What's it all about?
QMD is a quite popular mini cli search engine for your docs, knowledge bases, meeting notes, whatever.
qmd has been created by Tobi Luetke, the founder of Shopify and can be found on GitHub.
It allows you to index Markdown files from several locations on your computer.
You can search with keywords or natural language.
QMD combines BM25 full-text search, vector semantic search, and LLM re-ranking—all running locally via node-llama-cpp with GGUF models.
After installing it, you can add a new collection like this:
qmd collection add ~/notes --name notesNow all Markdown files under ~/notes will be indexed and be searched like this:
qmd search -c notes "search term"If you have multiple collections, you can do a global search:
qmd search "search term"You can query or do a vector search (see docs for more details).
qmd also provides a mcp server, so you can integrate it as a memory server into your agentic workflows:
qmd mcp --httpThis will run start the mcp server on port 8181.
Of course you can specify another port and you can also run it in daemon mode:
qmd mcp --daemon --http --port 9000So if I have a collection named blog which points to the source repository of my blog on my computer, I can run a search like this:
qmd search tmuxThis will search all collections, hence also my collection named blog and the results will look like this:
qmd://blog/articles/my-tmux-tmuxinator-rails-ai-development-setup/index.md:2 #b9e642
Title: So what's tmux?
Score: 92%
@@ -1,4 @@ (0 before, 156 after)
---
title: "My tmux + Rails + AI TUIs development setup"
date: 2026-02-11T22:00:00
layout: defaultEarlier today I was curious if I could display the whole Markdown file instead of result shown above and I came up with the idea of building a Temrinal UI (TUI) for for qmd - lazyqmd was born.
Introducing lazyqmd
As with qmd itself, lazyqmd can be installed using bun:
bun install -g lazyqmdTo use all of the lazyqmd features, make sure to start the qmd mcp server in daemon mode as shown before. If you stick with the default port, you're good to go.
If you set another port, you can configure lazyqmd to use this one in the ~/.config/lazyqmd/options.json file (for more details, take a look at the README).
Now we're ready to start lazyqmd:
lazyqmdIf you're starting from scratch without prior usage of qmd itself, you'll have no collections at hand and lazyqmd will look like this:
![]()
As can bee seen from the bottom bar in the screenshot, there's a command Add which can be invoked by pressing the a key - this brings up a little dialog to add a new collection:
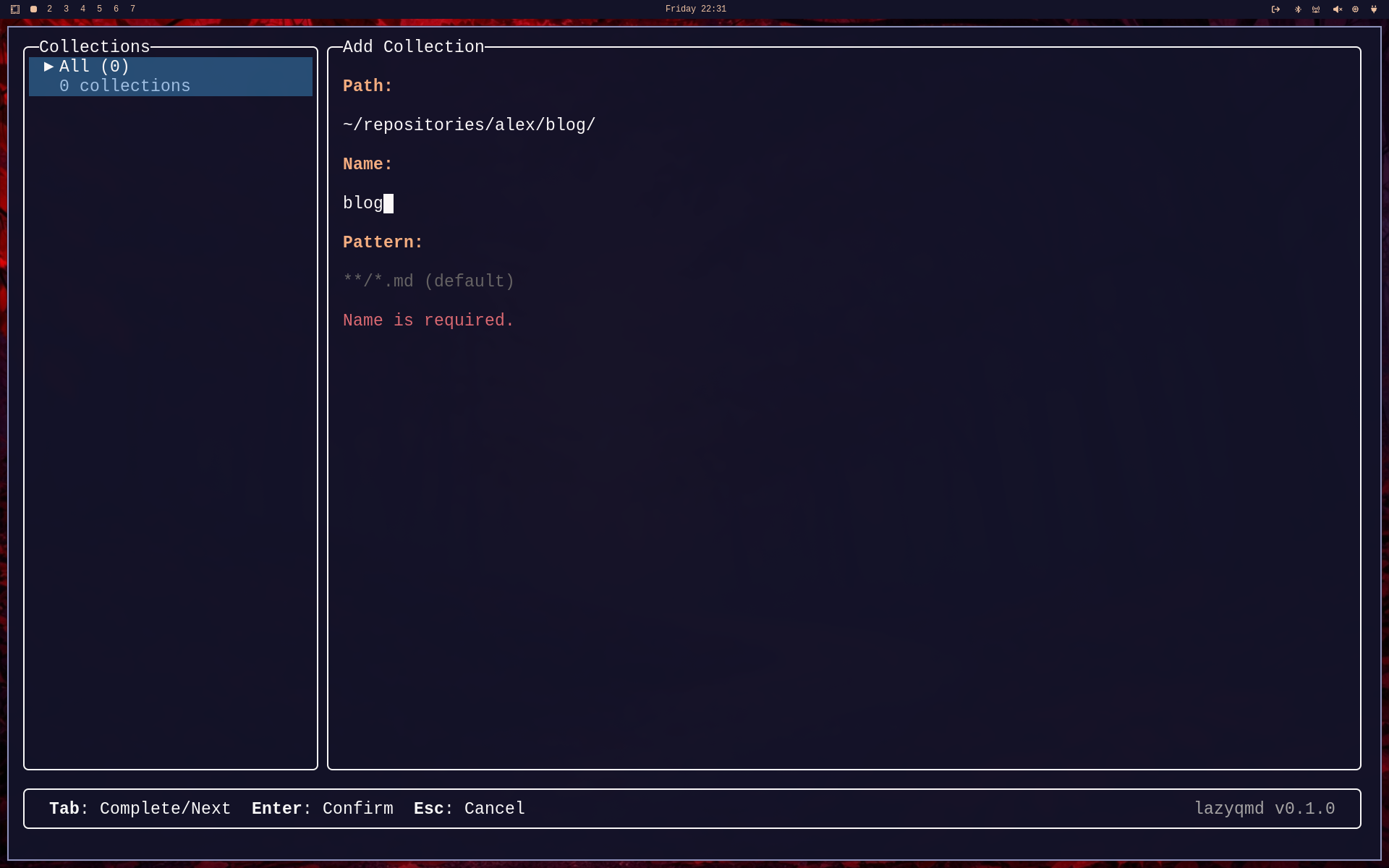
Please notice, that you get tab completion for the path.
Please wait until the Indexing... message disappears. Once, the collection has been indexed, you can start using it. lazyqmd should look similar to this now:
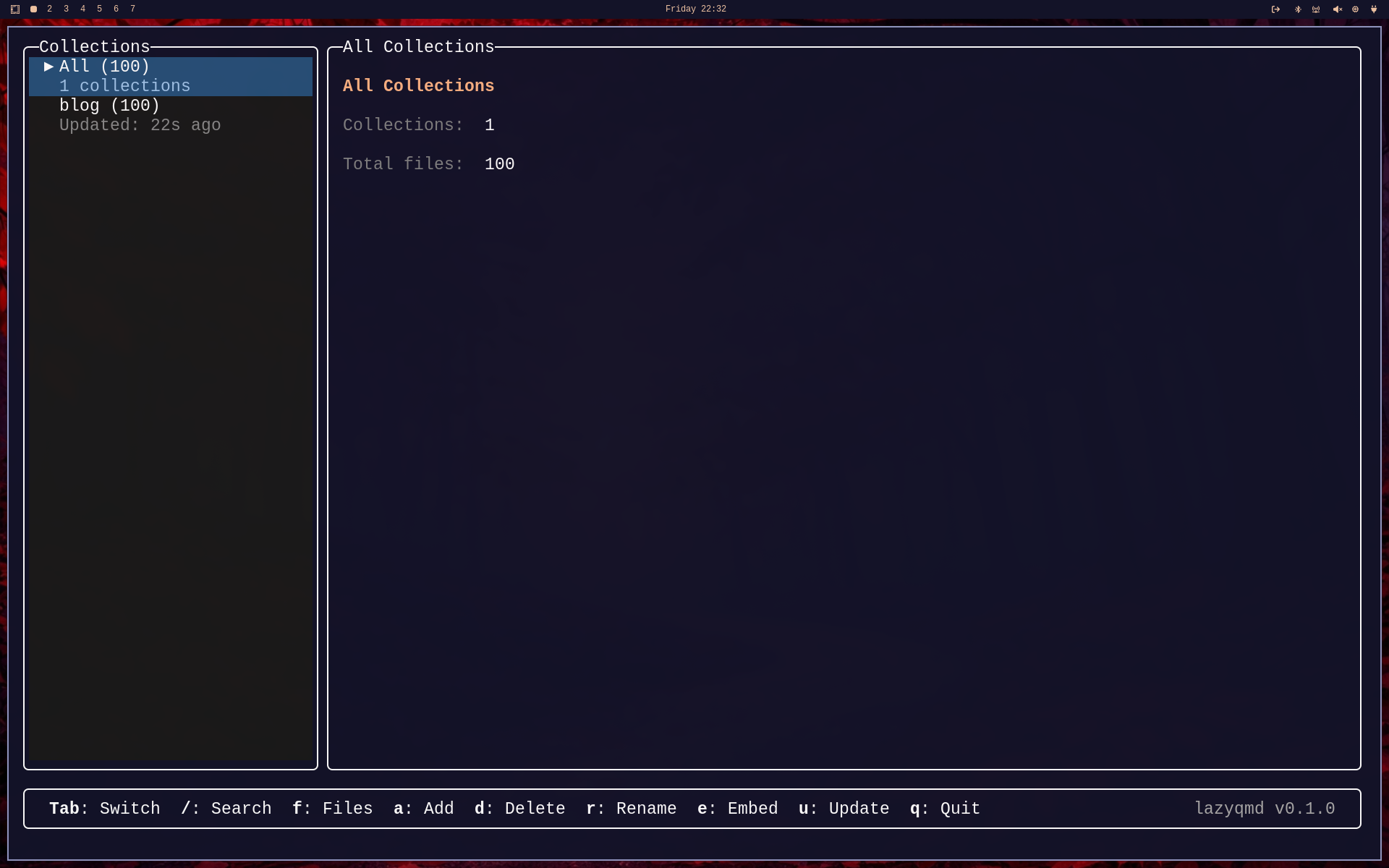
You can navigte the collections in the left sidebar using up and down arrows and you can start a new search by either sticking with the All selection for a global search or you can select a particular collection and search this one.
Let's select blog and hit / to bring up the search dialog:
![]()
Now lets type "tmux":
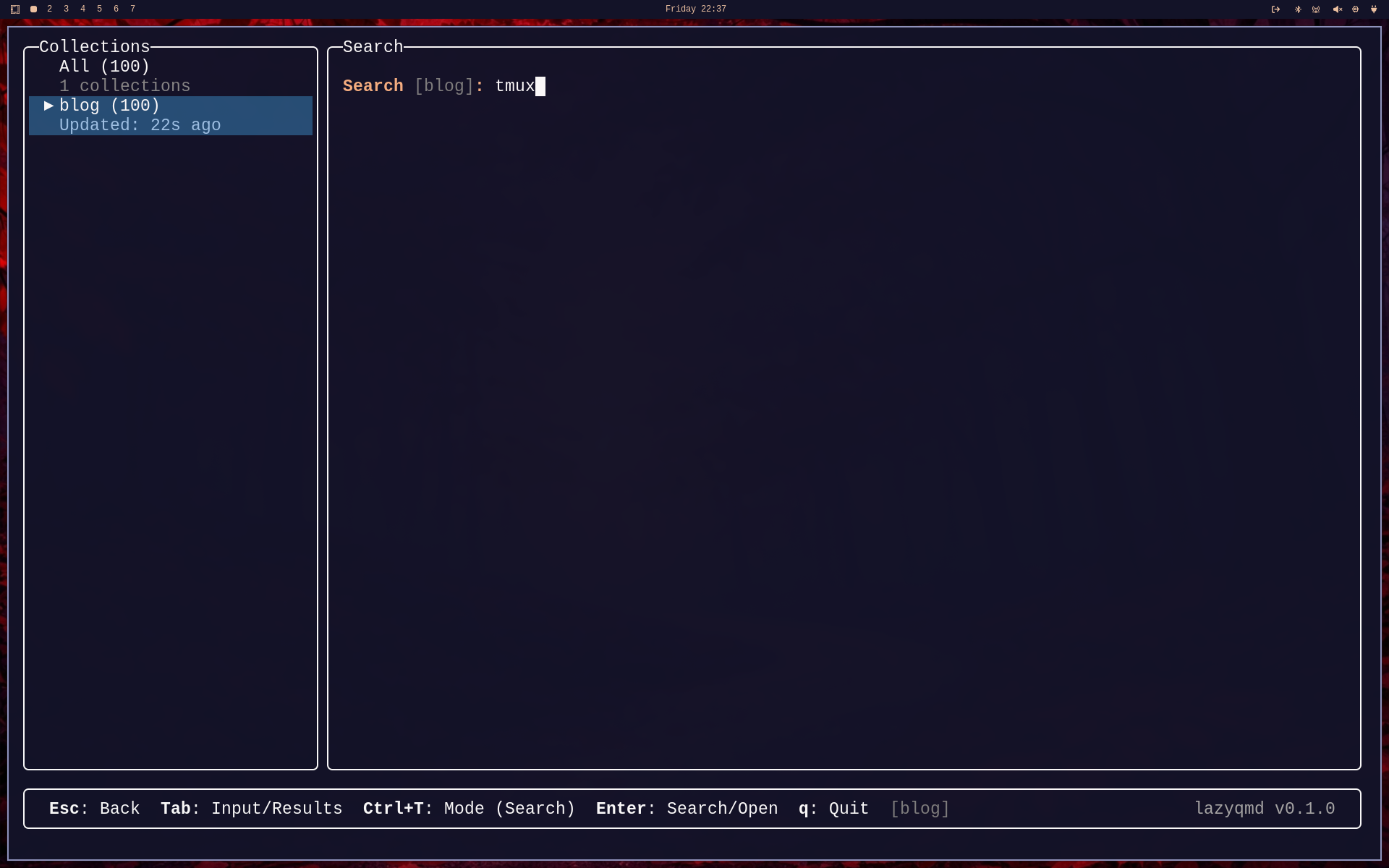
Htting "Enter" will bring up the search results for this particular search term:
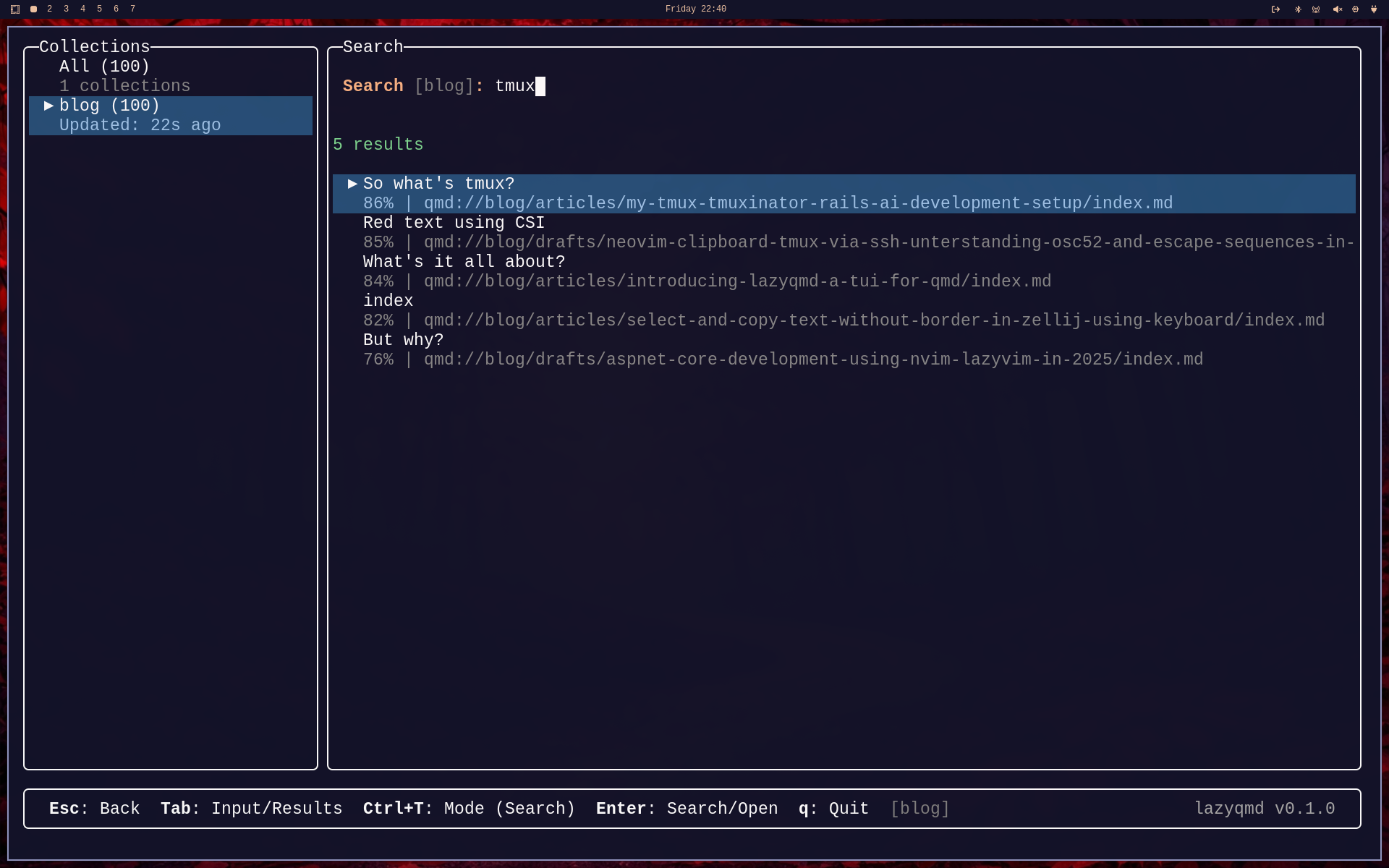
The first result seems interesting as it has a relevance of 86%. So lets hit <tab> to jump to the results list follow by Enter to open that particular document:
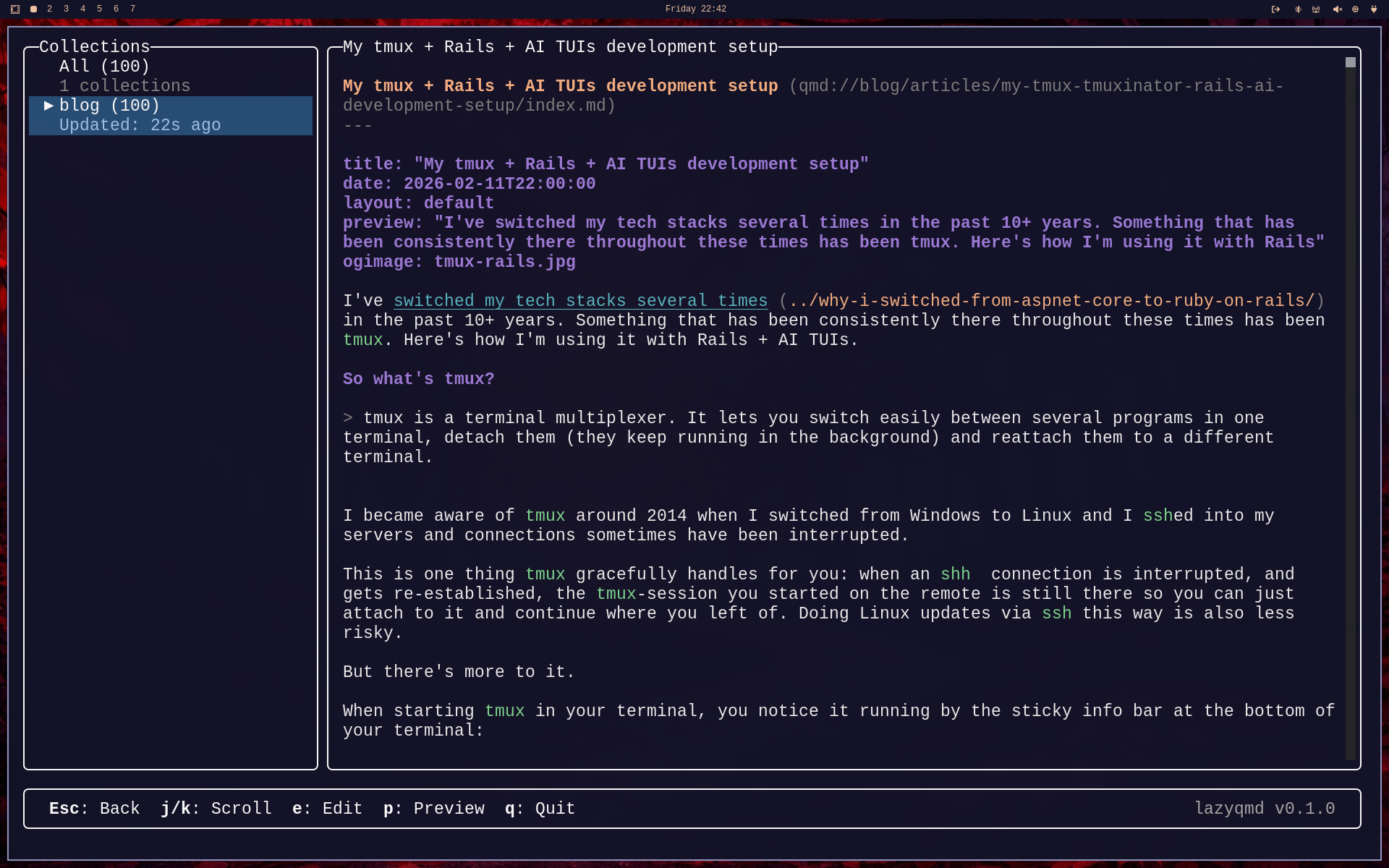
Now you can scroll inside this document and as can be seen, there's some syntax highlighting for Markdown and YAML frontmatter.
At this point I thought it would be nice to have a HTML preview at hand, so I've added it. Within the Markdown preview just hit <p>:
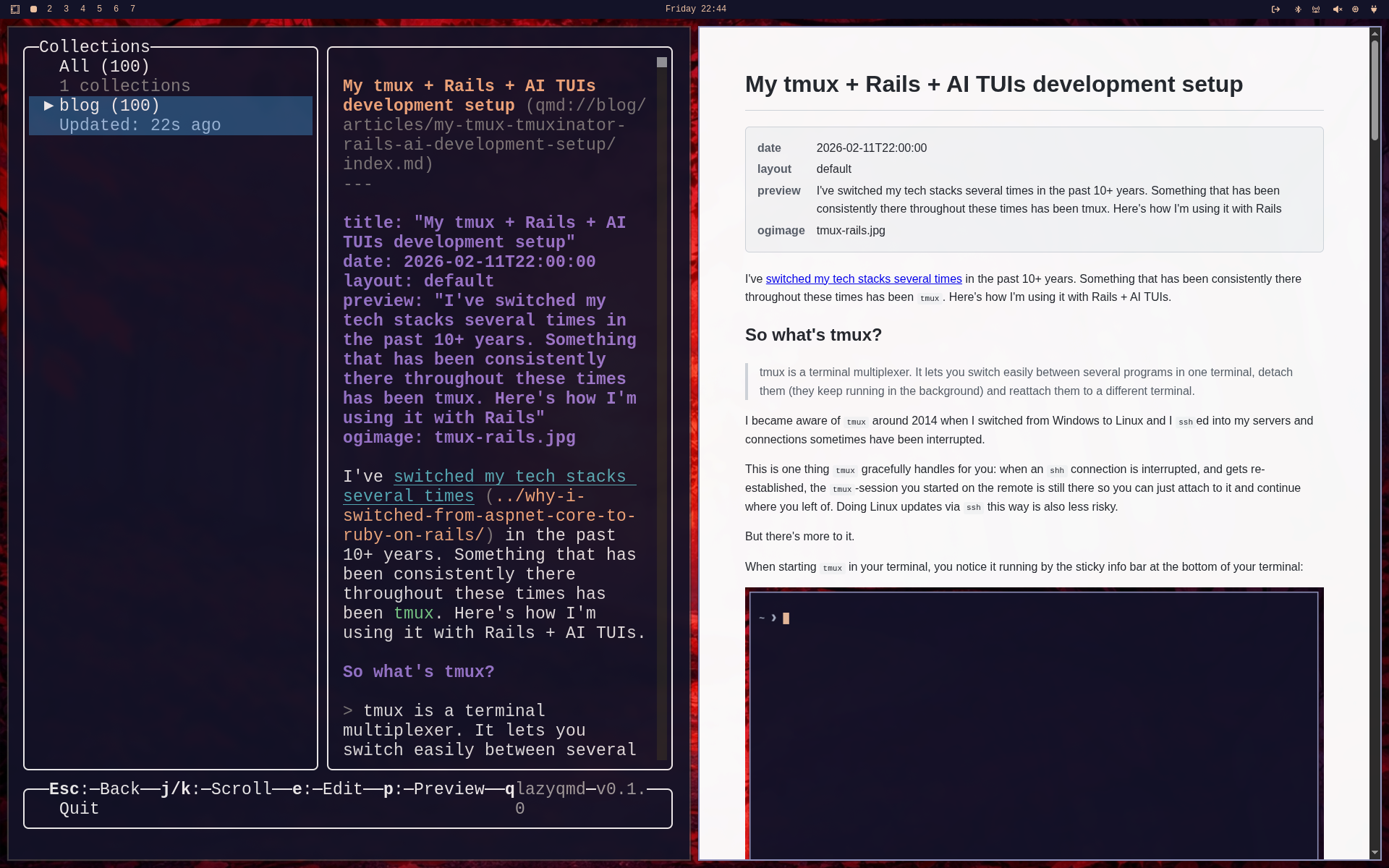
As expected, this brings up a Chrome, Chromium or Brave instance in app mode. If you're living the dream and run Omarchy, everything will be auto aligned nicely thanks to hyprland.
Now I wanted to go a little further: What if I could just edit the file and get a sort of hot reload of the HTML?
Lets focus the lazyqmd window and hit <e> for "Edit":
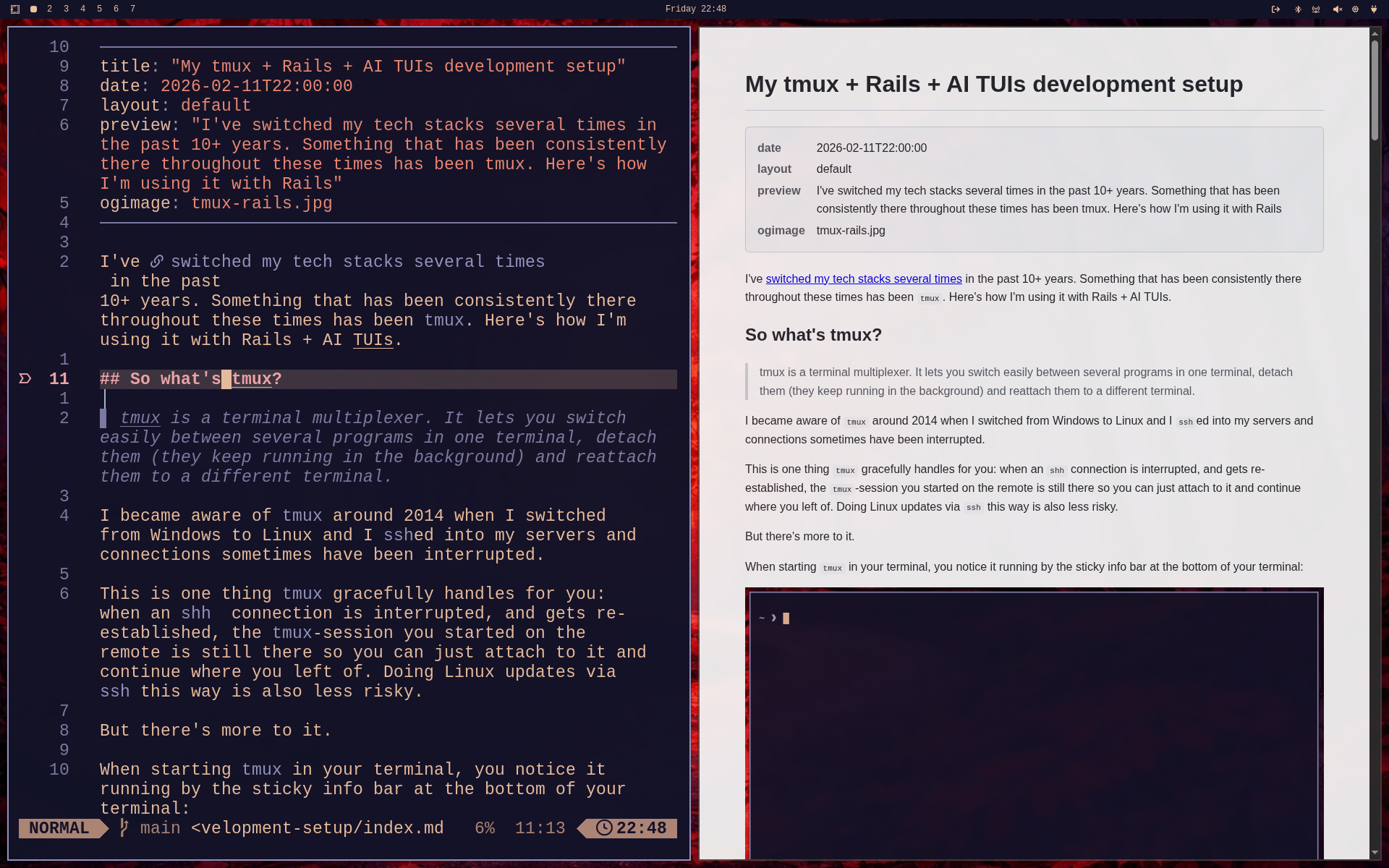
If your $EDITOR is nvim, this will seamlessly open the Markdown file in neovim.
Now lets make a little change to our Markdown file:
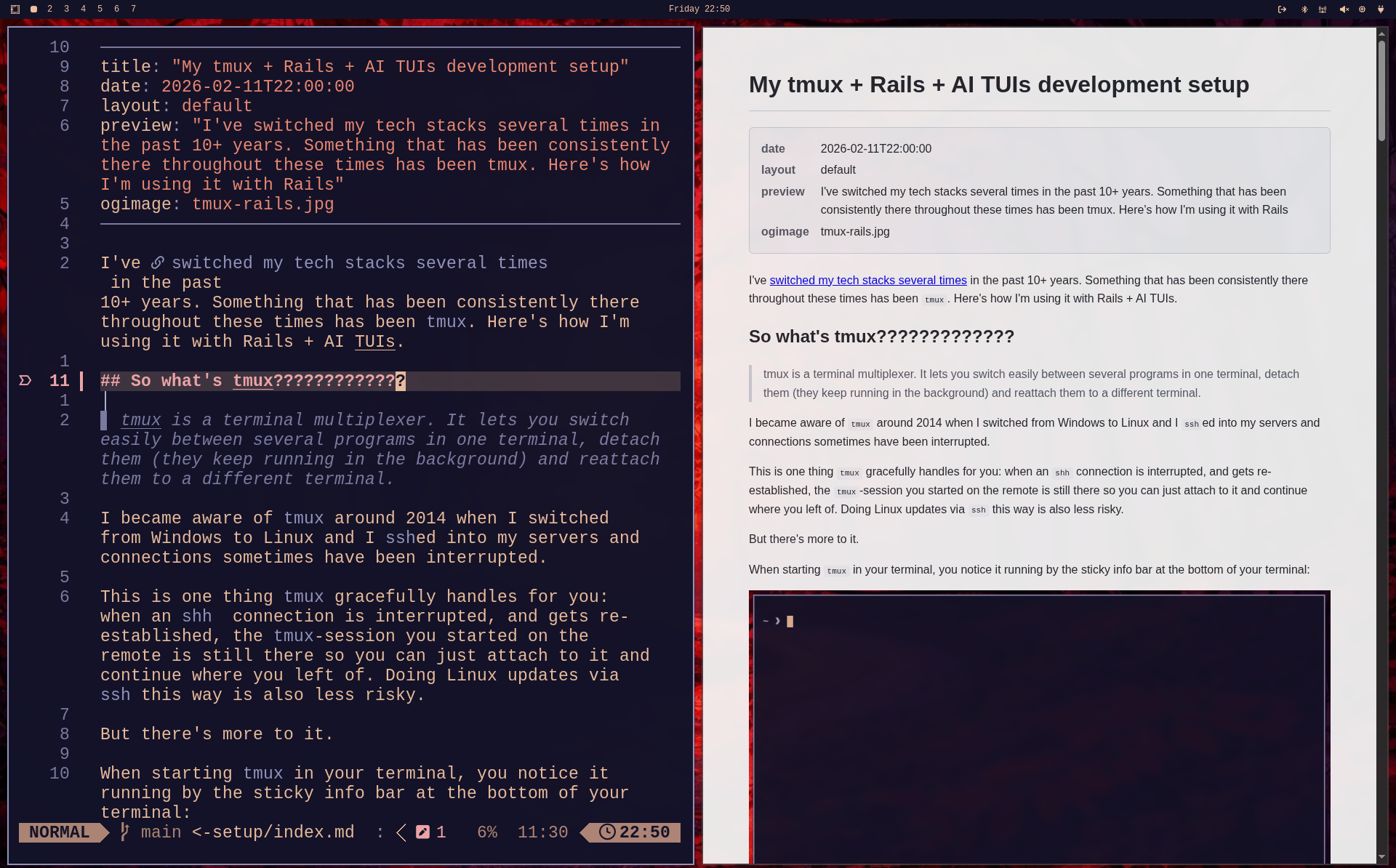
As you can see, when saving the change, the change is reflected in the HTML preview.
Quitting nvim will bring you back to lazyqmd where you left off.
Looking at the search screen again, you might have noticed, there's a "Mode" command show in the command bar at the bottom:
By hitting <CTRL+T> you can switch between regular search, vsearch (QMD Vector search) and query.
If you want to use vsearch, make sure you've created the Embeddings. If you didn't so far, you can just hit <e> on the main screen with a collection selected. This will run qmd ebmed for you and create the Embeddings.
After finishing this, I noticed that this little TUI + QMD might replace LogSeq and Obsidian for me: file based, run locally and I can have my files where they belong to- lets see how this works in daily use.
For more features, please have a look at the README on GitHub.
As this project is pretty new, expect not everything to be perfect right now.