanks for your work and your perspectives. And another big thanks to Daniel and Timo for setting the stage earlier in the podcast.
And to our listeners, thanks for tuning in. You can find resources related to this podcast in the show notes. And if you want to learn more about how Microsoft approaches AI governance, you can visit microsoft.com/RAI.
See you next time!
[MUSIC FADES]
The post AI Testing and Evaluation: Learnings from pharmaceuticals and medical devices appeared first on Microsoft Research.
Pennsylvania, USA
Nobody wants a spineless application development process. What do I mean by this? The spine is the backbone that supports and provides nerve channels for the human body. Without it, we would be floppy, weaker, and would struggle to understand how our extremities were behaving. A slightly tortured analogy, but consider the application lifecycle of the average software project. The traditional challenge has been, how do we give it a spine? How can we provide a backbone to support developers at every stage and a nerve channel to pass information back and forth, thereby cementing architectural constructs and automating or simplifying all the other processes required for modern applications?
We built Docker Compose specifically to be that spine, providing the foundation for an application from its inception in local development through testing and on to final deployment and maintenance as the application runs in the wild and interacts with real users. With Docker Compose Bridge, Docker Compose filled out the last gaps in full application lifecycle management. Using Compose Bridge, teams can now, with a single Compose file, take a multi-container, multi-tiered application from initial code and development setup all the way to production deployment in Kubernetes or other container orchestration systems.
Before and After: How Docker Compose Adds the Spine and Simplifies AppDev
So what does this mean in practice? Let’s take a “Before” and “After” view of how the spine of Docker Compose changes application lifecycle processes for the better. Imagine you’re building a customer-facing SaaS application—a classic three-tier setup:
- Go API handling user accounts, payments, and anti-fraud check
- PostgreSQL + Redis for persistence and caching
- TypeScript/React UI that customers log into and interact with
You are deploying to Kubernetes because you want resilience, portability, and flexibility. You’ll deploy it across multiple regions in the cloud for low latency and high availability. Let’s walk through what that lifecycle looks like before and after adopting Docker Compose + Compose Bridge.
Before: The Local Development “Works on My Machine” Status Quo
Without Compose, you set up five separate containers with a messy sprawl that might look something that looks like this:
docker network create saas-net
docker run -d --name postgres --network saas-net \
-e POSTGRES_PASSWORD=secret postgres:16
docker run -d --name redis --network saas-net redis:7
docker run -d --name go-api --network saas-net \
-e DB_URL=postgres://postgres:secret@postgres/saasdb \
-p 8080:8080 go-saas-api:latest
docker run -d --name payments --network saas-net payments-stub:1.2
docker run -d --name fraud --network saas-net anti-fraud:latest
docker run -d --name saas-ui --network saas-net \
-p 3000:3000 saas-ui:latest
You can certainly automate the setup process with a script. But that would mean everyone else you are working with would need the same script to replicate your setup. You would also need to ensure that they all have the same updated script. And that’s not the end of it. Before Compose, setting up even a basic multi-service stack meant manually crafting networks and links—typically running docker network create and then launching each container with --network to stitch them together (see Docker run network options). Onboarding new developers only made matters worse: your README would balloon with dozens of flags and environment-variable examples, and inevitably, someone would mistype a port or misspell a variable name. Meanwhile, security and compliance tended to be afterthoughts.
There would be no standard WAF or API gateway in front of your services. In many instances, secrets were scattered in plain .env files, and you would have no consistent audit logging to prove who accessed what and who made what changes. Then, for debugging, you manually spin up phpPgAdmin; for observability, you install Prometheus and Jaeger on an ad-hoc basis. For vulnerability scanning, you would pull down Docker Scout each time. Both debugging and scanning would drag you outside your core workflow and break your vibe.
After: One Line for Universal Local Environment
Remember those five containers you had to set up individually? Now, your Docker Compose “Spine” carries the message and structure to automatically set all those up for you with a single command and a single file (compose.yaml)
The resulting YAML pulls down and lists in a readable format the entire setup (database, cache, API, UI/UX) of your setup, all living on a shared network with security, observability, and any other necessary services already in place. Not only does this save time and ensure consistency, but it also greatly boosts security (manual config error remains one of the leading sources of security breaches, according to the Verizon 2025 DBIR Report). This also standardizes all mounts and ports, ensuring secrets are treated uniformly. For compliance and artifact provenance, all audit logs are automatically mounted for local compliance checks.
Compose also makes debugging and hardening apps locally easier for developers who don’t want to think about setting up debug services. With Compose, the developer or platform team can add a debug profile that invokes a host of debug services (Prometheus for metrics, OpenTelemetry for distributed tracing, Grafana for dashboards, ModeSec for firewall rules). That said, you don’t want to add debug services to production apps in Kubernetes.
Enter Compose Bridge. This new addition to Docker Compose incorporates environmental awareness into all services, removing those that should not be deployed in production, and provides a clean Helm Chart or YAML manifest for production teams. So application developers don’t need to worry about stripping service calls before throwing code over the fence. More broadly, Compose Bridge enforces:
- Clean separation – production YAML stays lean, with no leftover debug containers or extra resource definitions.
- Conditional inclusion – Bridge reads
profiles:settings and injects the right labels, annotations, and sidecars only when you ask for them. - Consistent templating – Bridge handles the profile logic at generation time, so all downstream manifests conform to stage and environment-specific policies and naming conventions
The result? Platform Operations teams can maintain different Docker Compose templates for various application development teams, keeping everyone on the established paths while providing customization where needed. Application Security teams can easily review or scan standardized YAML files to simplify policy adherence across configuration verification, secret handling, and services accessed.
Before: CI & Testing Lead to Script Sprawl and Complexity
Application developers pass their code off to the DevOps team (or have the joy of running the CI/CD gauntlet themes). Teams typically wire up their CI tool (Jenkins, GitLab CI, GitHub Actions, etc.) to run shell-based workflows. Any changes to the application, like renaming a service, adding a dependency, adjusting a port, or adding a new service, mean editing those scripts or editing every CI step that invokes them. In theory, GitOps means automating much of this. In practice, the complexity is thinly buried and the system lacks, for better or for worse, a nervous system along the spine. The result? Builds break, tests fail, and the time to launch a new version and incorporate new code lengthens. Developers are inherently discouraged from shipping code faster because they know there’s a decent chance that even when everything shows green in their local environment tests, something will break in CI/CD. This dooms them to unpleasant troubleshooting ordeals. Without a nervous system along the spine to share information and easily propagate necessary changes, application lifecycles are more chaotic, less secure and less efficient.
After: CI & Testing Run Fast, Smooth and Secure
After adopting Docker Compose as your application development spine, your CI/CD pipeline becomes a concise, reliable sequence that mirrors exactly what you run locally. A single compose.yaml declares every component so your CI job simply brings up the entire stack with docker compose up -d, orchestrating startup order and health checks without custom scripts or manual delays. You invoke your tests in the context of a real multi-container network via docker compose exec, replacing brittle mocks with true integration and end-to-end validation. When testing is complete, docker compose down tears down containers, networks, and volumes in one step, guaranteeing a clean slate for every build. Because CI consumes exactly the same manifest developers use on their workstations, feedback loops shrink to minutes, and promotions to staging or production require fewer (and often no) manual configuration tweaks.
Compose Bridge further elevates this efficiency and hardens security. After running tests, Bridge automatically converts your Docker Compose YAML file into Kubernetes manifests or a Helm chart, injecting network policies, security contexts, runtime protection sidecars, and audit log mounts based on your profiles and overlays. There’s no need for separate scripts or manual edits to bake in contract tests, policy validations, or vulnerability scanners. Your CI job can commit the generated artifacts directly to a GitOps repository, triggering an automated, policy-enforced rollout across all environments. This unified flow eliminates redundant configuration, prevents drift, and removes human error, turning CI/CD from a fragile sequence into a single, consistent pipeline.
Before: Production and Rollbacks are Floppy and Floundering
When your application leaves CI and enters production, the absence of a solid spine becomes painfully clear. Platform teams must shoulder the weight of multiple files — Helm charts, raw manifests for network segmentation, pod security, autoscaling, ingress rules, API gateway configuration, logging agents, and policy enforcers. Each change ripples through, requiring manual edits in three or more places before nerves can carry the signal to a given cluster. There is no central backbone to keep everything aligned. A simple update to your service image or environment variable creates a cascade of copy-and-paste updates in values.yaml, template patches, and documentation. If something fails, your deployment collapses and you start manual reviews to find the source of the fault. Rolling back demands matching chart revisions to commits and manually issuing helm rollback. Without a nervous system to transmit clear rollback signals, each regional cluster becomes its own isolated segment. Canary and blue-green releases require separate, bespoke hooks or additional Argo CD applications, each one a new wrinkle in coordination. This floppy and floundering approach leaves your production lifecycle weak, communication slow, and the risk of human error high. The processes meant to support and stabilize your application instead become sources of friction and uncertainty, undermining the confidence of both engineering and operations teams.
After: Production and Rollbacks are Rock Solid
With Docker Compose Bridge acting as your application’s spinal cord, production and rollbacks gain the support and streamlined communication they’ve been missing. Your single compose.yaml file becomes the vertebral column that holds every service definition, environment variable, volume mount, and compliance rule in alignment. When you invoke docker compose bridge generate, the Bridge transforms that backbone into clean Kubernetes manifests or a Helm chart, automatically weaving in network policies, pod security contexts, runtime protection sidecars, scaling rules, and audit-log mounts. There is no need for separate template edits. Changes made to the Compose file propagate in real-time through all generated artifacts. Deployment can be as simple as committing the updated Compose file to your GitOps repository. Argo CD or Flux then serves as the extended nervous system, transmitting the rollout signal across every regional cluster in a consistent, policy-enforced manner. If you need to reverse course, reverting the Compose file acts like a reflex arc: Bridge regenerates the previous manifests and GitOps reverts each cluster to its prior state without manual intervention. Canary and blue-green strategies fit naturally into this framework through Compose profiles and Bridge overlays, eliminating the need for ad-hoc hooks. Your production pipeline is no longer a loose bundle of scripts and templates but a unified, resilient spine that supports growth, delivers rapid feedback, and ensures secure, reliable releases across all environments.
A Fully Composed Spine for the Full Lifecycle
To summarize, Docker Compose and Compose Bridge give your application a continuous spine running from local development through CI / CD, security validation and multi-region Kubernetes rollout. You define every service, policy and profile once in a Compose file, and Bridge generates production ready manifests with network policies, security contexts, telemetry, database, API and audit-log mounts already included. Automated GitOps rollouts and single-commit rollbacks make deployments reliable and auditable and fast. This helps application developers focus on features instead of plumbing, gives AppSec consistent policy enforcement, allows SecOps to maintain standardized audit trails, helps PlatformOps simplify operations and delivers faster time to market with reduced risk for the business.
Ready to streamline your pipeline and enforce security? Give it a try in your next project by defining your stack in Compose, then adding Bridge to automate manifest generation and GitOps rollouts.
Pennsylvania, USA
In this post, we’ll demonstrate how to orchestrate Model Context Protocol (MCP) servers using llamaindex.TS in a real-world TypeScript application. We’ll use the Azure AI Travel Agents project as our base, focusing on best practices for secure, scalable, and maintainable orchestration. Feel free to star the repo to get notified with the latest changes.
Why llamaindex.TS and MCP?
- llamaindex.TS provides a modular, composable framework for building LLM-powered applications in TypeScript.
- MCP enables tool interoperability and streaming, making it ideal for orchestrating multiple AI services.
Project Structure
The Llamaindex.TS orchestrator lives in src/api/src/orchestrator/llamaindex, with provider modules for different LLM backends and MCP clients. We currently support:
- Azure OpenAI
- Docker Models
- Azure AI Foundry Local
- Github Model
- Ollama
Feel free to explore the code base and suggest more providers.
Setting Up the MCP Client with Streamable HTTP
To interact with MCP servers, without using Llamaindex.TS, we can write a custom implementation using the StreamableHTTPClientTransport for efficient, authenticated, and streaming communication.
// filepath: src/api/src/mcp/mcp-http-client.ts
import EventEmitter from 'node:events';
import { Client } from '@modelcontextprotocol/sdk/client/index.js';
import { StreamableHTTPClientTransport } from '@modelcontextprotocol/sdk/client/streamableHttp.js';
export class MCPClient extends EventEmitter {
private client: Client;
private transport: StreamableHTTPClientTransport;
constructor(serverName: string, serverUrl: string, accessToken?: string) {
this.transport = new StreamableHTTPClientTransport({
url: serverUrl,
headers: accessToken ? { Authorization: `Bearer ${accessToken}` } : {},
});
this.client = new Client(serverName, this.transport);
}
async connect() {
await this.client.initialize();
}
async listTools() {
return this.client.listTools();
}
async callTool(name: string, toolArgs: any) {
return this.client.callTool(name, toolArgs);
}
async close() {
await this.client.closeGracefully();
}
}
Best Practice: Always pass the Authorization header for secure access, as shown above.
Orchestrating LLMs and MCP Tools
The mcp client from @llamaindex/tools makes it easy to connect to MCP servers and retrieve tool definitions dynamically. Below is a sample from the project’s orchestrator setup, showing how to use mcp to fetch tools and create agents for each MCP server.
Here is an example of what an mcpServerConfig object might look like:
const mcpServerConfig = {
url: "http://localhost:5007", // MCP server endpoint
accessToken: process.env.MCP_ECHO_PING_ACCESS_TOKEN, // Secure token from env
name: "echo-ping", // Logical name for the server
};
You can then use this config with the mcp client:
import { mcp } from "@llamaindex/tools";
// ...existing code...
const mcpServerConfig = mcpToolsConfig["echo-ping"].config;
const tools = await mcp(mcpServerConfig).tools();
const echoAgent = agent({
name: "EchoAgent",
systemPrompt:
"Echo back the received input. Do not respond with anything else. Always call the tools.",
tools,
llm,
verbose,
});
agentsList.push(echoAgent);
handoffTargets.push(echoAgent);
toolsList.push(...tools);
You can repeat this pattern to compose a multi-agent workflow where each agent is powered by tools discovered at runtime from the MCP server. See project for a full example.
You can then use this LLM instance to orchestrate calls to MCP tools, such as itinerary planning or destination recommendation.
Example: Calling manually an MCP Tool from the Orchestrator
Suppose you want to get destination recommendations from the MCP server:
import { MCPClient } from '../../mcp/mcp-http-client';
const DESTINATION_SERVER_URL = process.env.MCP_DESTINATION_RECOMMENDATION_URL!;
const ACCESS_TOKEN = process.env.MCP_DESTINATION_RECOMMENDATION_ACCESS_TOKEN;
const mcpClient = new MCPClient('destination-recommendation', DESTINATION_SERVER_URL, ACCESS_TOKEN);
await mcpClient.connect();
const tools = await mcpClient.listTools();
console.log('Available tools:', tools);
const result = await mcpClient.callTool('getDestinationsByPreferences', {
activity: 'CULTURAL',
budget: 'MODERATE',
season: 'SUMMER',
familyFriendly: true,
});
console.log('Recommended destinations:', result);
await mcpClient.close();
Tip: Always close the MCP client gracefully to release resources.
Security Considerations
- Always use access tokens and secure headers.
- Never hardcode secrets; use environment variables and secret managers.
Join the Community:
We encourage you to join our Azure AI Foundry Developer Community to share your experiences, ask questions, and get support:
- aka.ms/foundry/discord Join our Discord community for real-time discussions and support.
- aka.ms/foundry/forum - Visit our Azure AI Foundry Developer Forum to ask questions and share your knowledge.
Conclusion
By combining llamaindex.TS with MCP’s Streamable HTTP transport, you can orchestrate powerful, secure, and scalable AI workflows in TypeScript. The Azure AI Travel Agents project provides a robust template for building your own orchestrator.
References:
Pennsylvania, USA
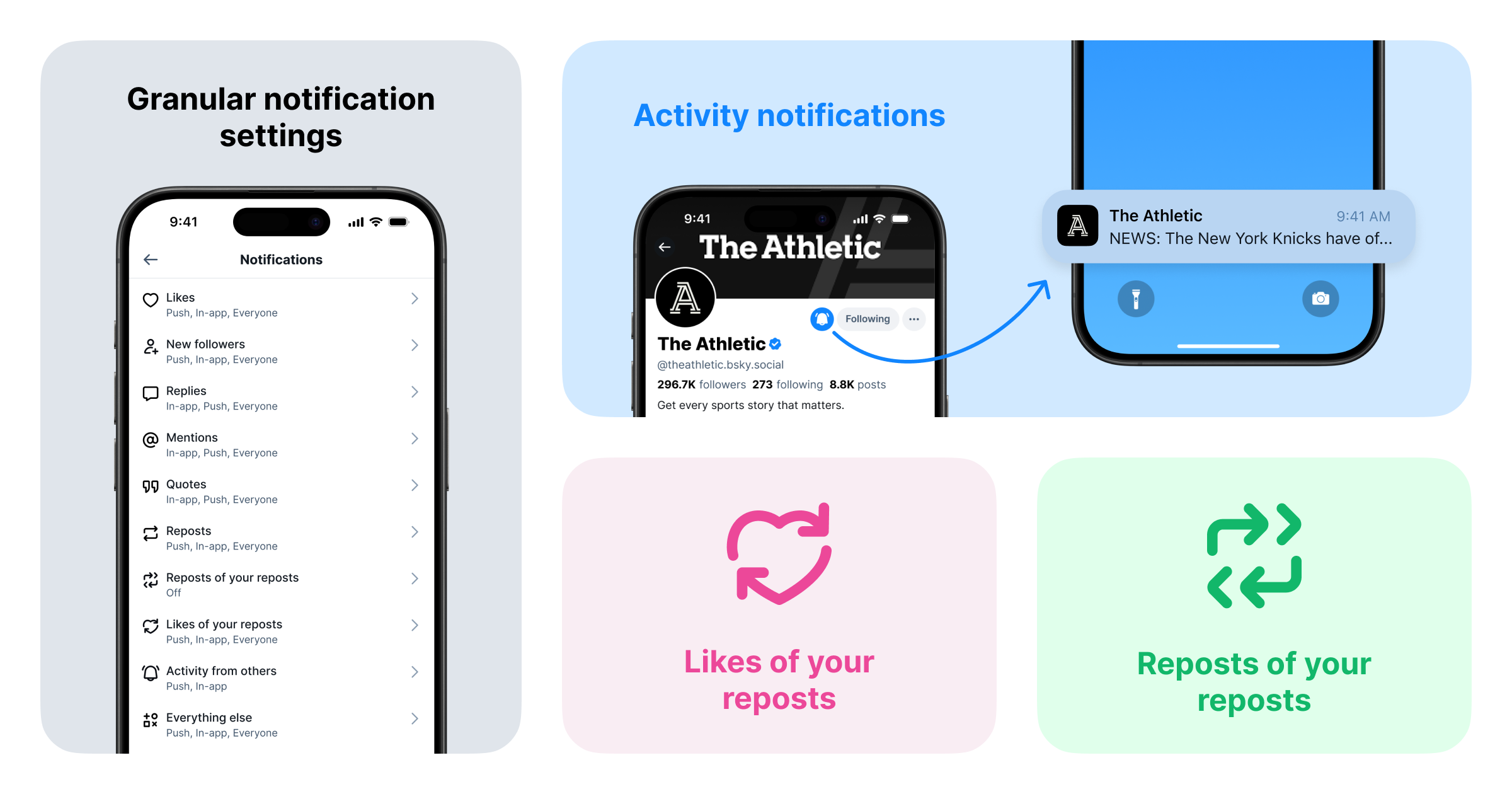
At Bluesky, we're constantly working to help you personalize your experience. We know that staying connected means different things to different people, and sometimes, you just need to cut through the noise. That's why we're excited to introduce three updates to notifications:
- Activity Notifications: Opt-in to receive push notifications from specific accounts.
- Enhanced Notification Settings: Controls to fine tune which notifications you receive.
- Repost Notifications: Receive notifications when someone likes or reposts posts you’ve reposted.
Activity Notifications: Never Miss a Post Again!
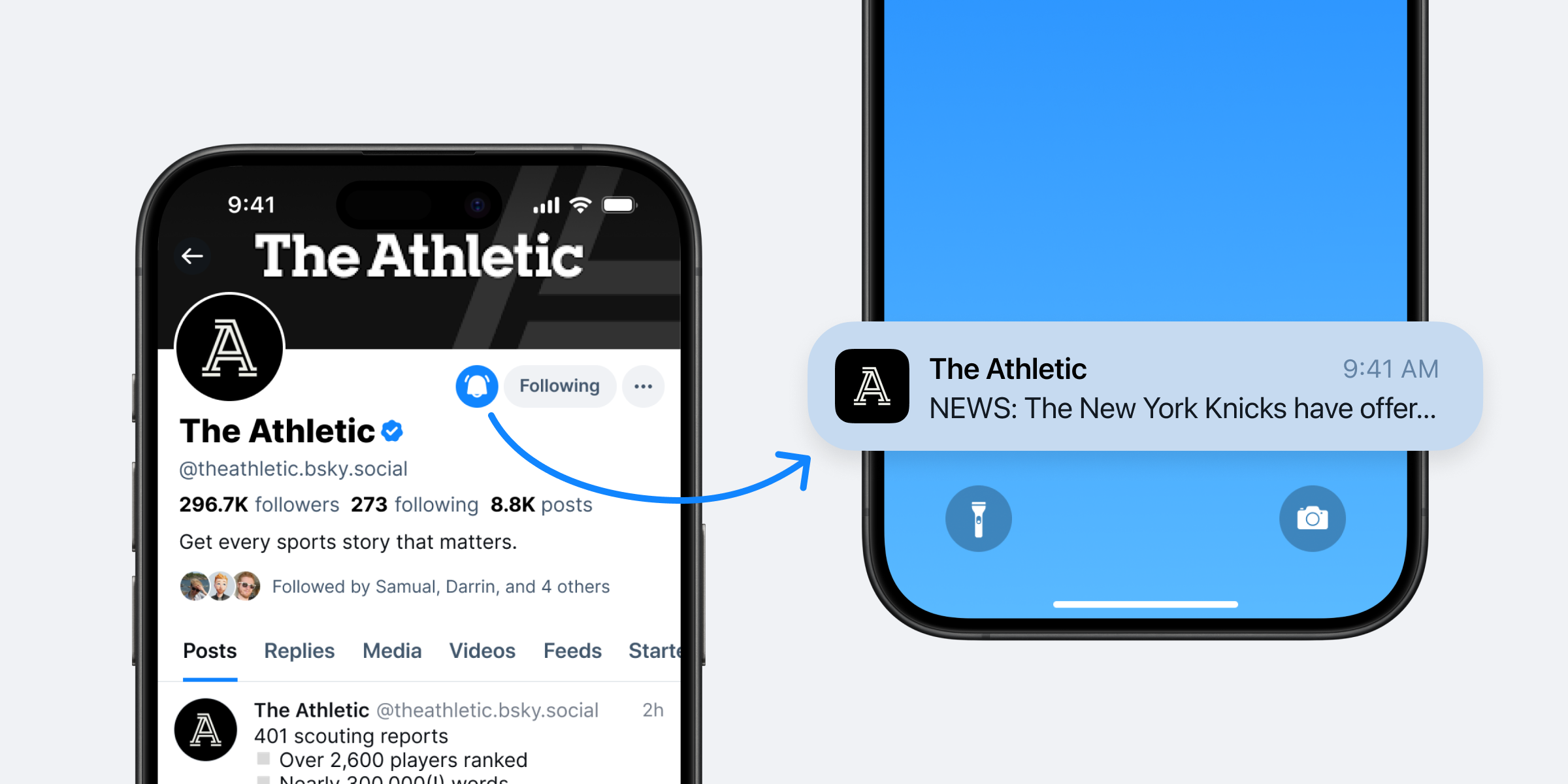
Staying connected with the accounts that matter most to you just got easier with Activity Notifications, which let you receive push and in-app notifications directly from specific accounts. Never miss a breaking update, a new thought, or a live moment from the accounts you follow closely.
It's simple to enable these new notifications:
- Navigate to a profile: Visit the profile of an account you love.
- Look for the bell icon: If they have this feature enabled, you'll see a small bell icon next to the 'Follow' button.
- Tap the bell: Press it, and you'll be able to enable notifications specifically for their new posts, and optionally, even their replies.
You can easily opt in to manage the list of people you're receiving "Activity Notifications" from at any time by going to Settings > Notifications > Activity Notifications.
For posters: if you want to keep things more mellow, you have the option to disable this feature entirely, or enable it only for people you follow, by going to Settings > Privacy and Security > Allow others to get notified of your posts.
Enhanced Notification Settings: Take Charge of Your Notifications
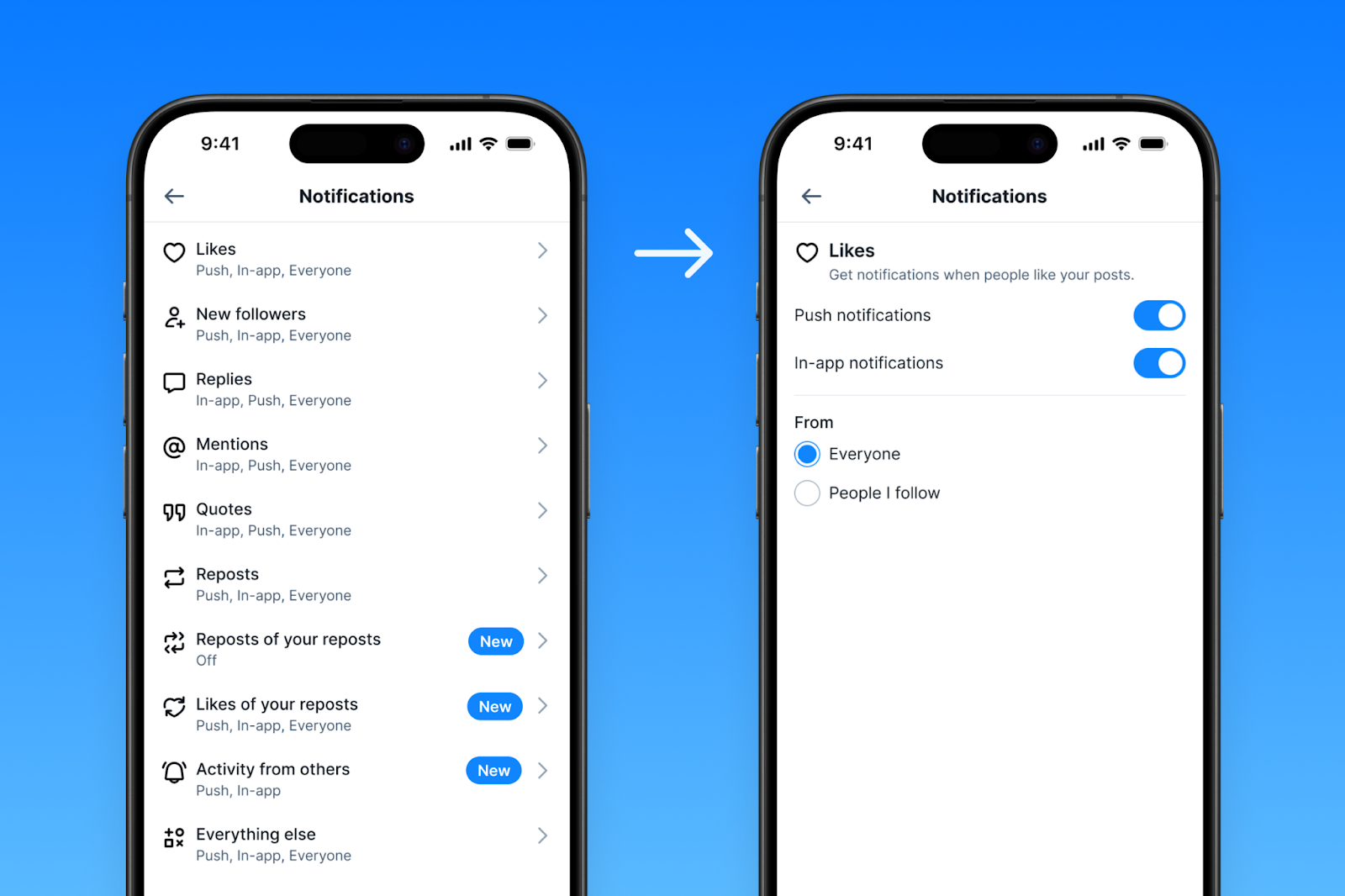
We’re rolling out new controls over the notifications you receive. Head over to Settings > Notifications to fine-tune your preferences. You can now choose to receive notifications from:
- Everyone: Stay in the loop with all interactions.
- People you follow: Filter out the noise and focus on your close connections.
- No One: For when you need a moment of peace and quiet.
Here are the notification types you can now customize:
- Replies: Control who can notify you when they reply to your posts.
- Mentions: Decide when you're pinged for a mention.
- Quotes: Manage notifications for posts that quote yours.
- Likes: Get notified when someone likes your posts.
- Reposts: See when your posts are reposted.
- New followers: Keep track of your growing audience.
- Likes of your reposts: Get feedback on the content you curate.
- Reposts of your reposts: See how far your shared content travels.
- Everything else: This covers general notifications, like when someone joins via one of your Starter Packs, or verification notifications. We've kept this category flexible so we can add more helpful updates in the future.
You can also enable and disable whether you receive push notifications for each of these categories, giving you even more granular control.
A Note on Priority Notifications: Our previous "priority notifications" feature has been replaced by these new, comprehensive settings. If you previously had priority notifications enabled, your settings have been seamlessly migrated to these new options. Changing your reply, mention, and quote notifications to "people you follow only" will have the same effect as priority notifications did previously.
Get Notified About Your Reposts!
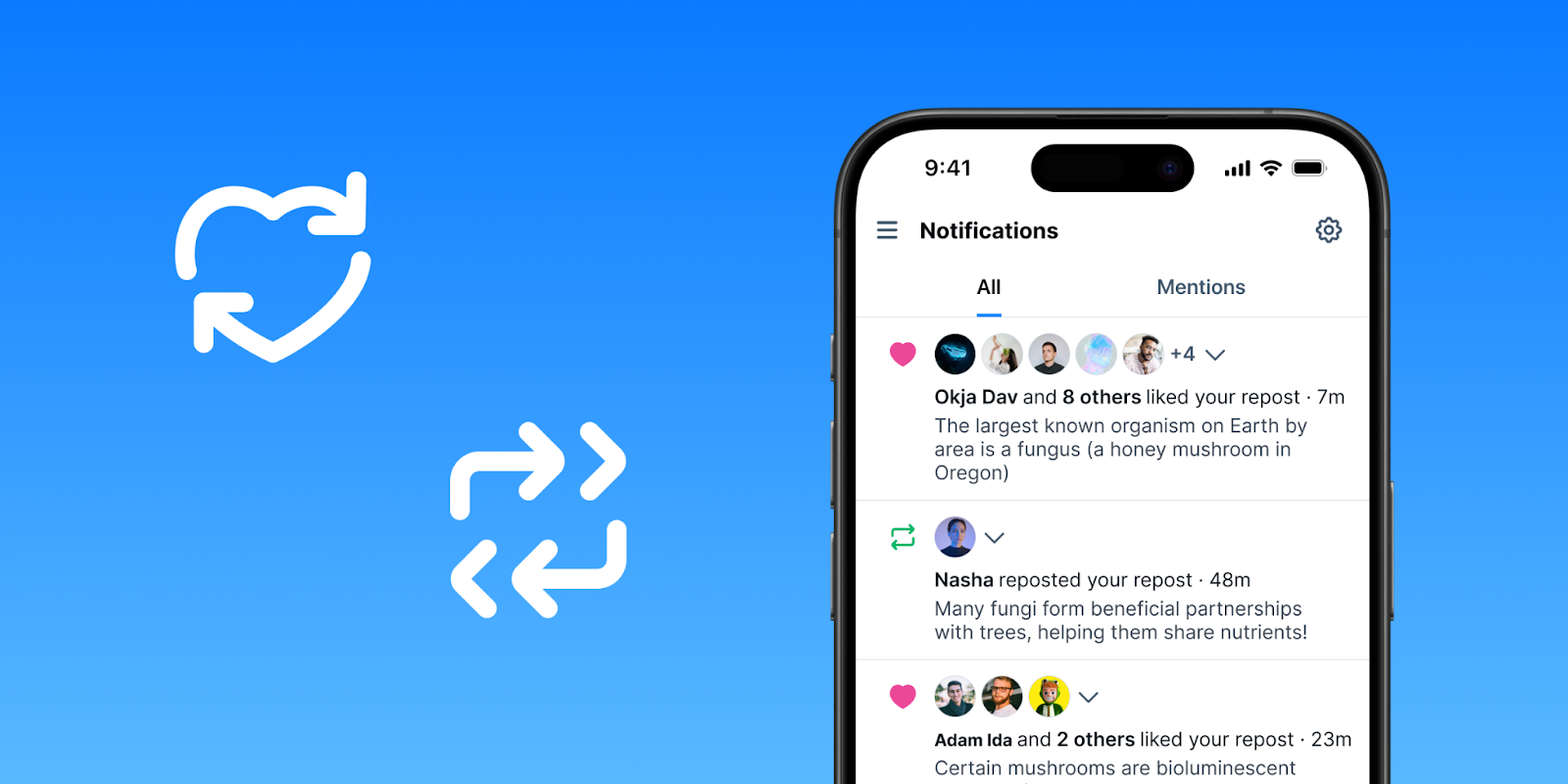
Finally, we’re introducing a new improvement for those who love to curate and share posts: you can now receive notifications when someone likes or reposts content you've reposted. Of course, you can adjust these notifications in your settings, choosing to receive them from everyone, just people you follow, or turning them off entirely.
We believe these updates will empower you to shape your Bluesky experience to be exactly what you want. Dive into your settings and explore the new controls you have!
Pennsylvania, USA
Next Page of Stories