Working with table data is an essential part of database development — whether you’re validating behavior, debugging issues, or quickly seeding data. But switching between tools or writing repetitive T-SQL statements can slow down your workflow.
We are excited to announce the Public Preview of Edit Data in the MSSQL extension for Visual Studio Code — a modern, interactive way to browse and modify table data directly within the editor. Edit Data (Preview) brings a familiar, spreadsheet-like experience, combining inline editing, validation, pagination, and real-time script generation into a fast and intuitive workflow tailored for developers.
Edit Data is in Public Preview.
We are actively adding more features, improving usability, and expanding capabilities. Your feedback is extremely important — please tell us what works, what doesn’t, and what you’d like us to improve.
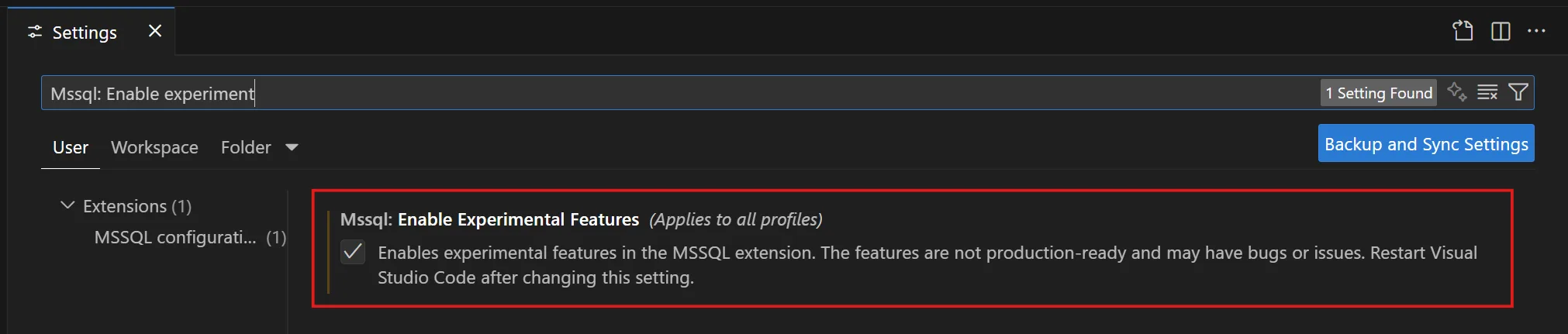
How to get started: Enable Experimental Features (Required)
To use Edit Data (Preview), you must enable the experimental features setting in the MSSQL extension.
Open Settings in VS Code
Search for “MSSQL: Enable Experimental Features”
Check the box to enable it
Reload VS Code if prompted
Edit Data is only available in MSSQL extension v1.37 or later.
If you do not see the option, update your extension first.
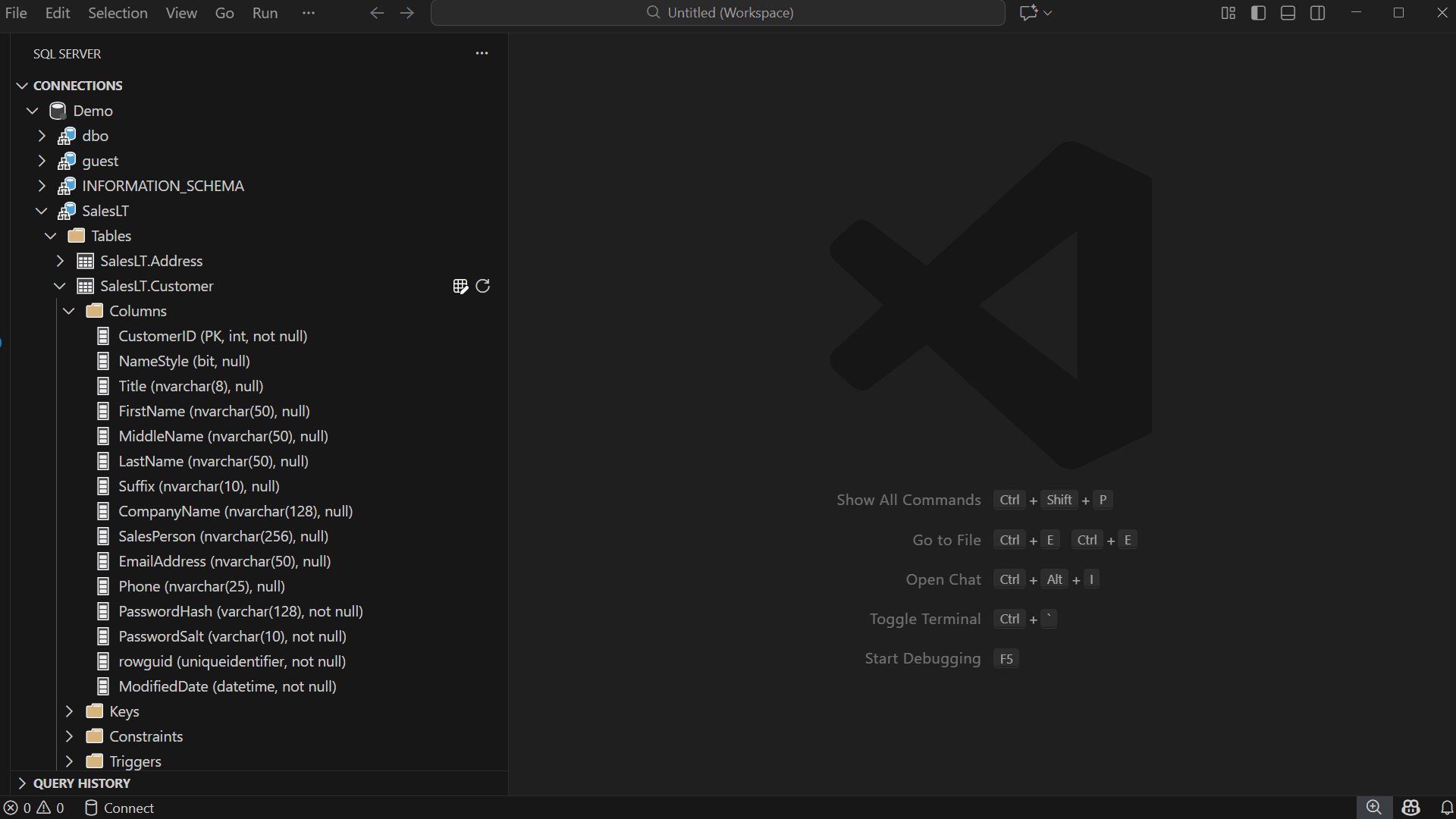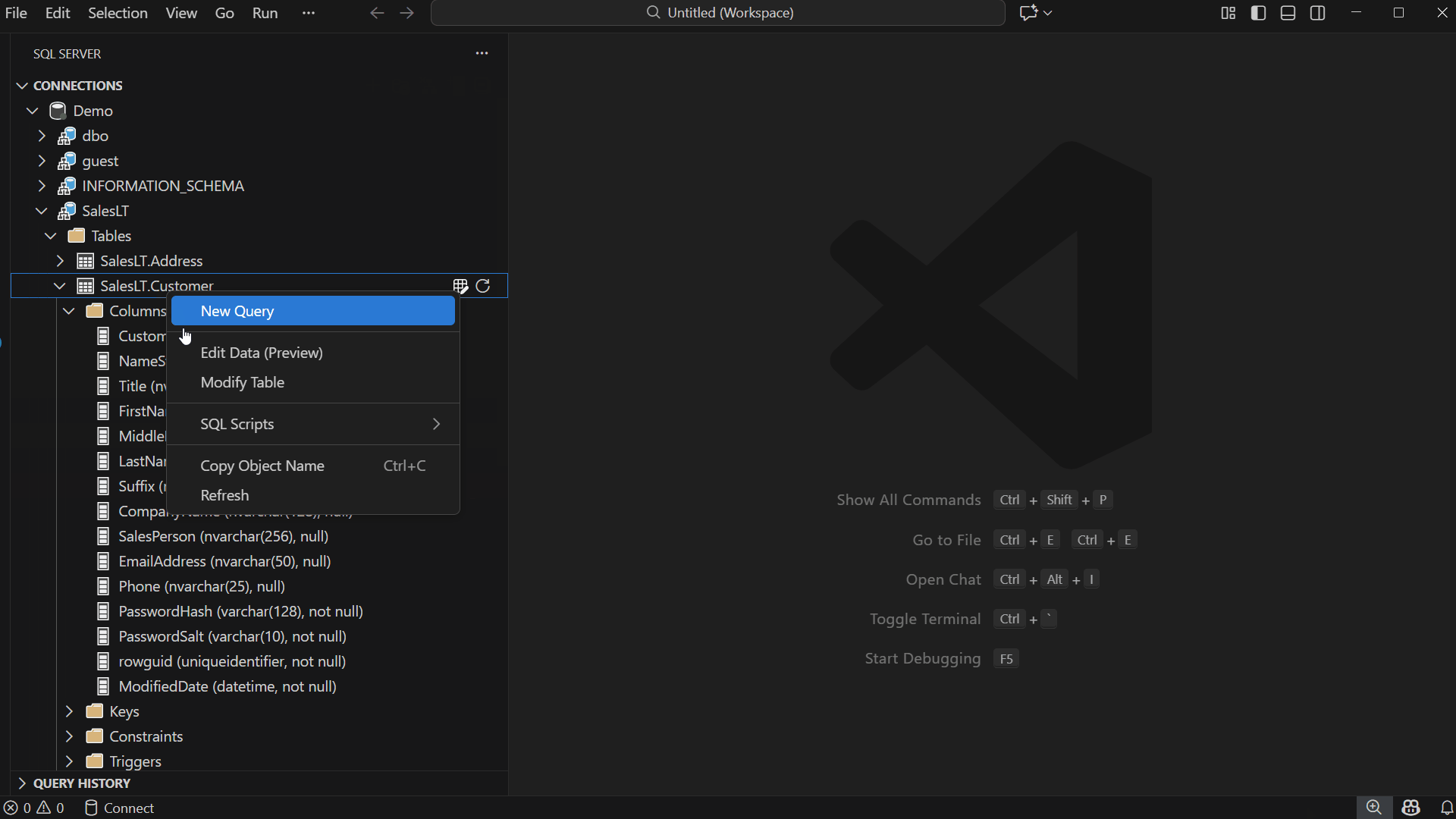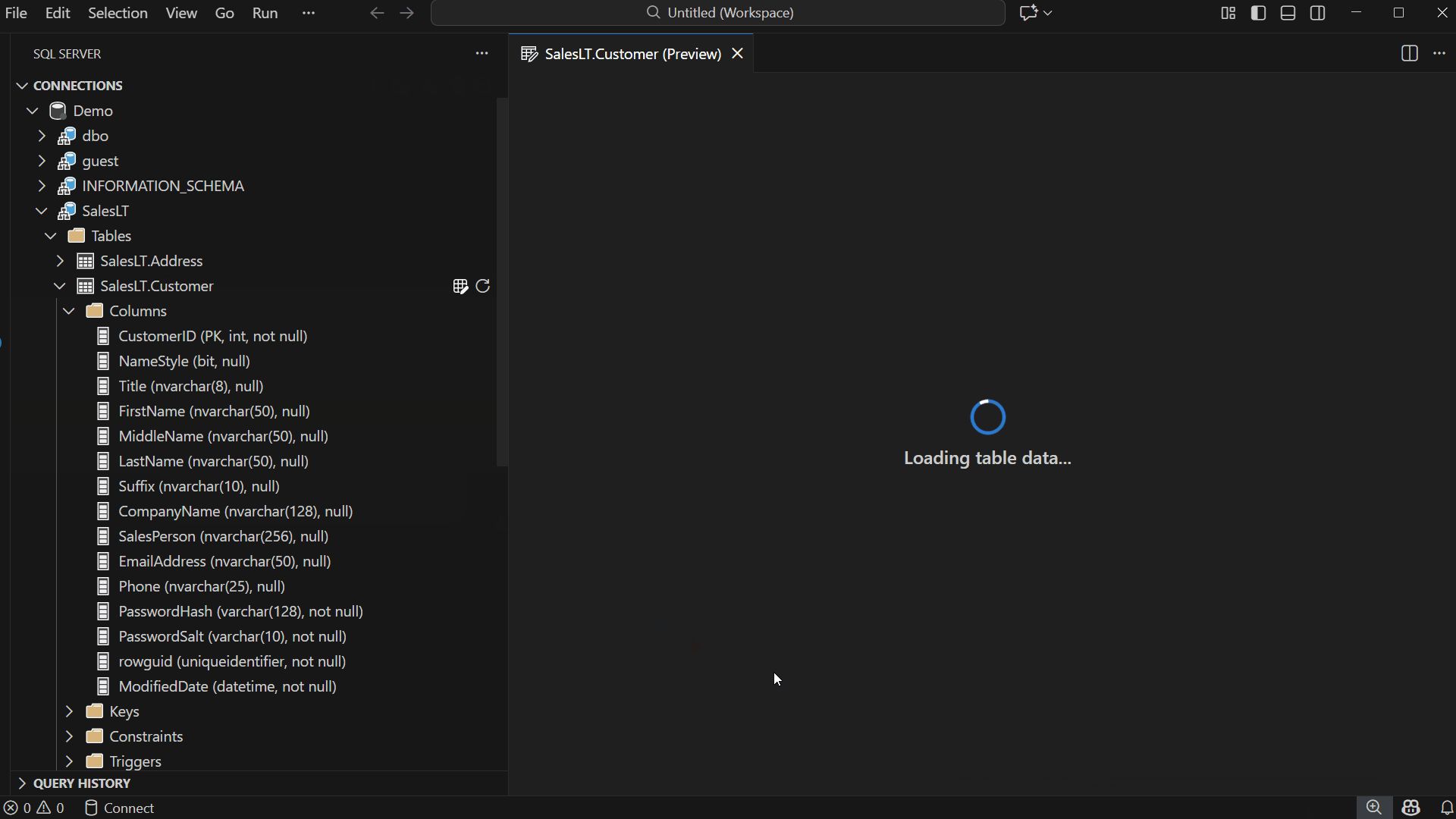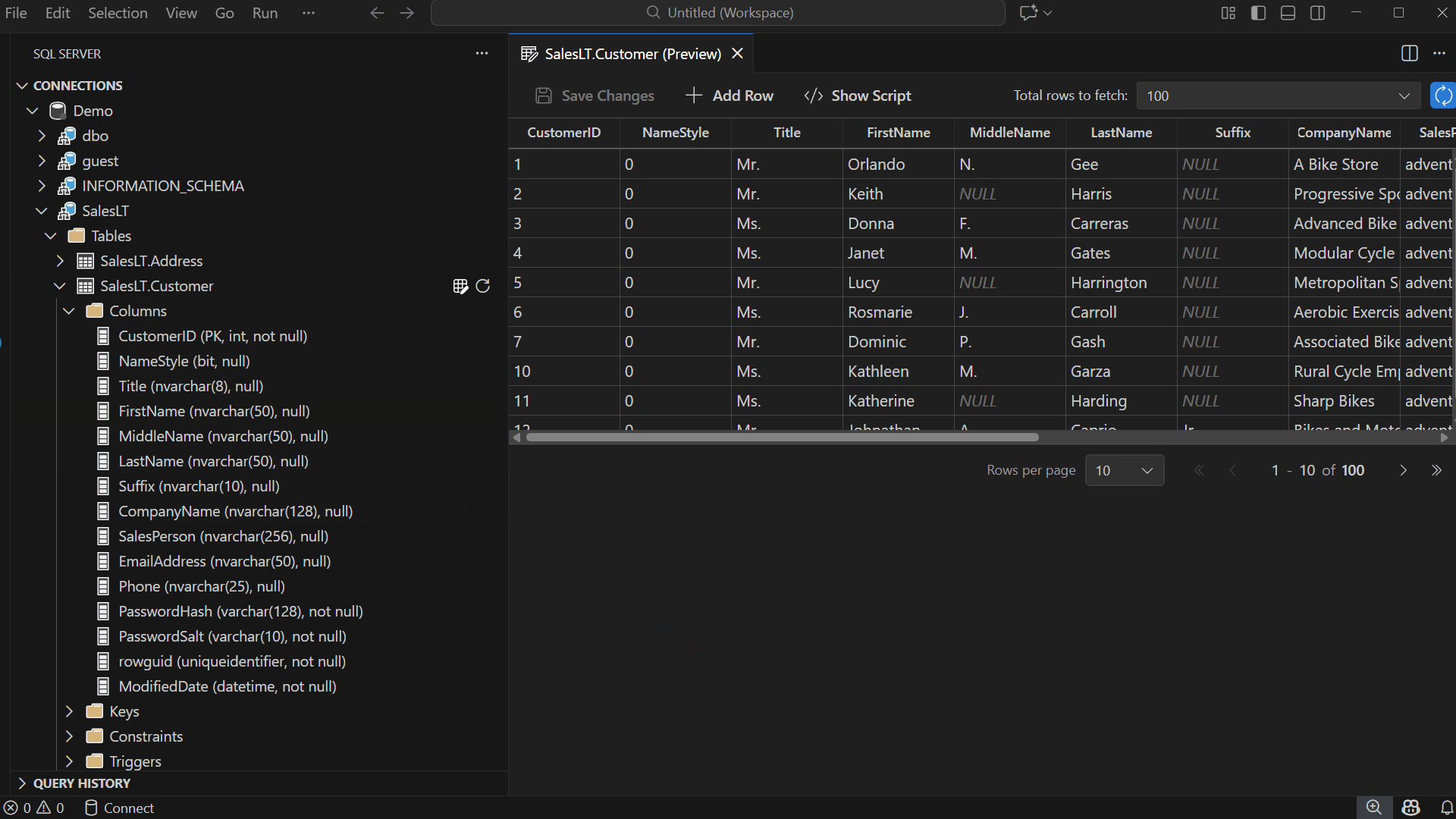
Open Edit Data
To launch the Edit Data experience:
Right-click any table in the Object Explorer and select “Edit Data (Preview)”
Or simply double-click the table name
This opens a new editor tab containing the data grid for that table.
Browse and Edit Table Data
Inline Editing: Double-click any cell and start typing to update its value.
Add & Delete Rows: Use the toolbar to insert new rows or right-click to delete existing ones. Edits appear as pending changes until you save.
Revert Edits: Right-click a row or cell to Revert Row or Revert Cell, restoring its last saved value.
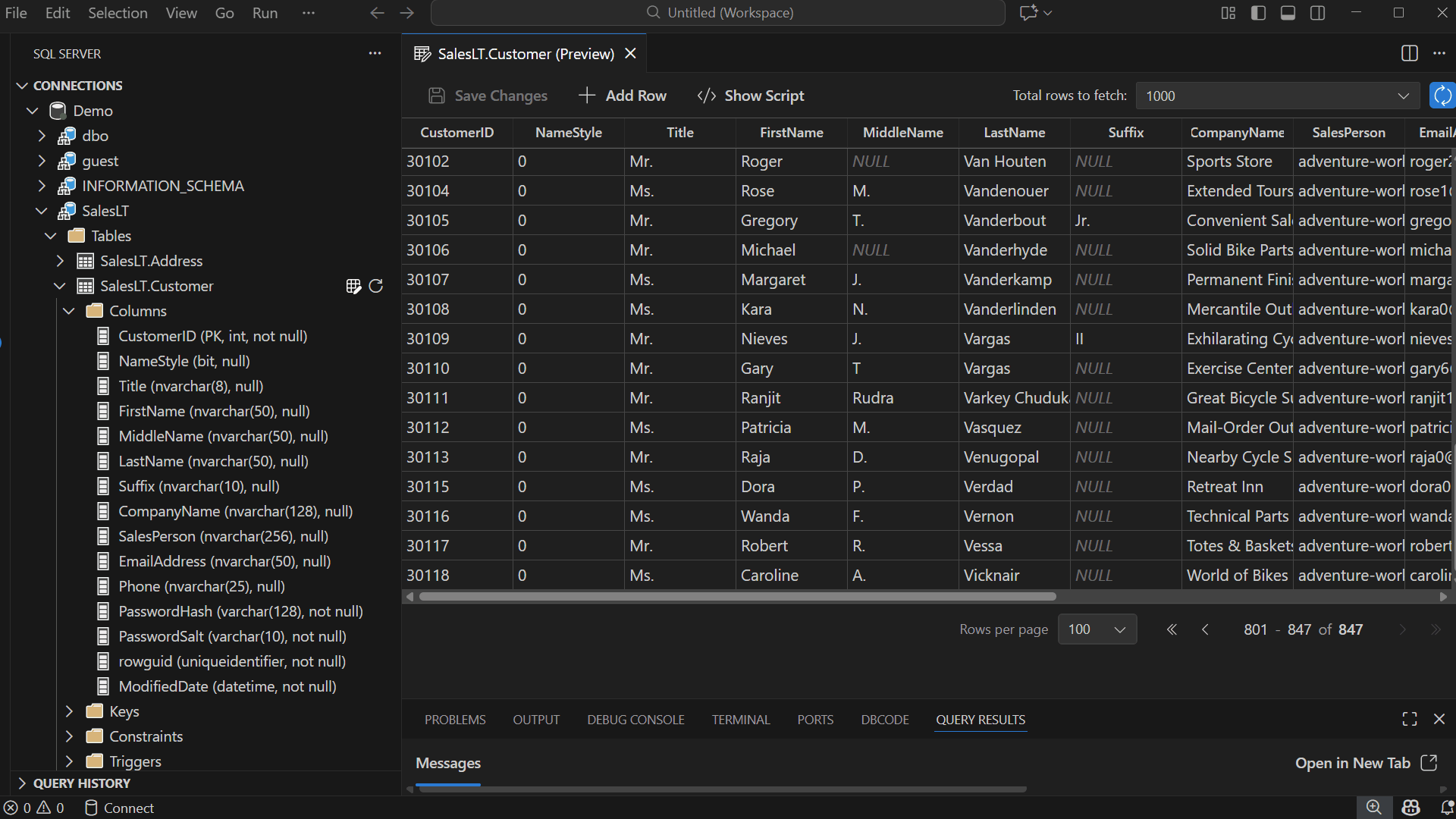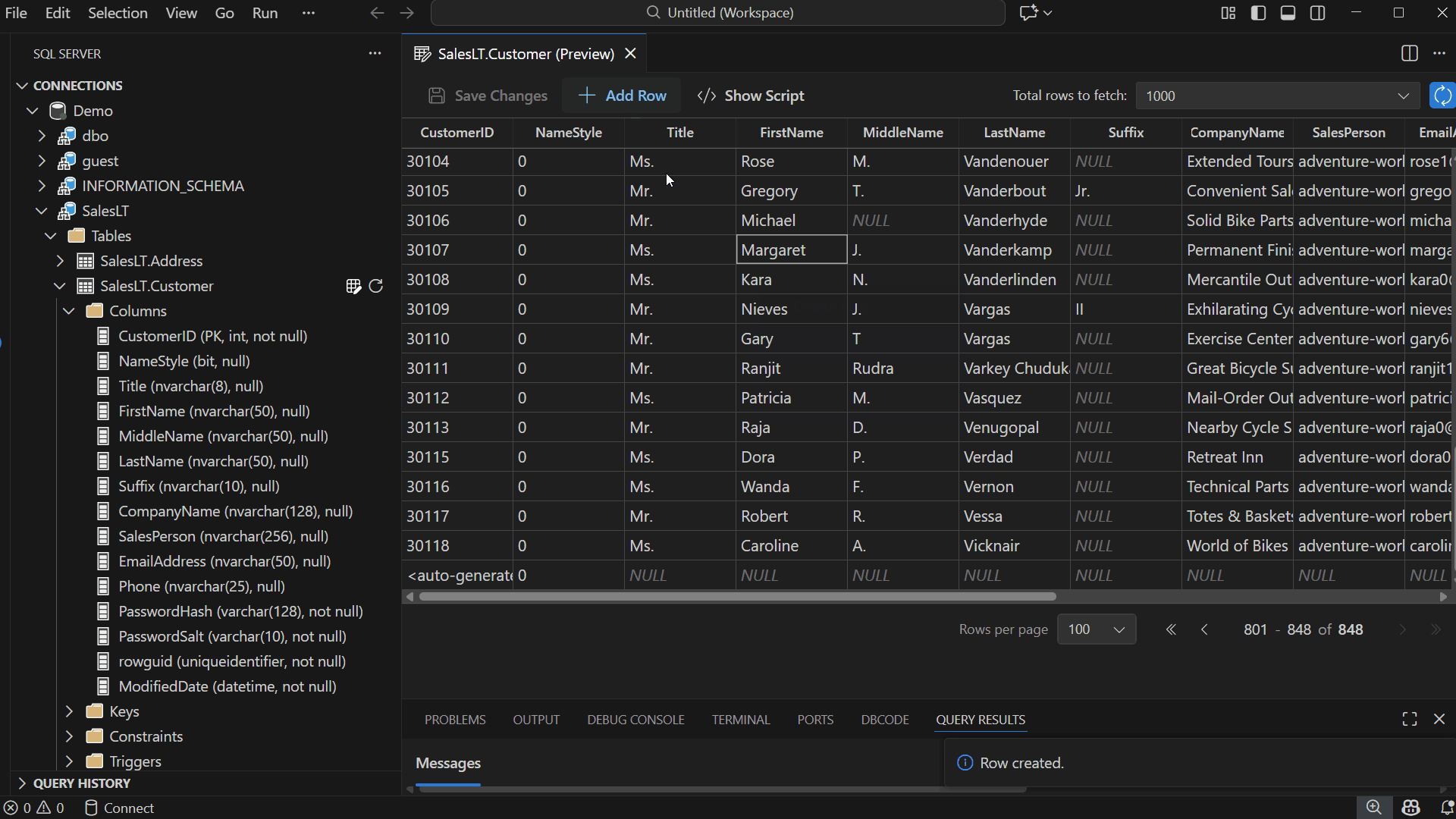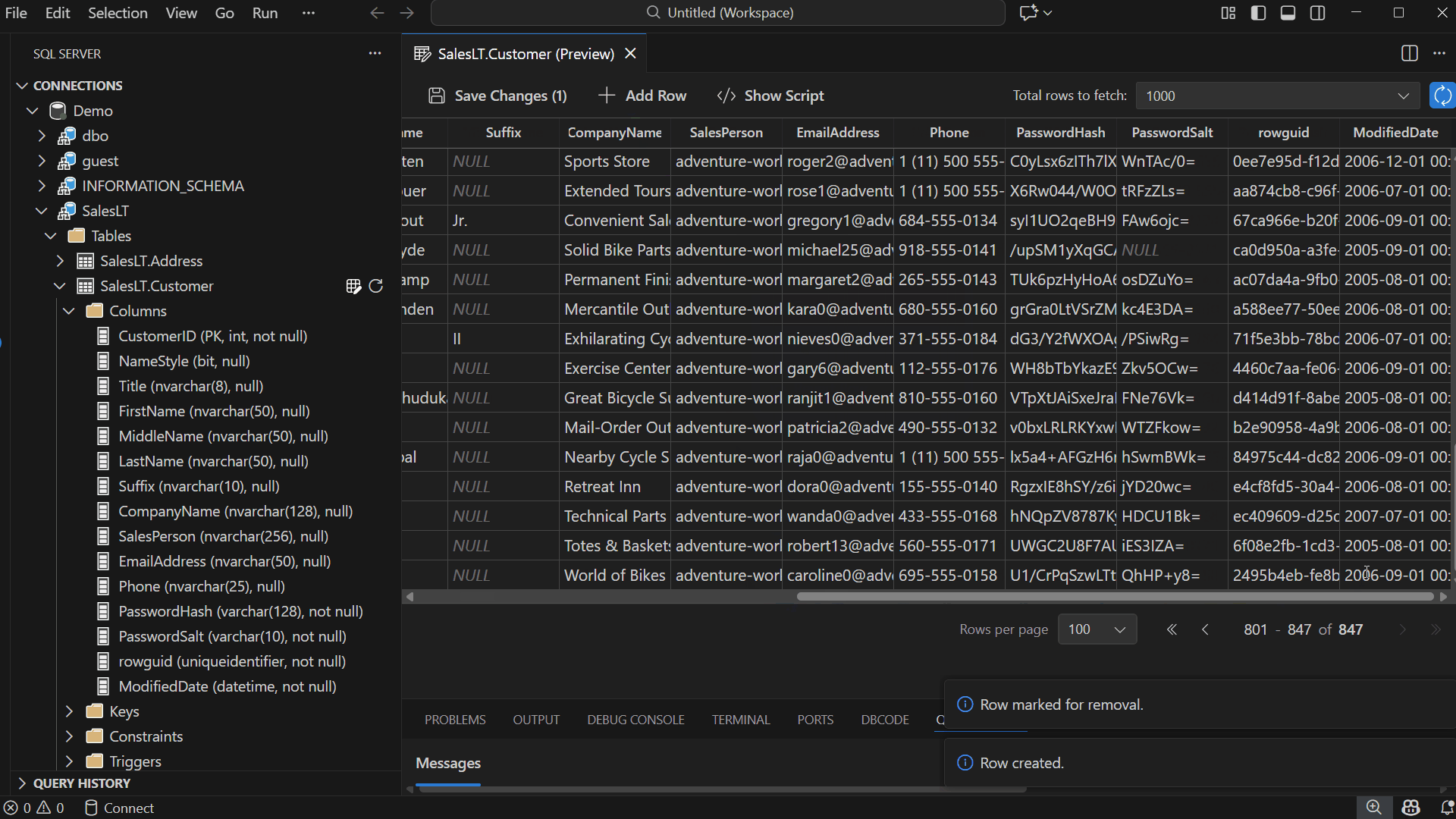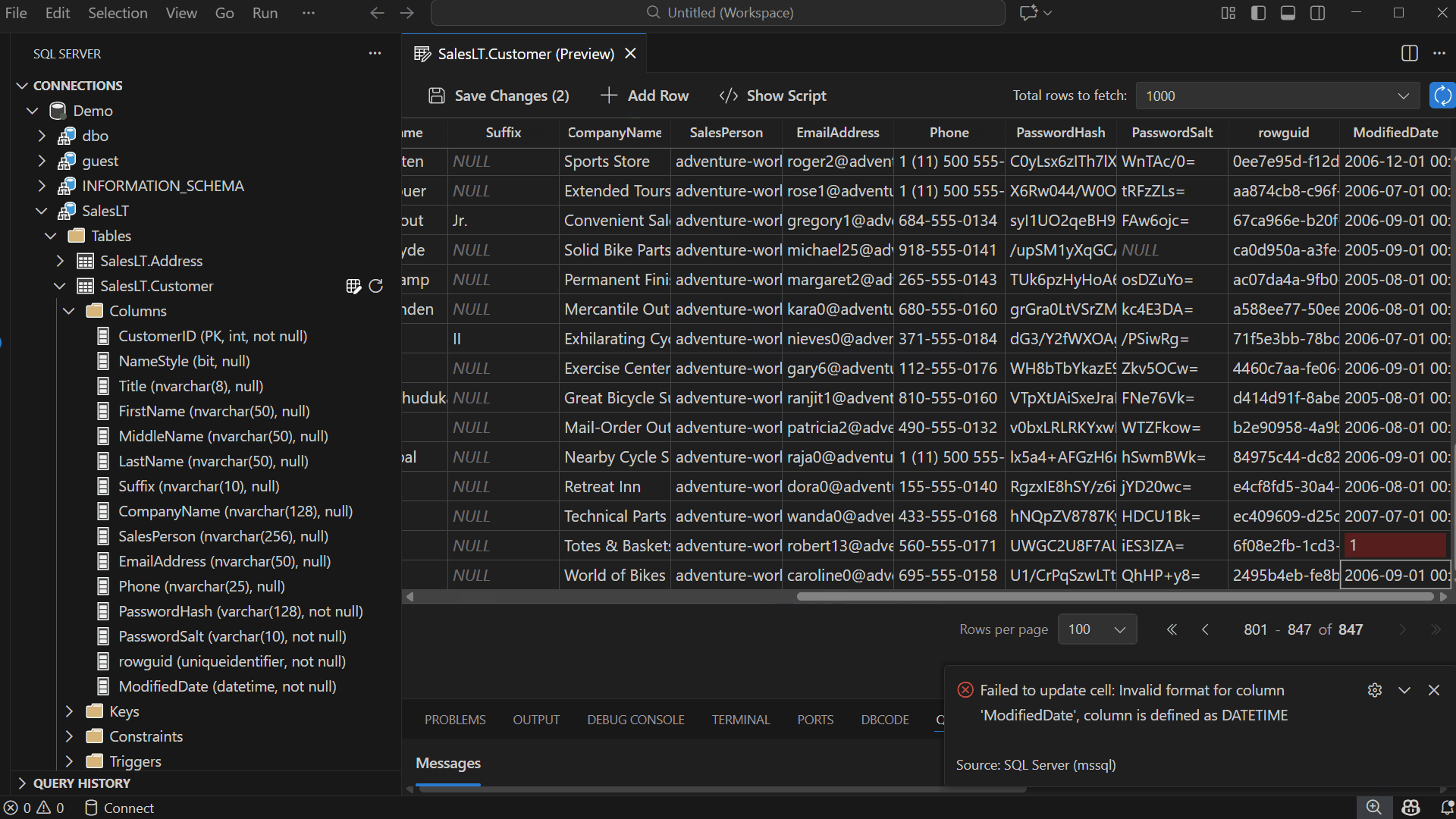
Once you edit a cell, your changes are validated immediately — even before saving. Edit Data (Preview) checks for invalid data types, unique or primary key violations, NULL values in non-nullable columns, and more. If an issue is detected, an error dialog appears to help you understand and resolve the problem.
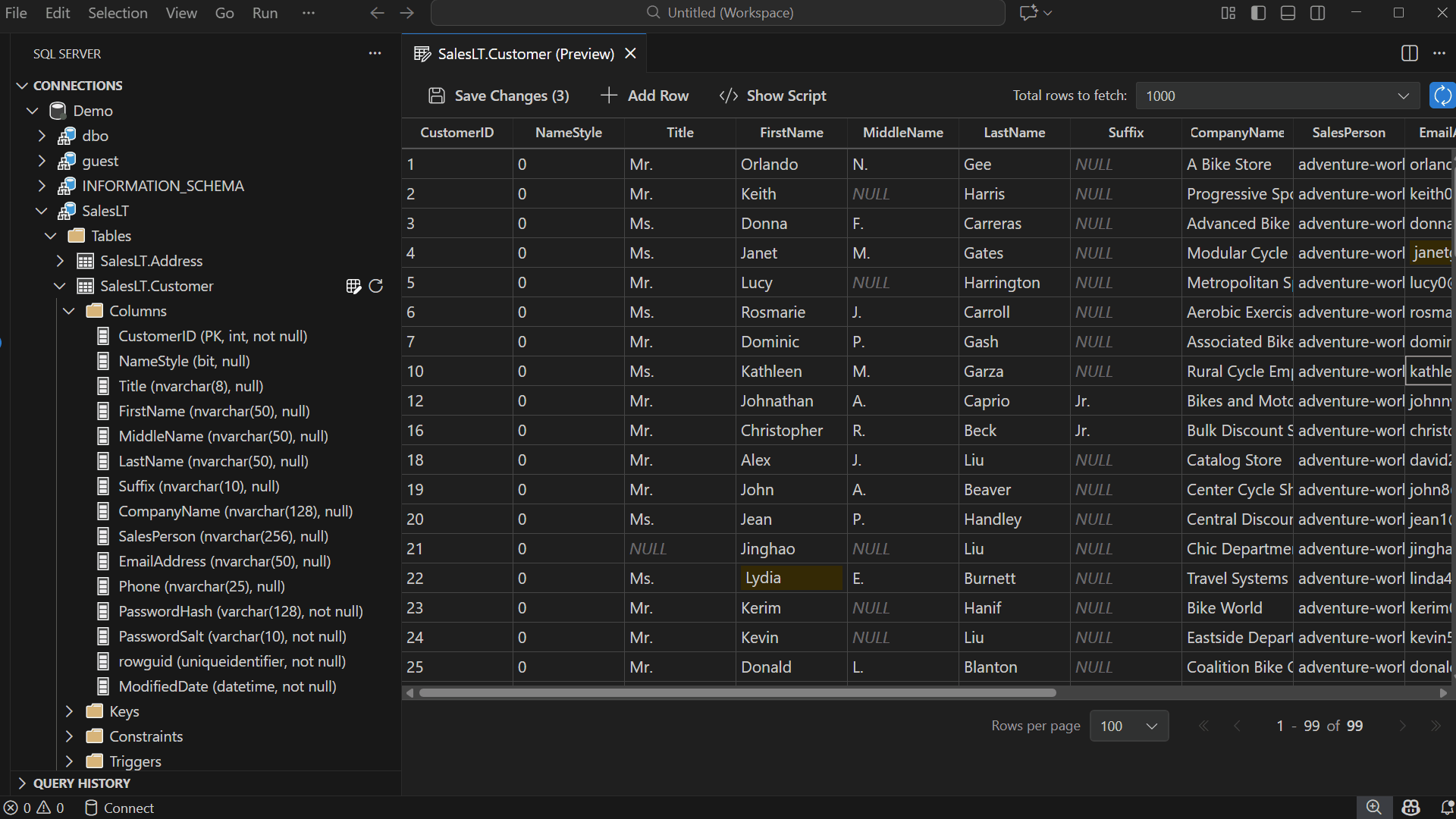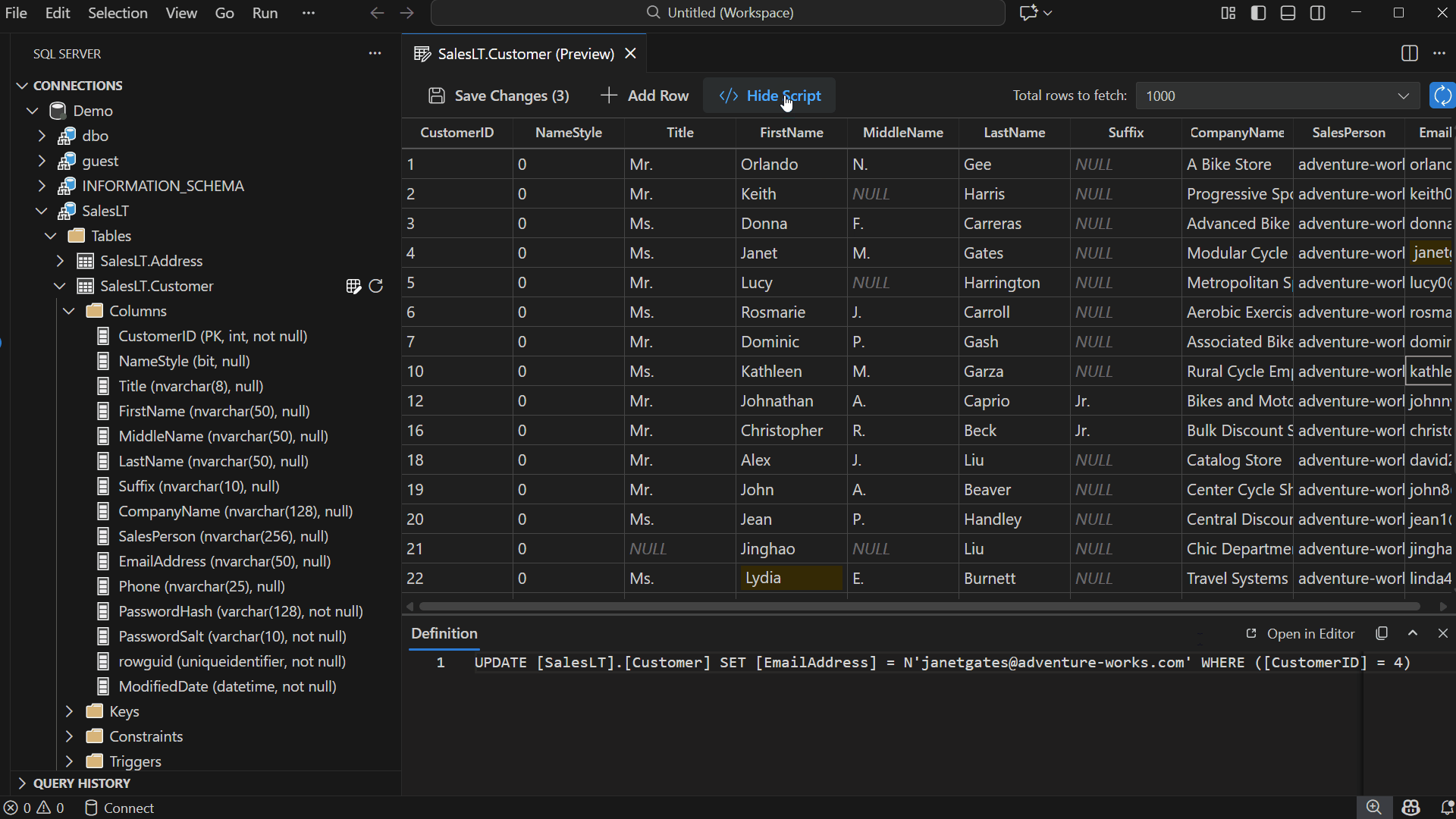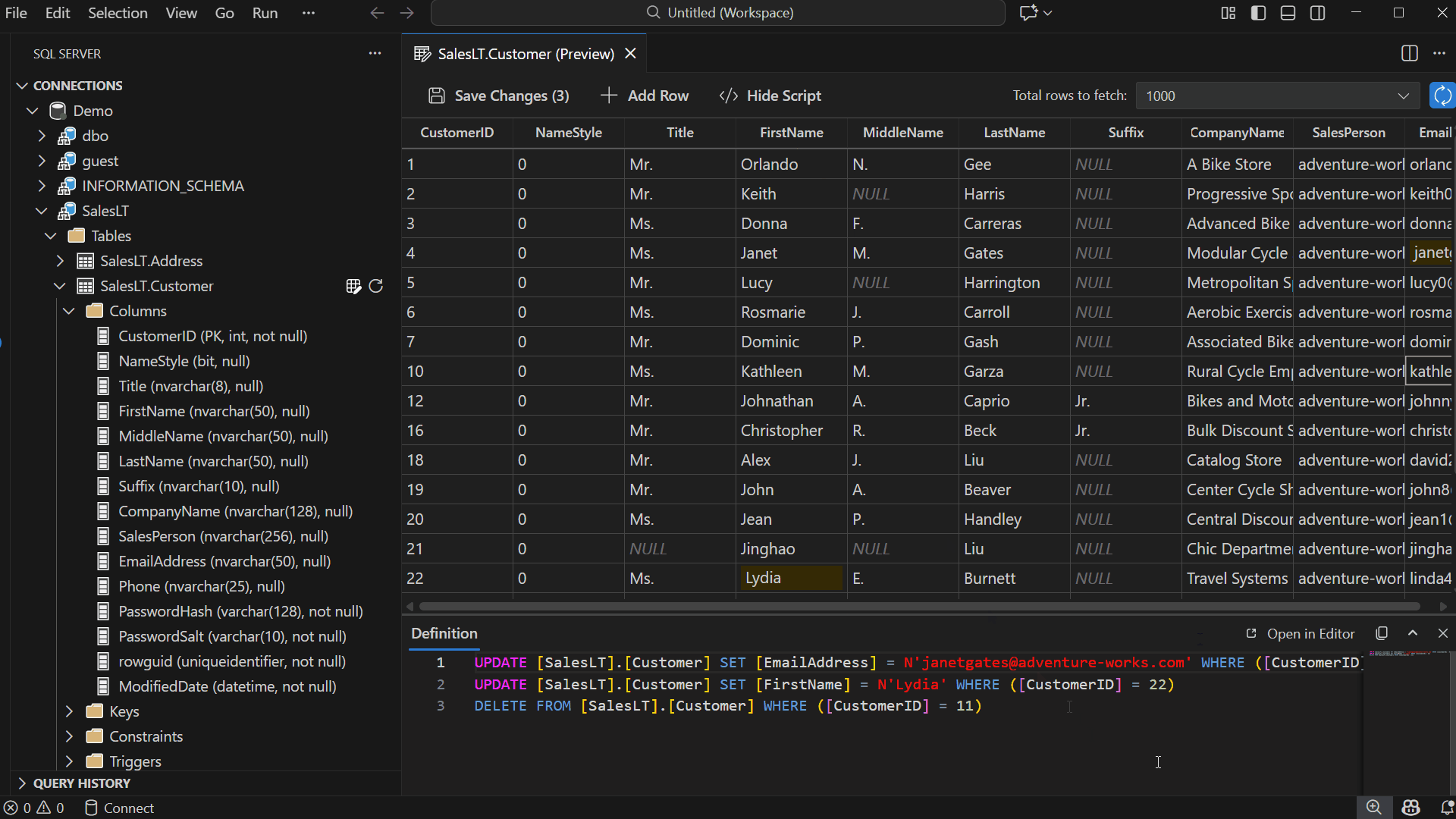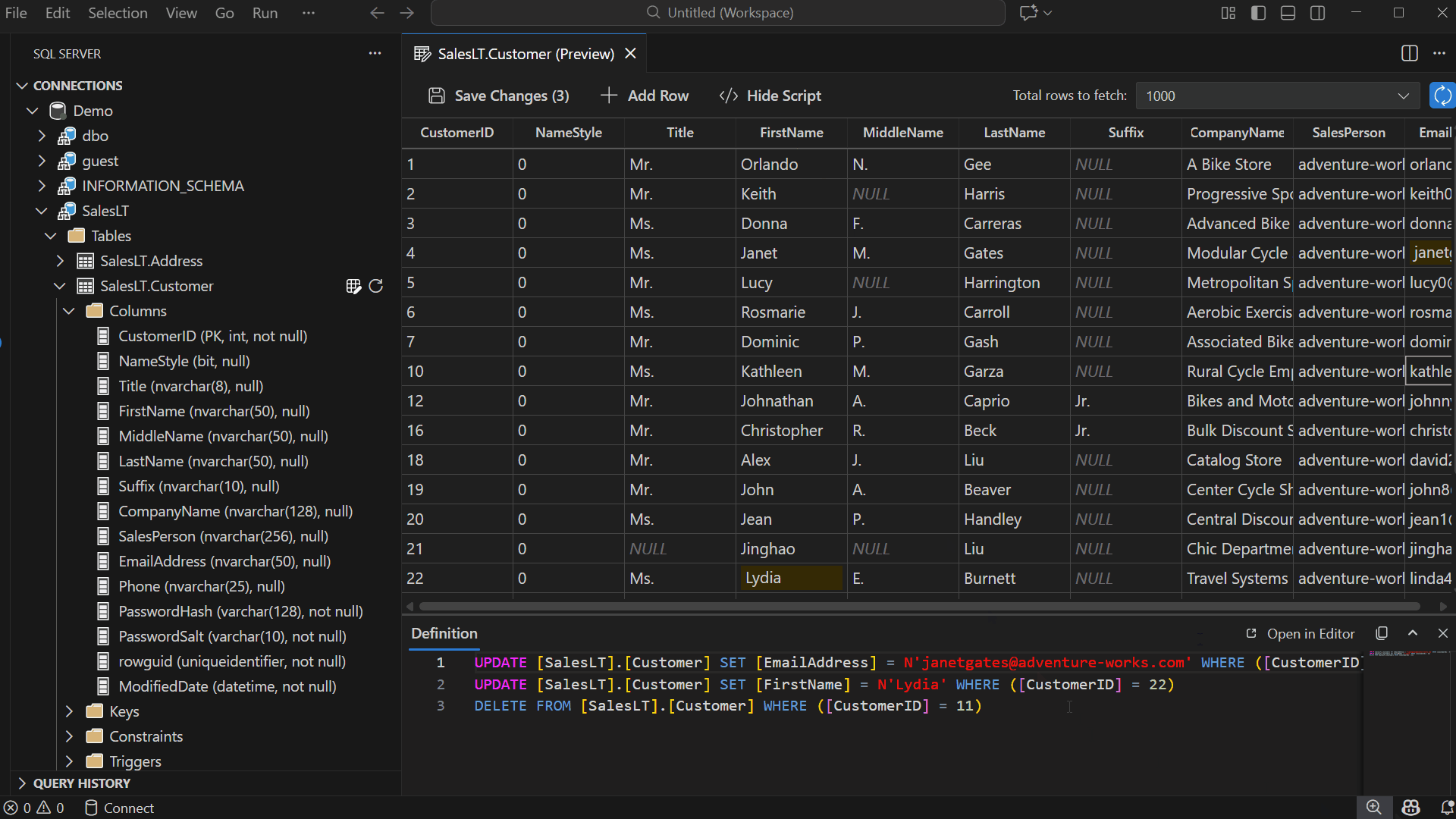
View Changes in Show Script Pane
Select Show Script in the toolbar to open a read-only pane displaying the DML generated by your edits — including INSERT, UPDATE, and DELETE statements.
The script updates automatically as you modify or revert data.
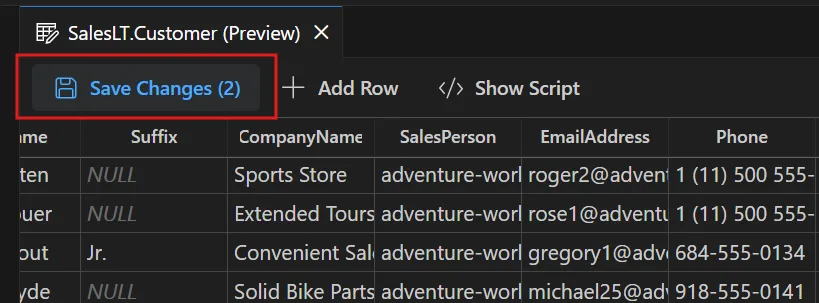
Save or Discard Changes
When ready, choose Save Changes to commit your updates.
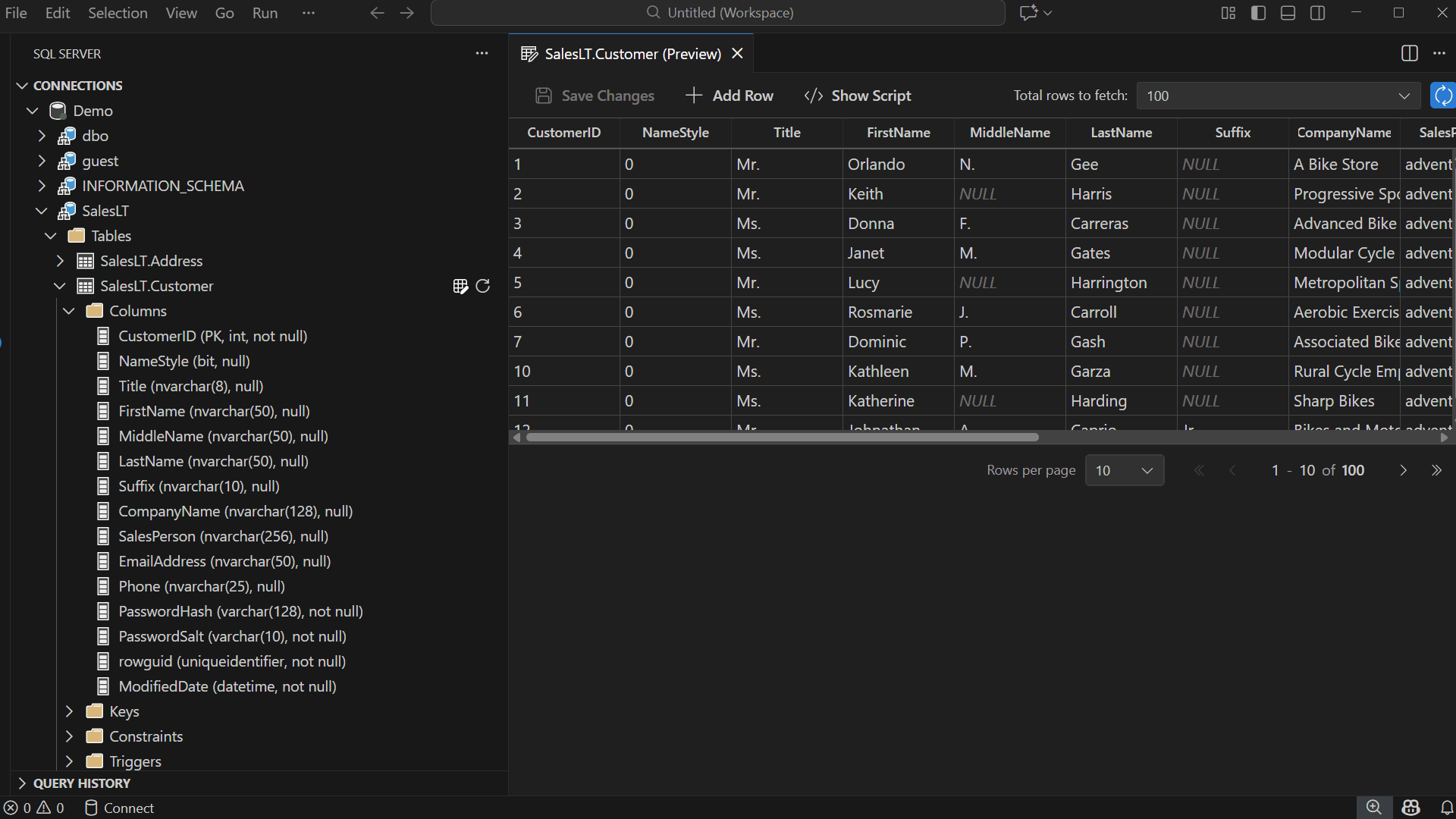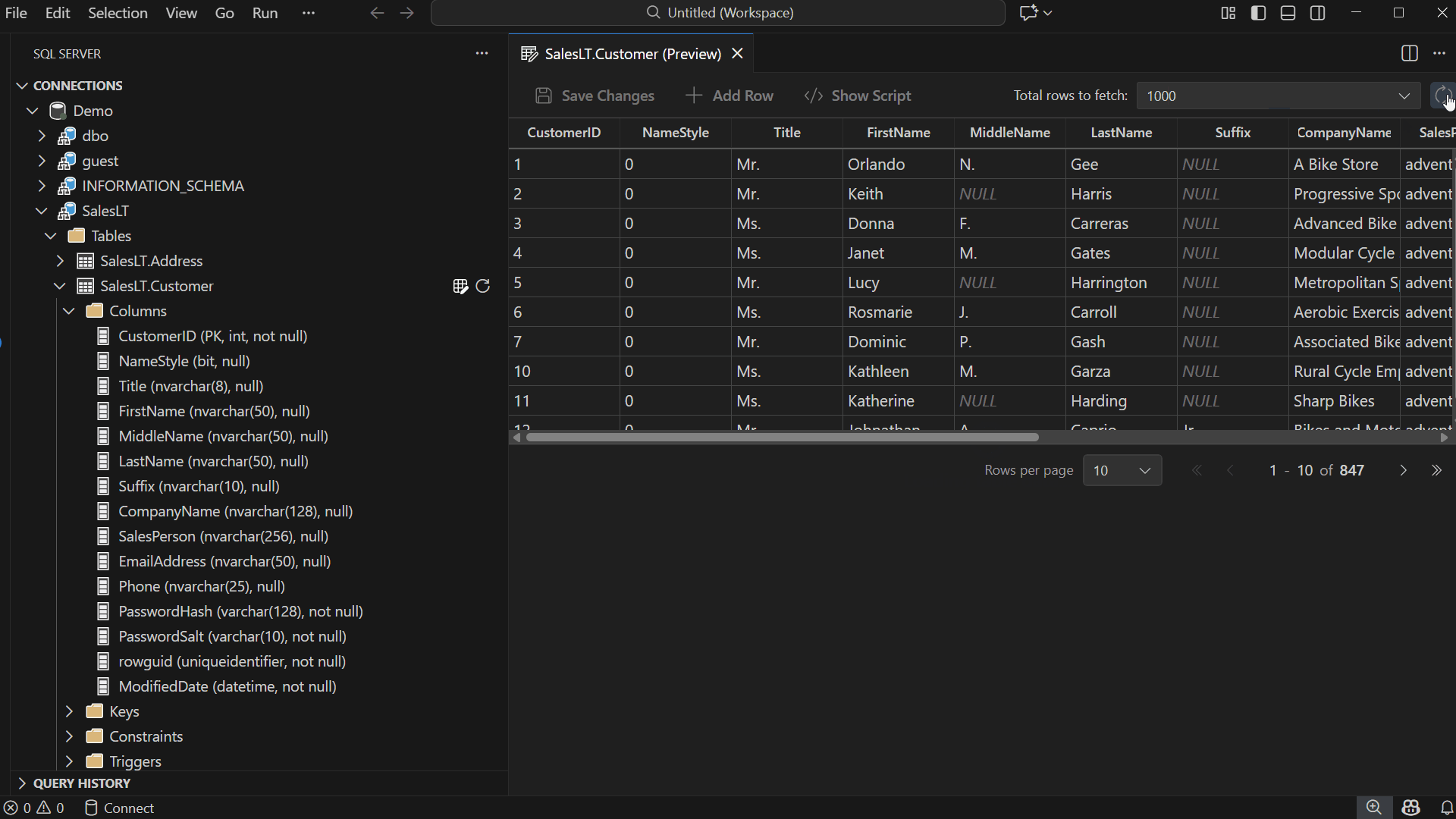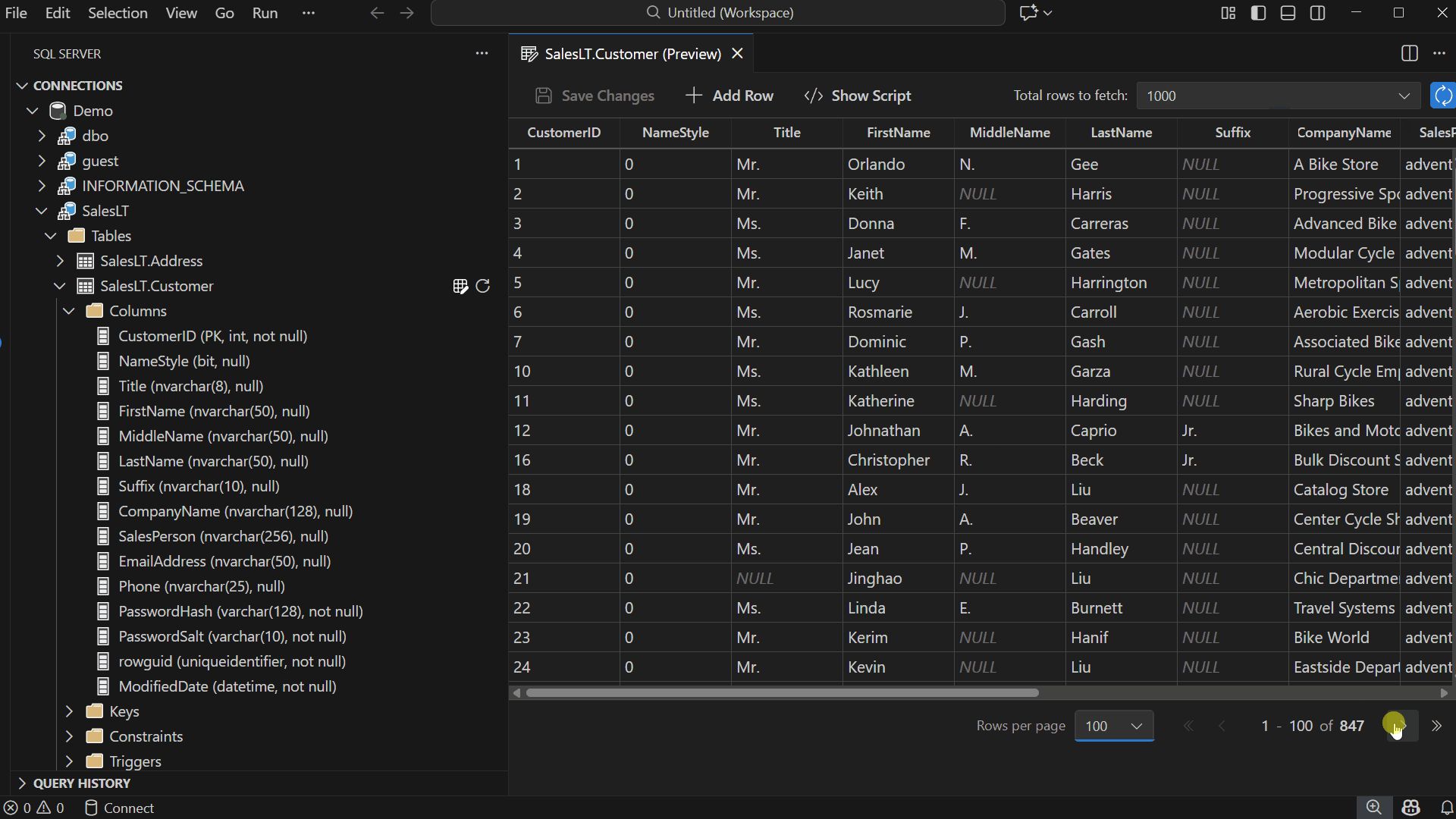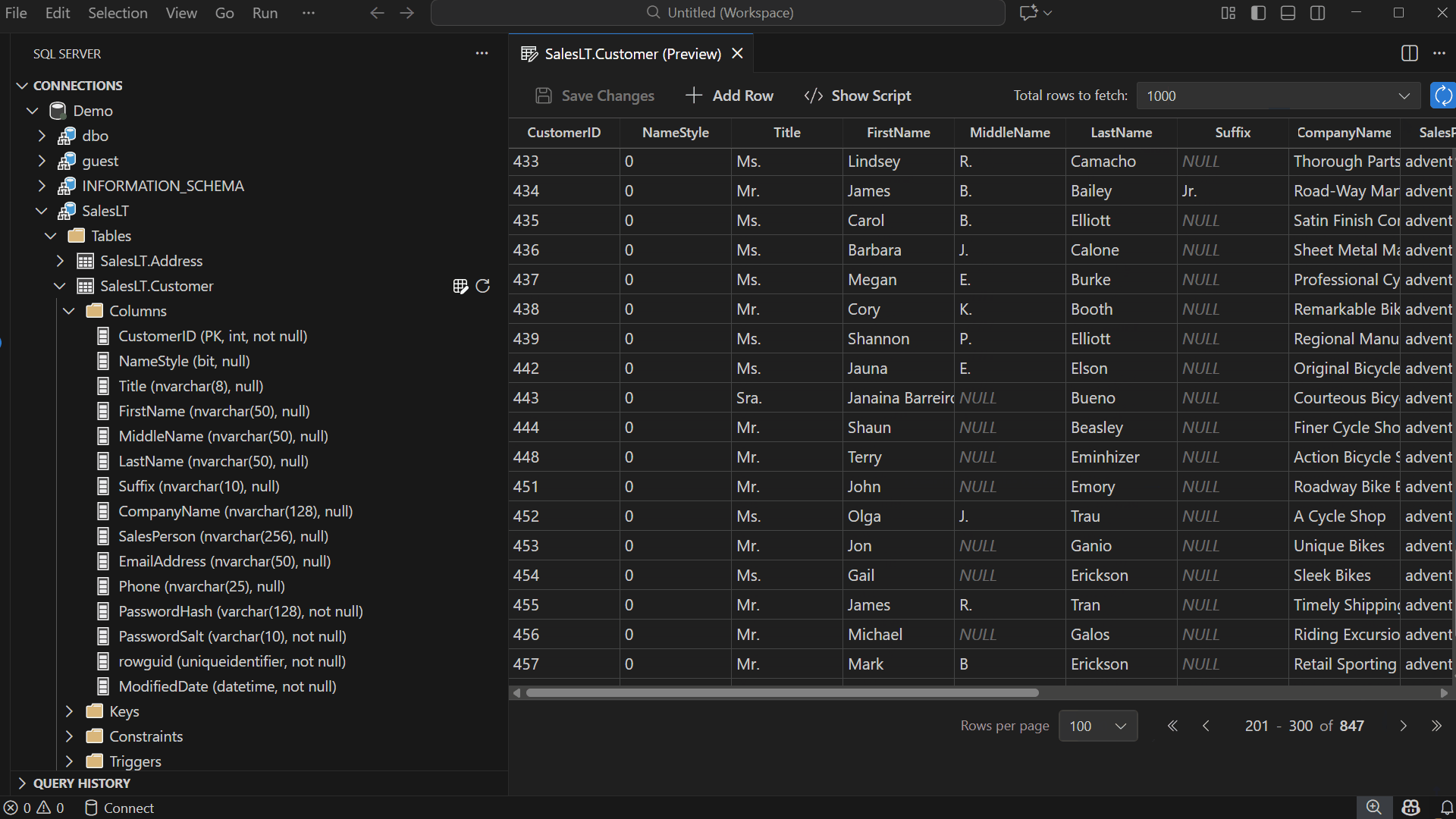
Pagination and Row Fetching
Edit Data is designed for smooth navigation across large datasets — modify Total rows to fetch, adjust Rows per page, navigate between pages — allowing you to locate records quickly.
Next Steps
Install the MSSQL extension for Visual Studio Code if you haven’t already: Learn how
Edit Data is still in Public Preview — and we are actively adding more capabilities, refining interactions, and enhancing performance. Your feedback right now is critical and directly shapes what we build next. Please share your thoughts — every piece of feedback helps!
Pushing the frontiers of computer-use agents with an open-weight, ultra-compact model, optimized for real-world web tasks
In 2024, Microsoft introduced small language models (SLMs) to customers, starting with the release of Phi (opens in new tab) models on Microsoft Foundry (opens in new tab), as well as deploying Phi Silica (opens in new tab) on Copilot+ PCs powered by Windows 11. Today, we are pleased to announce Fara-7B, our first agentic SLM designed specifically for computer use.
Unlike traditional chat models that generate text-based responses, Computer Use Agent (CUA) models like Fara-7B leverage computer interfaces, such as a mouse and keyboard, to complete tasks on behalf of users. With only 7 billion parameters, Fara-7B achieves state-of-the-art performance within its size class and is competitive with larger, more resource-intensive agentic systems that depend on prompting multiple large models. Fara-7B’s small size now makes it possible to run CUA models directly on devices. This results in reduced latency and improved privacy, as user data remains local.
Fara-7B is an experimental release, designed to invite hands-on exploration and feedback from the community. Users can build and test agentic experiences beyond pure research—automating everyday web tasks like filling out forms, searching for information, booking travel, or managing accounts. We recommend running Fara-7B in a sandboxed environment, monitoring its execution, and avoiding sensitive data or high-risk domains. Responsible use is essential as the model continues to evolve.
Fara-7B operates by visually perceiving a webpage and takes actions like scrolling, typing, and clicking on directly predicted coordinates. It does not rely on separate models to parse the screen, nor on any additional information like accessibility trees, and thus uses the same modalities as humans to interact with the computer. To train Fara-7B, we developed a novel synthetic data generation pipeline for multi-step web tasks, building on our prior work (AgentInstruct). This data generation pipeline draws from real web pages and tasks sourced from human users.
Video 1: A demo of a shopping scenario with Fara-7B through Magentic-UI. Fara-7B is asked to purchase an X-Box Spongebob controller. Fara-7B goes on to complete this task, but while doing so, also stops at every Critical Point to get input and approval from the user before proceeding.Video 2: A demo of Fara-7B finding relevant information online and summarizing it through Magentic-UI. We ask Fara-7B to find and summarize the latest three issues on Github Microsoft/Magentic-UI.Video 3: A demo of how Fara-7B can use different tools to find relevant information and analyze it through Magentic-UI. We ask Fara-7B to find driving time between two places, and suggest a cheese place near the location. Fara-7B uses Bing Maps to find Driving time, and Bing search to find relevant information.
Fara-7B exhibits strong performance compared to existing models across a diverse set of benchmarks. This includes both existing benchmarks as well as new evaluations we are releasing which cover useful task segments that are underrepresented in common benchmarks, such as finding job postings and comparing prices across retailers. While Fara-7B demonstrates strong benchmark results, even against much larger models, it shares many of their limitations, including challenges with accuracy on more complex tasks, mistakes in following instructions, and susceptibility to hallucinations. These are active areas of research, and we’re committed to ongoing improvements as we learn from real-world use.
By making Fara-7B open-weight, we aim to lower the barrier to experimenting with and improving CUA technology for automating routine web tasks, such as searching for information, shopping, and booking reservations.
Figure 1: Comparing WebVoyager accuracy and cost of Fara-7B to other computer use agents (CUAs) or agents that prompt LLMs with accessibility trees (SoM Agent w/ Ax Tree). Cost is computed by multiplying the average number of input and output tokens each model consumes by price per token. Both Fara-7B and UI-TARS-1.5-7B are based on Qwen-2.5-VL-7B, for which the lowest inference price from https://openrouter.ai/ is \(0.2/\)0.2 per 1M input/output tokens. Even though both models are priced equally, Fara-7B is more efficient, completing tasks with only ~16 steps on average compared to ~41 for UI-TARS-1.5-7B. OpenAI computer-use-preview accessed November 2025 via the Responses API.
Developing Fara-7B
CUA multi-agent synthetic data generation
A key bottleneck for building CUA models is a lack of large-scale, high-quality computer interaction data. Collecting such data with human annotators is prohibitively expensive as a single CUA task can involve dozens of steps, each of which needs to be annotated. Our data generation pipeline (Figure 2) avoids manual annotation and instead relies on scalable synthetic data sourced from publicly available websites and custom task prompts. We build this pipeline on top of the Magentic-One framework, and it involves three main stages:
Figure 2: Data Generation workflow from proposing tasks from various seeds like URLs to solving those tasks with the Magentic-One multi-agent framework to generate demonstrations for training, and finally verifiying/filtering completed trajectories
Task Proposal. We generate a broad set of synthetic tasks that mirror common user activities on the web. To ensure coverage and diversity, tasks are “seeded” by a web index of public URLs classified into various categories e.g., shopping, travel, restaurants, etc. This enables task generation targeting a particular skill, like “book 2 tickets to see the Downton Abbey Grand Finale at AMC Union Square, NYC.” from a URL like this (opens in new tab) classified as “movies”. As another strategy, we devised a way to generate tasks from randomly sampled URLs. Each task starts with a general prompt and is iteratively refined as an LLM agent explores the website and gathers more information about it. We are releasing a held-out subset of these tasks as a benchmark (“WebTailBench”), described in the Evaluation section below.
Task Solving. Once synthetic tasks are generated, a multi-agent system built on Magentic-One attempts to complete them to generate demonstrations for supervised finetuning. The multi-agent system uses an Orchestrator agent to create a plan and direct a WebSurfer agent to take browser actions and reports results. The Orchestrator monitors progress, updating plans as needed, and can end tasks or engage aUserSimulator agent if user input is required, allowing for multi-turn completion. Each task and corresponding sequence of observations, actions, and agent thoughts forms a “trajectory”.
Trajectory Verification. Before using any tasks for training, three verifier agents evaluate if a task was “successful”: The Alignment Verifier checks if the trajectory of actions match the task’s intent; the Rubric Verifier defines completion criteria and scores the trajectory against them; and the Multimodal Verifier reviews screenshots and responses to confirm visual evidence supports successful completion. Trajectories failing these standards are removed.
We ultimately train this version of Fara-7B on a dataset of 145,000 trajectories consisting of 1 million steps covering diverse websites, task types, and difficulty levels. Additionally, we include training data for several auxiliary tasks, including grounding for accurate UI element localization, captioning, and visual question answering.
Training Fara-7B
Using one compute use model is easier than a multi-agent system, particularly when it comes to deployment. Therefore, we distill the complexities of our multi-agent solving system into a single model that can execute tasks. Fara-7B is a proof-of-concept that small models can effectively learn from complex, multi-agent systems with lots of bells and whistles.
As shown in Figure 3, Fara-7B is trained to execute user tasks by perceiving only browser window screenshots (without relying on accessibility trees), and predicting single-step actions. For each step, the context used to make its prediction contains all user messages, the complete action history, and the latest three screenshots.
In its prediction, Fara-7B outputs a reasoning message (“thinking” about the next action) followed by a tool call. The available tools include standard Playwright (opens in new tab) mouse and keyboard actions, such as click(x,y) and type(), and browser-specific macro-actions like web_search() and visit_url().
Fara-7B uses Qwen2.5-VL-7B (opens in new tab) as its base model due to its strong performance on grounding tasks and its ability to support long contexts (up to 128k tokens). We linearize the solving pipeline’s trajectories into a sequence of “observe-think-act” steps that are suitable for training with supervised finetuning loss. We did not use reinforcement learning to achieve the results we report below.
Figure 3: Operation of Fara-7B as a standalone, native computer use agent running on-device. Because Fara-7B is small, and none of its context needs to leave your personal device, it paves the way for personal and private agentic computing
Evaluations
We evaluate Fara-7B and comparable baselines on canonical public benchmarks including WebVoyager (opens in new tab), Online-Mind2Web (opens in new tab), and Deepshop (opens in new tab), as well as a new benchmark we developed named WebTailBench, specifically focusing on 11 real-world task types underrepresented or missing in existing benchmarks like booking movie/event tickets, restaurant reservations, comparing prices across retailers, applying for jobs, finding real estate, and more complex multi-step tasks.
Evaluation of web agents can be tricky because the web is constantly changing, and many websites even block detected bots, which is why we developed a test harness that relies on BrowserBase (opens in new tab) to standardize how browser sessions are managed. In Table 1 below, we report a notion of task success rate (%) defined by each benchmark’s official LLM-as-judge evaluator; WebTailBench success is computed using the same Task Verification pipeline that filtered our training data. We find that Fara-7B is state-of-the-art, even outperforming native computer use agents like UI-TARS-1.5-7B, or much larger models like GPT-4o prompted to act like a computer use agent with Set-Of-Marks (opens in new tab) (SoM Agent).
WebVoyager
Online-Mind2Web
DeepShop
WebTailBench
SoM Agents
SoM Agent (GPT-4o)
65.1
34.6
16.0
30.0
GLM-4.1V-9B-Thinking
66.8
33.9
32.0
22.4
Computer Use Models
OpenAI computer-use-preview
70.9
42.9
24.7
25.7
UI-TARS-1.5-7B
66.4
31.3
11.6
19.5
Fara-7B
73.5
34.1
26.2
38.4
Table 1: Performance comparison across four web benchmarks: WebVoyager, Online-Mind2Web, DeepShop, and our newly introduced WebTailBench. Results are reported as Task Succes Rate / Accuracy (%) and are averaged over 3 runs. OpenAI computer-use-preview accessed November 2025 via the Responses API.
In Figure 1, we expand on the Webvoyager results by giving each model up to three chances to complete a task, and report “pass@K”. We also consider on the x-axis the cost of running each model if one were to pay market rates for input/output tokens consumed. Fara-7B breaks ground on a new pareto frontier, showing that on-device computer use agents are approaching the capabilities of frontier models.
We partnered with a trusted external group, Browserbase, to independently evaluate Fara-7B using human annotators. The model achieved 62% on WebVoyager (see detailed reports in Browserbase blog here (opens in new tab)). These results were generated in the same environment with identical settings and human verification of each task, making them directly comparable. Note that Browserbase’s standard WebVoyager scores do not use retries when environment errors occur; the results referenced here include retries and should not be compared directly to the non-retry scores. Going forward, we are collaborating with Browserbase to host WebTailBench human evaluations to help the community build reliable and reproducible assessments for computer use agents.
Safety
Agents capable of operating computers present challenges distinct from chat-only models, including new outlets of user misuse, model misbehavior, and unintended consequences of actions, and external risks like prompt injections or online scams. CUAs take action with real-world consequences, so ensuring robust safety measures is essential to their responsible deployment. Transparency and user control sit at the core of Fara-7B’s design. Although we have incorporated several safety measures, Fara-7B remains a research preview, and we continue to advance our approach to safety for computer use agents, an active area of work across the entire AI community.
Fara-7B processes browser screenshots, user task instructions, and a history of actions taken during each session and collects only what is necessary to complete the user’s requested task. No additional site data—such as accessibility trees or external scaffolding—is accessed; Fara-7B interacts with the computer in the same way a human would, relying solely on what is visible on the screen.
All actions taken by the agent are logged and auditable, allowing users to review and monitor every step. For added safety, Fara‑7B is intended to run in sandboxed environments, giving users full oversight and the ability to intervene or halt actions at any time. These safeguards ensure that privacy, transparency, and user control remain at the core of every interaction.
To address misuse, we trained Fara-7B on a mixture of public safety data and internally generated tasks that it ought to refuse based on Microsoft’s Responsible AI Policy. We evaluated Fara-7B’s ability to refuse harmful tasks on WebTailBench-Refusals which consists of 111 red-teaming tasks showing a high refusal rate of 82%. The model also underwent Microsoft’s rigorous red teaming process, where we focused on the model rejecting harmful tasks and risky tasks, such as harmful content, jailbreaking attempts, ungrounded responses, and prompt injections. For further details, check out our technical report (opens in new tab).
To mitigate the risk of Fara-7B taking unintended actions, all of Fara-7B’s training data enforces both recognizing and stopping at “Critical Points” when executing a task. A Critical Point (see Operator System Card (opens in new tab)) is any situation that requires the user’s personal data or consent before engaging in a transaction or irreversible action like sending an email. Upon reaching a Critical Point, Fara-7B should respond by informing the user it cannot proceed without their consent.
For guidance on how to use our model safely, and the security considerations to be mindful of when using our model, please refer to our Model card (opens in new tab).
How to use
Fara-7B is available on (opens in new tab)Microsoft Foundry (opens in new tab)and (opens in new tab)Hugging Face (opens in new tab). We are also releasing the implementation of Fara-7B in Magentic-UI, so that users can try it in a contained environment through the inference code provided. Additionally, users can download the model for Copilot+ PCs powered by Windows 11 from the AI Toolkit in VSCode and run it all on-device, taking advantage of NPU hardware acceleration.
Looking forward
Our current release is an experimental CUA model that achieves state-of-the-art results for its size, purely using supervised fine-tuning. We believe even stronger CUA models capable of running on-device are possible through improved multimodal base models and through Reinforcement Learning on live and sandboxed environments. These early days are about learning from the community and driving real-world experimentation to shape what comes next. If you’d like to join us and help shape the future of SLMs, please apply for open roles.
Acknowledgements:
We thank Gustavo de Rosa, Adam Fourney, Michael Harrison, Rafah Hosn, Neel Joshi, Ece Kamar, John Langford, Maya Murad, Sidhartha Sen, Pratyusha Sharma, and Lili Wu for their valuable help, insightful discussions, and continued support throughout this work.
We also thank Pashmina Cameron, Karthik Vijayan, Vicente Rivera, Chris Dern, Sayan Shaw, Sunghoon Choi, Andrey Rybalchenko, and Vivek Pradeep for their efforts in making the model available on Copilot+ PCs through the AI Toolkit.
Announced at Microsoft Ignite 2025, Project Opal is a new way to get task-based work done. It combines an advanced reasoning model, computer use, and Windows 365 Cloud PC to tackle the time-consuming tasks and busywork that fill your day.
Here are the capabilities:
Task-First Experience: Start new jobs, re-run previous ones, or pick curated suggestions—all observable and steerable.
Advanced Reasoning Model: Turns your request into a dynamic plan, sequences the right tools, and adapts mid flow to complete the job.
Computer-Use: Executes certain steps in Microsoft Edge within a compliant Windows 365 for Agents Cloud PC.
Real-Time Observability: Watch jobs live or review later with a detailed plan, replay view, and activity timeline.
Steerability: Get notified when input is needed, take control, provide info, and let Opal resume.
Admin Controls & Security: Opt in with granular admin controls including allow lists, scenario starters, and context.
Demo of Project Opal: Automate web workflow & activity with natural language AI
Just like they did two years ago, the U.S. Patent and Trademark Office has once again proposed new rules that would make it much harder to challenge bad patents through inter partes review (IPR). But this time the rule is much worse for developers and startups. And that’s a serious concern.
Congress created IPRs so those most vulnerable to weaponized patents–startups and developers–could challenge whether a patent should have even been granted efficiently and fairly without the cost of a full-blown federal litigation. Preserving that ability strengthens American innovation, open source, and small-business growth.
The 2023 proposal would have added procedural hurdles. But even with those hurdles developers and startups would still always have their own path to challenge low-quality patents.
The 2025 proposal is different. It would impose bright-line rules that block IPR petitions in many common scenarios—such as when a claim has ever been upheld in any forum or when a parallel case is likely to finish first. It would also require petitioners to give up all invalidity defenses in court if they pursue IPR. These changes would prevent developers from challenging the patent whenever some other party tried and failed. This makes IPR far less accessible, increasing litigation risk and costs for developers, startups, and open source projects.
Innovation isn’t about patents—it’s about people writing code, collaborating, and building tools that power the world. GitHub’s inclusion in the WIPO Global Innovation Index reflects how developers and openness drive progress. Policies that close off avenues to challenge bad patents that block open innovation don’t just affect lawyers—they affect the entire ecosystem that makes innovation possible.
We’re calling on developers, startups, and open source organizations that could be impacted by these rules to file comments underscoring the broad concerns patent trolls pose to innovation. File a comment and make your voice heard before the comment period closes on December 2.
Phil shows how to have your unit tests execute automatically and in real time as your make code changes.
⌚ Chapters: 00:00 Welcome 01:30 General discussion on testing 04:30 Review of demo app that will be tested 06:25 Starting and configuring Live Unit Testing 07:10 Demo of using Live Unit Testing 11:30 Discussion of performance implications 13:20 Configuring Live Unit Testing to skip tests and assemblies 17:45 Using a .runsettings file to configure how unit tests are run 19:45 Discussion of benefits 21:00 Wrap-up