It’s an intricately detailed Death Star nearly two feet tall (52.3cm), a foot and a half wide (48cm) and over a foot (38.3cm) deep, with enough compartments to re-enact nearly every iconic Death Star scene from Star Wars and Return of the Jedi.
We’ve never seen a Lego set anywhere near this expensive. When the $999.99, €999.99 or £899.99 price and images leaked in July, many wondered how the Lego Group could possibly justify such a price for plastic toys!
“$850 Millennium Falcons and $680 Titanics: Grown-Ups Are Now a Gold Mine for Lego,” The Wall Street Journalwrote last year. “Lego bricks have won over adults, growing its $10 billion toy market foothold,” added Fortune, writing that roughly 15 percent of Lego’s sets are aimed at adults. In my experience, that isn’t just because adults like to play with minifigs. Building is a relaxing diversion, a way to de-stress, and then you have a piece of home decor and a sense of accomplishment when you’re done.
But whether you’re looking for decor or a playset, this Death Star looks like an incredible one.
Instead of offering a spherical Death Star like earlier, blockier playsets, the new Ultimate Collectors Series (UCS) Death Star is a vertical slice, a diorama set like the Batcave Shadowbox that can live on a shelf with all rooms visible at once.
Almost every iconic scene is accounted for here, from the hangar bay where Darth Vader and a squad of stormtroopers can greet the Emperor arriving in the included Imperial Shuttle, to the detention block AA-23 shootout and escape, to the garbage compactor scare, to the comms room where R2-D2 and C-3PO wait and helpfully shut that compactor down.
Meanwhile, Vader can find a disturbing lack of faith in the conference room, Obi-Wan Kenobi can go tackle the tractor beam, while Luke and Leia swing across the chasm overhead; you get superlaser targeting and control rooms for Leia to give up Dantooine, and a turbolift to take minifigs to each of six different levels. Then, Luke can have his Return of the Jedi showdown with Vader and the Emperor and his Red Guards in his throne room at the end.
Luke and Han can also be multiple places simultaneously: the 38 minifigures include both “aren’t you a little short for a Stormtrooper” and Return of the Jedi versions of Luke as well as his original outfit, plus Stormtrooper and traditional vest versions of Han. Lego says there’s even a stormtrooper in a hot tub as an easter egg.
As excited as I am, I’m afraid it’s too rich for my blood, but I won’t echo some complaints that Lego isn’t even giving us a full spherical Death Star for $1,000.
I would prefer it this way, if it didn’t cost so much — because unlike the $850 Millennium Falcon, I could actually fit it in my home. Even though there isn’t enough room inside the hangar bay for a minifig-scale Millennium Falcon, or a full platoon of Stormtroopers, I can place them right next to this set and imagine they’re enclosed within — just like I’d imagine the rest of the Death Star’s reactor shaft after I send the Emperor over the railing to his doom.
The UCS Death Star will go up for sale on October 1st for Lego Insiders (it’s a free signup) or October 4th for everyone else. There’s a chance for Lego Insiders to win one starting today by spending 50 rewards points, and there’s a “while supplies last” promo gift for the first buyers: a “set with a Tie Fighter with Imperial Hanger Rack.”
Join Luke Wroblewski and Ben Lorica as they talk about the future of software development. What happens when we have databases that are designed to interact with agents and language models rather than humans? We’re starting to see what that world will look like. It’s an exciting time to be a software developer.
About the Generative AI in the Real World podcast: In 2023, ChatGPT put AI on everyone’s agenda. In 2025, the challenge will be turning those agendas into reality. In Generative AI in the Real World, Ben Lorica interviews leaders who are building with AI. Learn from their experience to help put AI to work in your enterprise.
Check out other episodes of this podcast on the O’Reilly learning platform.
Timestamps
0:00: Introduction to Luke Wroblewski of Sutter Hill Ventures.
0:36: You’ve talked about a paradigm shift in how we write applications. You’ve said that all we need is a URL and model, and that’s an app. Has anyone else made a similar observation? Have you noticed substantial apps that look like this?
1:08: The future is here; it’s just not evenly distributed yet. That’s what everyone loves to say. The first websites looked nothing like robust web applications, and now we have a multimedia podcast studio running in the browser. We’re at the phase where some of these things look and feel less robust. And our ideas for what constitutes an application change in each of these phases. If I told you pre-Google Maps that we’d be running all of our web applications in a browser, you’d have laughed at me.
2:13: I think what you mean is an MCP server, and the model itself is the application, correct?
2:24: Yes. The current definition of an application, in a simple form, is running code and a database. We’re at the stage where you have AI coding agents that can handle the coding part. But we haven’t really had databases that have been designed for the way those agents think about code and interacting with data.
2:57: Now that we have databases that work the way agents work, you can take out the running-code part almost. People go to Lovable or Cursor and they’re forced to look at code syntax. But if an AI model can just use a database effectively, it takes the role of the running code. And if it can manage data visualizations and UI, you don’t need to touch the code. You just need to point the AI at a data structure it can use effectively. MCP UI is a nice example of people pushing in this direction.
4:12: Which brings us to something you announced recently: AgentDB. You can find it at agentdb.dev. What problem is AgentDB trying to solve?
4:34: Related to what we were just talking about: How do we get AI agents to use databases effectively? Most things in the technology stack are made for humans and the scale at which humans operate.
5:06: They’re still designed for a DBA, but eliminating the command line, right? So you still have to have an understanding of DBA principles?
5:19: How do you pick between the different compute options? How do you pick a region? What are the security options? And it’s not something you’re going to do thousands of times a day. Databricks just shared some stats where they said that thousands of databases per agent get made a day. They think 99% of databases being made are going to be made by agents. What is making all these databases? No longer humans. And the scale at which they make them—thousands is a lowball number. It will be way, way higher than that. How do we make a database system that works in that reality?
6:22: So the high-level thesis here is that lots of people will be creating agents, and these agents will rely on something that looks like a database, and many of these people won’t be hardcore engineers. What else?
6:45: It’s also agents creating agents, and agents creating applications, and agents deciding they need a database to complete a task. The explosion of these smart machine uses and workflows is well underway. But we don’t have an infrastructure that was made for that world. They were all designed to work with humans.
7:31: So in the classic database world, you’d consider AgentDB more like OLTP rather than analytics and OLAP.
7:42: Yeah, for analytics you’d probably stick your log somewhere else. The characteristics that make AgentDB really interesting for agents is, number 1: To create a database, all you really need is a unique ID. The creation of the ID manifests a database out of thin air. And we store it as a file, so you can scale like crazy. And all of these databases are fully isolated. They’re also downloadable, deletable, releasable—all the characteristics of a filesystem. We also have the concept of a template that comes along with the database. That gives the AI model or agent all the context it needs to start using the database immediately. If you just point Claude at a database, it will need to look at the structure (schema). It will build tokens and time trying to get the structure of the information. And every time it does this is an opportunity to make a mistake. With AgentDB, when an agent or an AI model is pointed at the database with a template, it can immediately write a query because we have in there a description of the database, the schema. So you save time, cut down errors, and don’t have to go through that learning step every time the model touches a database.
10:22: I assume this database will have some of the features you like, like ACID, vector search. So what kinds of applications have people built using AgentDB?
10:53: We put up a little demo page where we allow you to start the process with a CSV file. You upload it, and it will create the database and give you an MCP URL. So people are doing things like personal finance. People are uploading their credit card statements, their bank statements, because those applications are horrendous.
11:39: So it’s the actual statement; it parses it?
11:45: Another example: Someone has a spreadsheet to track jobs. They can take that, upload it, it gives them a template and a database and an MCP URL. They can pop that job-tracking database into Claude and do all the things you can do with a chat app, like ask, “What did I look at most recently?”
12:35: Do you envision it more like a DuckDB, more embedded, not really intended for really heavy transactional, high-throughput, more-than-one-table complicated schemas?
12:49: We currently support DuckDB and SQLite. But there are a bunch of folks who have made multiple table apps and databases.
13:09: So it’s not meant for you to build your own CRM?
13:18: Actually, one of our go-to-market guys had data of people visiting the website. He can dump that as a spreadsheet. He has data of people starring repos on GitHub. He has data of people who reached out through this form. He has all of these inbound signals of customers. So he took those, dropped them in as CSV files, put it in Claude, and then he can say, “Look at these, search the web for information about these, add it to the database, sort it by priority, assign it to different reps.” It’s CRM-ish already, but super-customized to his particular use case.
14:27: So you can create basically an agentic Airtable.
14:38: This means if you’re building AI applications or databases—traditionally that has been somewhat painful. This removes all that friction.
15:00: Yes, and it leads to a different way of making apps. You take that CSV file, you take that MCP URL, and you have a chat app.
15:17: Even though it’s accessible to regular users, it’s something developers should consider, right?
15:25: We’re starting to see emergent end-user use cases, but what we put out there is for developers.
15:38: One of the other things you’ve talked about is the notion that software development has flipped. Can you explain that to our listeners?
15:56: I spent eight and a half years at Google, four and a half at Yahoo, two and a half at ebay, and your traditional process of what we’re going to do next is up front: There’s a lot of drawing pictures and stuff. We had to scope engineering time. A lot of the stuff was front-loaded to figure out what we were going to build. Now with things like AI agents, you can build it and then start thinking about how it integrates inside the project. At a lot of our companies that are working with AI coding agents, I think this naturally starts to happen, that there’s a manifestation of the technology that helps you think through what the design should be, how do we integrate into the product, should we launch this? This is what I mean by “flipped.”
17:41: If I’m in a company like a big bank, does this mean that engineers are running ahead?
17:55: I don’t know if it’s happening in big banks yet, but it’s definitely happening in startup companies. And design teams have to think through “Here’s a bunch of stuff, let me do a wash across all that to fit in,” as opposed to spending time designing it earlier. There are pros and cons to both of these. The engineers were cleaning up the details in the previous world. Now the opposite is true: I’ve built it, now I need to design it.
18:55: Does this imply a new role? There’s a new skill set that designers have to develop?
19:07: There’s been this debate about “Should designers code?” Over the years lots of things have reduced the barrier to entry, and now we have an even more dramatic reduction. I’ve always been of the mindset that if you understand the medium, you will make better things. Now there’s even less of a reason not to do it.
19:50: Anecdotally, what I’m observing is that the people who come from product are able to build something, but I haven’t heard as many engineers thinking about design. What are the AI tools for doing that?
20:19: I hear the same thing. What I hope remains uncommoditized is taste. I’ve found that it’s very hard to teach taste to people. If I have a designer who is a good systems thinker but doesn’t have the gestalt of the visual design layer, I haven’t been able to teach that to them. But I have been able to find people with a clear sense of taste from diverse design backgrounds and get them on board with interaction design and systems thinking and applications.
21:02: If you’re a young person and you’re skilled, you can go into either design or software engineering. Of course, now you’re reading articles saying “forget about software engineering.” I haven’t seen articles saying “forget about design.”
21:31: I disagree with the idea that it’s a bad time to be an engineer. It’s never been more exciting.
21:46: But you have to be open to that. If you’re a curmudgeon, you’re going to be in trouble.
21:53: This happens with every technical platform transition. I spent so many years during the smartphone boom hearing people say, “No one is ever going to watch TV and movies on mobile.” Is it an affinity to the past, or a sense of doubt about the future? Every time, it’s been the same thing.
22:37: One way to think of AgentDB is like a wedge. It addresses one clear pain point in the stack that people have to grapple with. So what’s next? Is it Kubernetes?
23:09: I don’t want to go near that one! The broader context of how applications are changing—how do I create a coherent product that people understand how to use, that has aesthetics, that has a personality?—is a very wide-open question. There’s a bunch of other systems that have not been made for AI models. A simple example is search APIs. Search APIs are basically structured the same way as results pages. Here’s your 10 blue links. But an agentic model can suck up so much information. Not only should you be giving it the web page, you should be giving it the whole site. Those systems are not built for this world at all. You can go down the list of the things we use as core infrastructure and think about how they were made for a human, not the capabilities of an enormous large language model.
24:39: Right now, I’m writing an article on enterprise search, and one of things people don’t realize is that it’s broken. In terms of AgentDB, do you worry about things like security, governance? There’s another place black hat attackers can go after.
25:20: Absolutely. All new technologies have the light side and the dark side. It’s always been a codebreaker-codemaker stack. That doesn’t change. The attack vectors are different and, in the early stages, we don’t know what they are, so it is a cat and mouse game. There was an era when spam in email was terrible; your mailbox would be full of spam and you manually had to mark things as junk. Now you use gmail, and you don’t think about it. When was the last time you went into the junk mail tab? We built systems, we got smarter, and the average person doesn’t think about it.
26:31: As you have more people building agents, and agents building agents, you have data governance, access control; suddenly you have AgentDB artifacts all over the place.
27:06: Two things here. This is an underappreciated part of this. Two years ago I launched my own personal chatbot that works off my writings. People ask me what model am I using, and how is it built? Those are partly interesting questions. But the real work in that system is constantly looking at the questions people are asking, and evaluating whether or not it responded well. I’m constantly course-correcting the system. That’s the work that a lot of people don’t do. But the thing I’m doing is applying taste, applying a perspective, defining what “good” is. For a lot of systems like enterprise search, it’s like, “We deployed the technology.” How do you know if it’s good or not? Is someone in there constantly tweaking and tuning? What makes Google Search so good? It’s constantly being re-evaluated. Or Google Translate—was this translation good or bad? Baked in early on.
When we build software, we’re not just shipping features. We’re shipping experiences that surprise and delight our users — and making sure that we’re providing natural and seamless experiences is a core part of what we do.
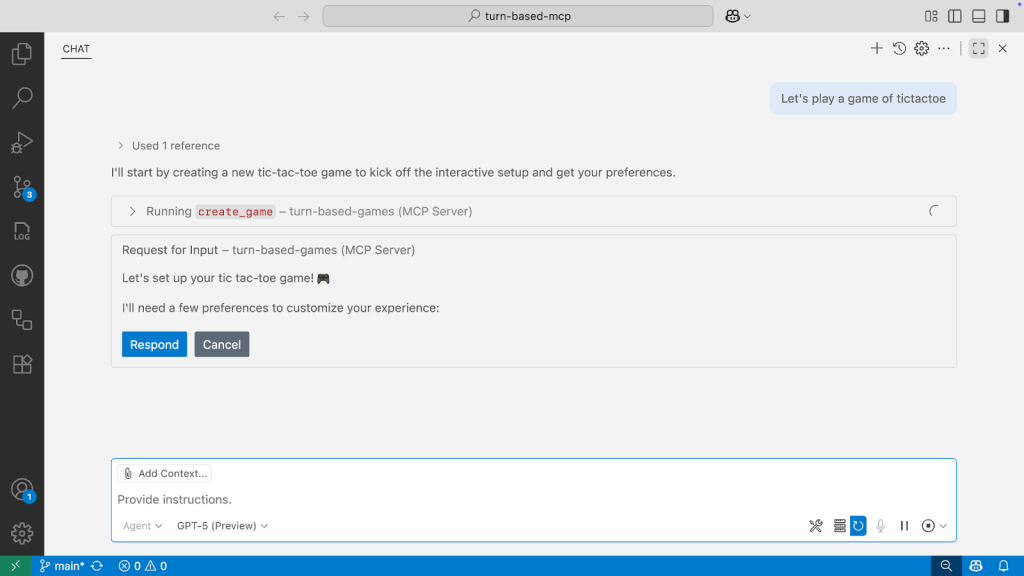
In my last post, I wrote about an MCP server that we started building for a turn-based-game (like tic-tac-toe, or rock, paper, scissors). While it had the core capabilities, like tool calls, resources, and prompts, the experience could still be improved. For example, the player always took the first move, the player could only change the difficulty if they specified in their initial message, and a slew of other papercuts.
So on my most recent Rubber Duck Thursdays stream, I covered a feature that’s helped improve the user experience: elicitation. See the full stream below 👇
Elicitation is kind of like saying, “if we don’t have all the information we need, let’s go and get it.” But it’s more than that. It’s about creating intuitive interactions where the AI (via the MCP server) can pause, ask for what it needs, and then continue with the task. No more default assumptions that provide hard-coded paths of interaction.
👀 Be aware: Elicitation is not supported by all AI application hosts. GitHub Copilot in Visual Studio Code supports it, but you’ll want to check the latest state from the MCP docs for other AI apps. Elicitation is a relative newcomer to the MCP spec, having been added in the June 2025 revision, and so the design may continue to evolve.
Let me walk you through how I implemented elicitation in my turn-based game MCP server and the challenges I encountered along the way.
Enter elicitation: Making AI interactions feel natural
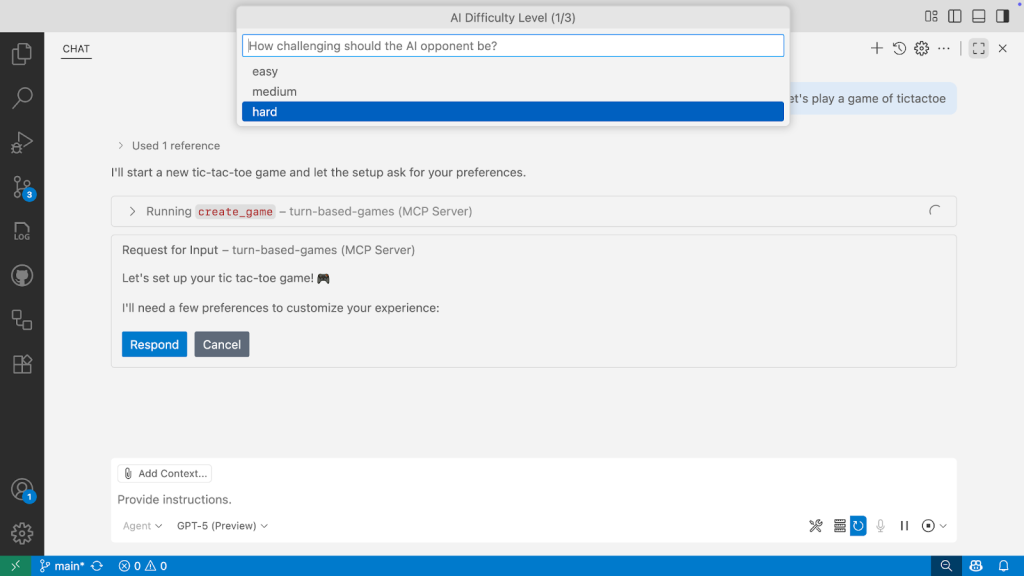
Before we reached the livestream, I had put together a basic implementation of elicitation, which asked for required information when creating a new game, like difficulty and player name. For tic-tac-toe, it asks which player goes first. For rock, paper, scissors, it asked how many rounds to play.
But rather than completely replacing our existing tools, I implemented these as new tools, so we could clearly see the behavior between the two approaches until we tested and standardized the approach. As a result, we began to see sprawl in the server with some duplicative tools:
create-tic-tac-toe-game and create-tic-tac-toe-game-interactive
create-rock-paper-scissors-game and create-rock-paper-scissors-game-interactive
play-tic-tac-toe and play-rock-paper-scissors
The problem? When you give AI agents like Copilot tools with similar names and descriptions, it doesn’t know which one to pick. On several occasions, Copilot chose the wrong tool because I had created this confusing landscape of overlapping functionality. This was an unexpected learning experience, but an important one to pick up along the way.
The next logical step was to consolidate our tool calls, and make sure we’re using DRY (don’t repeat yourself) principles throughout the codebase instead of redefining constants and having nearly identical implementations for different game types.
After a lot of refactoring and consolidation, when someone prompts “let’s play a game of tic-tac-toe,” the tool call identifies that more information is needed to ensure the user has made an explicit choice, rather than creating a game with a pre-determined set of defaults.
The user provides their preferences, and the server creates the game based upon those, improving that overall user experience.
It’s worth adding that my code (like I’m sure many of us would admit?) is far from perfect, and I noticed a bug live on the stream. The elicitation step triggered for every invocation of the tool, regardless of whether the user had already provided the needed information.
As part of my rework after the livestream, I added some checks after the tool was invoked to determine what information had already been provided. I also aligned the property names between the tool and elicitation schemas, bringing a bit more clarity. So if you said “Let’s play a game of tic-tac-toe, I’ll go first,” you would be asked to confirm the game difficulty and to provide your name.
How my elicitation implementation now works under the hood
The magic happens in the MCP server implementation. As part of my up-to-date implementation, when the MCP server invokes the create_game tool, it:
Initiates elicitation: If information is missing, it pauses the tool execution and gathers only the missing information from the user. This was an addition that I made after the stream to further improve the user experience.
Collects responses: The MCP client (VS Code in this case) handles the UI interaction.
Completes the original request: Once the server collects all the information, the tool executes the createGame method with the user’s preferences.
Here’s what you see in the VS Code interface when elicitation kicks in, and you must provide some preferences:
The result? Instead of “Player vs AI (Medium)”, I get “Chris vs AI (Hard)” with the AI making the opening move because I chose to go second.
What I learned while implementing elicitation
Challenge 1: Tool naming confusion
Problem: Tools with similar names and descriptions confuse the AI about which one to use.
Solution: Where it’s appropriate, merge tools and use clear, distinct names and descriptions. I went from eight tools down to four:
create-game (handles all game types with elicitation)
play-game (unified play interface)
analyze-game (game state analysis)
wait-for-player-move (turn management)
Challenge 2: Handling partial information
Problem: What if the user provides some information upfront? (“Let’s play tic-tac-toe on hard mode”)
Observation: During the livestream, we saw that the way I built elicitation asked for all of the preferences each time it was invoked, which is not an ideal user experience.
Solution: Parse the initial request and only elicit the missing information. This was fixed after the livestream, and is now in the latest version of the sample.
Key lessons from this development session
1. User experience is still a consideration with MCP servers
How often do you provide all the needed information straight up? Elicitation provides this capability, but you need to consider how this is included as part of your tool calling and overall MCP experience. It can add complexity, but is it better to ask users for their preferences than force them to work around poor defaults?
2. Tool naming matters more than you think
When building (and even using) tools in MCP servers, naming and descriptions are critical. Ambiguous tool names and similar descriptions can lead to unpredictable behavior, where the “wrong” tool is called.
3. Iterative development wins
Rather than trying to build the perfect implementation upfront, I iterated to:
Build basic functionality first
Identify pain points through usage
Add elicitation to improve the user experience
Use Copilot coding agent and Copilot agent mode to help cleanup
Try it yourself
Want to see how elicitation works in an MCP server? Or seeking inspiration to build your own MCP server?
Set up your dev environment by creating a GitHub Codespace
Run the sample by building the code, starting the MCP server and running the web app / API server.
Take this with you
Building better AI tools isn’t all about the underlying models — it’s about creating experiences that can interpret context, ask good questions, and deliver exactly what users need. Elicitation is a step in that direction, and I’m excited to see how the MCP ecosystem continues to evolve and support even richer interactions.
Join us for the next Rubber Duck Thursdays stream where we’ll continue exploring the intersection of AI tools and developer experience.
Hey everyone! We’re thrilled to invite you to the fifth edition of JetBrains JavaScript Day – a free online event for everyone passionate about JavaScript.
Five years in, we’re celebrating by bringing together some of the most inspiring voices in the JavaScript world. They’ll share their stories, ideas, and lessons learned – giving you practical insights to help you stay ahead in a rapidly evolving ecosystem. Make sure to join us live to ask your questions and be a part of the conversation as it happens.
Many developers have run into subtle issues with annotations when working with Kotlin and frameworks like Spring or JPA-based persistence frameworks. For instance, an annotation applied to a constructor parameter might not always end up in the property or backing field where the framework expects it.
This often means annotations don’t land where they’re needed. For example, bean validation checks might only happen when the object was first created, but not when its properties were later updated. The result? Confusing bugs, surprising runtime behavior, and sometimes even the need to dig into bytecode to see what’s really going on. For example, validation might not be enforced when entities are loaded or updated from the database.
With Kotlin 2.2, we’re addressing this problem. A new default rule makes annotations land where developers expect them to, reducing boilerplate and aligning better with popular frameworks.
Consider this simple JPA entity:
@Entity
class Order(
@Id
@GeneratedValue
val id: Long,
@NotBlank
var name: String,
@Email
var email: String
)
At first glance this looks correct. But in Kotlin versions before 2.2, the default rule applied these annotations only to the constructor parameter (@param).
If we look at the decompiled code, it actually becomes:
public class Order {
@Id
@GeneratedValue
private final long id;
@NotNull
private String name;
@NotNull
private String email;
public Order(long id, @NotBlank @NotNull String name, @Email @NotNull String email) {
Intrinsics.checkNotNullParameter(name, "name");
Intrinsics.checkNotNullParameter(email, "email");
super();
this.id = id;
this.name = name;
this.email = email;
}
…
}
Validation annotations like @NotBlank and @Email weren’t placed on the field/property – they only validated object construction, not property updates.
This mismatch has been a common source of confusion.
Previous workaround: Explicit use-site targets
The fix was to explicitly mark the targets, for example with @field:
@Entity
class Order(
@field:Id
@GeneratedValue
val id: Long,
@field:NotNull
var name: String,
@field:Email
var email: String
)
so that becomes:
public class Order {
@Id
@GeneratedValue
private final long id;
@NotBlank
@NotNull
private String name;
@Email
@NotNull
private String email;
…
}
This approach works, but clutters the code with extra syntax. It also requires developers to know about Kotlin’s use-site targets and remember which one each framework expects.
Kotlin 2.2: A new default that just works
Starting with Kotlin 2.2, annotations without an explicit use-site target are applied to the constructor parameter and the property or field, aligning behavior with what most frameworks expect.
That means our original code now works as expected, without requiring any additional annotations:
@Entity
class Order(
@Id
@GeneratedValue
val id: Long,
@NotBlank
var name: String,
@Email
var email: String
)
With the new rule:
Bean validation annotations are present on the property, so validation applies on updates as well as on constructions.
The code looks like clean and idiomatic Kotlin, without repetitive @field: syntax or surprising behavior.
How to enable the new behavior
🔗 Kotlin 2.2 is required.
By default, the compiler issues warnings if your code’s behavior may change under the new rule.
In IntelliJ IDEA, you can also use the quick-fix on a warning to enable the new default project-wide.
To switch fully to the new behavior in your project, enable it in IntelliJ IDEA via Gradle’s settings.
Add the following to your build.gradle.kts:
kotlin {
compilerOptions {
freeCompilerArgs.add("-Xannotation-default-target=param-property")
}
}
If you prefer to keep the old behavior, you can use:
kotlin {
compilerOptions {
freeCompilerArgs.add("-Xannotation-defaulting=first-only")
}
}
This change makes annotation behavior more predictable, reduces boilerplate, and eliminates a class of subtle bugs that Spring and JPA developers have faced for years. It’s also a step toward making Kotlin’s integration with major frameworks smoother.
This update is part of our broader initiative to improve the Kotlin + Spring experience. Stay tuned for more inspections, tooling improvements, and language updates that make working with these frameworks even better.
Copilot actions are available for OneDrive files in File Explorer
For many of us, our digital lives are organized within the familiar folders and files of OneDrive. Whether it’s cherished family photos, important school assignments, or household documents, OneDrive keeps your files accessible, safe, and organized. And with Copilot, we have brought new ways for you to get information quickly. Now, we are bringing Copilot for OneDrive files to File Explorer and the OneDrive Activity Center—a new way to make working with your files easier, smarter, and more efficient on your Windows PC.
How can you use Copilot for your files?
Users can access Copilot features for their files from OneDrive Activity Center
We are bringing the power of AI directly into your daily file management experience. With just a few clicks, Copilot can help you summarize lengthy documents, generate an FAQ, compare files, or answer questions about your file.
To get started, make sure your files are saved in OneDrive and that you’re signed in with your Microsoft 365 Personal or Family account.
File Explorer: simply open File Explorer on your Windows device. When you select a file* stored in OneDrive, right click and hover over OneDrive in the context menu- you’ll notice a new set of Copilot options.
OneDrive Activity Center: open the OneDrive Activity Center (OneDrive icon in your taskbar or notification area) and find the file*. Click on More options to access the Copilot actions you can perform on the file.
Who can use these features?
To access these features, you’ll need a Microsoft 365 Personal or Family account, and your files must be stored in OneDrive to access OneDrive features. They are now available to subscribers, so you can try them today!
What can Copilot do with my files?
Summarize: generate a concise, easy-to-understand summary of a document’s content. Perfect for when you need a quick refresher or want to decide which file to review in detail.
Create an FAQ: puts together a list of “Frequently Asked Questions” related to your document.
Ask a question: have a specific question? Just ask Copilot and it will return the answer from your file.
Compare files (File Explorer only): creates a concise table highlighting differences between multiple files (up to 5).
Tips for Maximizing Your Copilot Experience
Keep files in OneDrive. If your files are stored locally or on another service, you can move them to OneDrive for the best experience.
Stay signed in. Use your Microsoft 365 Personal or Family account to unlock all Copilot features. If you see Copilot options missing, check your account status and subscription.
Try different file types. Copilot actions work with different file types*.
Give feedback. We’re always working to improve Copilot. Use the built-in feedback tools to let us know what works well and what you’d like to see in the future.
Want to learn about what’s new across OneDrive? Join our digital event on October 8th. To RSVP and get more information, click here.
* Supported file types include Microsoft 365 documents (DOC, DOCX, PPT, PPTX, XLSX, FLUID, LOOP), Universal formats (PDF, TXT, RTF), Web files (HTM, HTML), and OpenDocument formats (ODT, ODP). Photos and videos are not supported at this time.