Background
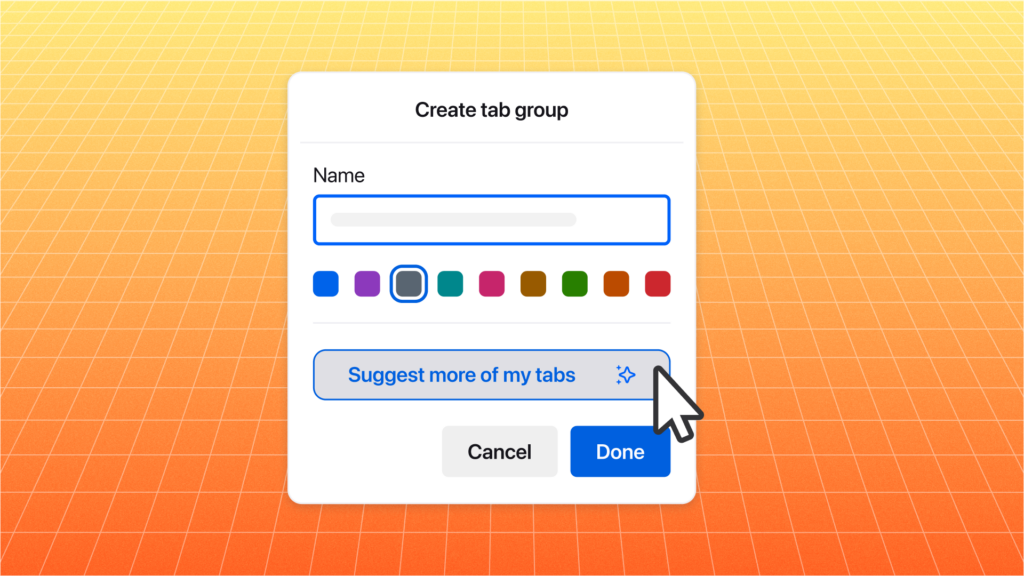
Mozilla launched Tab Grouping in early 2025, allowing tabs to be arranged and grouped with persistent labels. It was the most requested feature in the history of Mozilla Connect. While tab grouping provides a great way to manage tabs and reduce tab overload, it can be a challenge to locate which tabs to group when you have many open.
We sought to improve the workflows by providing an AI tab grouping feature that enables two key capabilities:
- Suggesting a title for a tab group when it is created by the user.
- Suggesting tabs from the current window to be added to a tab group.
Of course, we wanted this to work without you needing to send any data of yours to Mozilla, so we used our local Firefox AI runtime and built an efficient model that delivers the features entirely on your own device. The feature is opt-in and downloads two small ML models when the user clicks to run it the first time.
Group title suggestion
Understanding the problem
Suggesting titles for grouped tabs is a challenge because it is hard to understand user intent when tabs are first grouped. Based on our interviews when we started the project, we found that while tab groups are sometimes generic terms like ‘Shopping’ or ‘Travel’, over half the time users’ tabs were specific terms such as name of a video game, friend or town. We also found tab names to be extremely short – 1 or 2 words.
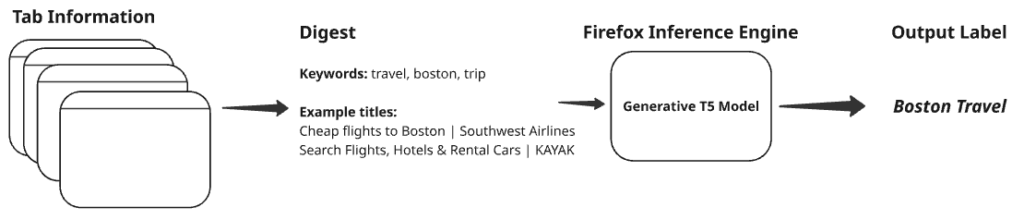
Generating a digest of the group
To address these challenges, we adopt a hybrid methodology that combines a modified TF-IDF–based textual analysis with keyword extraction. We identify terms that are statistically distinctive to the titles of pages within a tab group compared to those outside it. The three most prominent keywords, along with the full titles of three randomly selected pages, are then combined to produce a concise digest representing the group, which is used as input for the subsequent stage of processing using a language model.
Generating the label
The digest string is used as an input to a generative model that returns the final label. We used a T5 based encoder-decoder model (flan-t5-base) that was fine tuned on over 10,000 example situations and labels.
One of the key challenges in developing the model was generating the training data samples to tune the model without any user data. To do this, we defined a set of user archetypes and used an LLM API (OpenAI GPT-4) to create sample pages for a user performing various tasks. This was augmented by real page titles from the publicly available common crawl dataset. We then used the LLM to suggest short titles for those use cases. The process was first done at a small scale of several hundred group names. These were manually corrected and curated, adjusting for brevity and consistency. As the process scaled up, the initial 300 group names were used as examples passed to the LLM so that the additional examples created would meet those standards.
Shrinking things down
We need to get the model small enough to run on most computers. Once the initial model was trained, it was sampled to a smaller model using a process known as knowledge distillation. For distillation, we tuned a t5-efficient-tiny model from the token probability outputs of our teacher flan-t5-base model. Midway through the distillation process we also removed two encoder transformer layers and two decoder layers to further reduce the number of parameters.
Finally, the model parameters were quantized from floating point (4 bytes per parameter) to integer 8 bit. In the end this entire reduction process reduced the model from 1GB to 57 MB, with only a modest reduction in accuracy.
Suggesting tabs
Understanding the problem
For tab suggestions, we identified a couple of approaches on how people prefer grouping their tabs. Some people prefer grouping by domain to easily access all documents for work for instance. Others might prefer grouping all their tabs together when they are planning a trip. Others still might prefer separating their “work” and “personal” tabs.
Our initial approach on suggesting tabs was based on semantic similarity. Tabs that are topically similar are suggested.
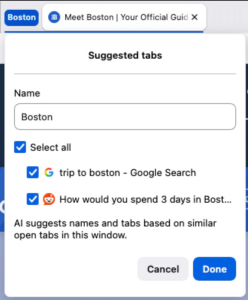
Identifying topically similar tabs
We first convert tab titles to a feature vector locally using a MiniLM embedding model. Embedding models are trained so that similar content produces vectors that are close together in embedding space. Using a similarity measure such as cosine similarity, we’re able to assign how closely similar a tab title or url is to another.
The similarity score between an anchor tab chosen by the user and another tab is a linear combination of the candidate tab with the group title (if present) of the anchor tab, the anchor tab title and the anchor url. Using these values, we generate a similarity probability and tabs that have a high probability threshold are suggested to be part of the group.
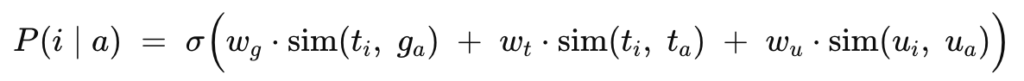
where,
w is the weight,
t_i is the candidate tab,
t_a is the anchor tab,
g_a is the anchor group title,
u_i is the candidate url
u_a is the anchor url, and,
σ is the sigmoid function
Optimizing the weights
In order to find the weights, we framed the problem as a classification task, where we calculate the precision and recall based on the tabs that were correctly classified given an anchor tab. We used synthetic data generated by OpenAI based on the user archetypes above.
We initially used a clustering approach to establish a baseline and switched to a logistic regression when we realized that treating the group, title and url features with varying importances improved our metrics.
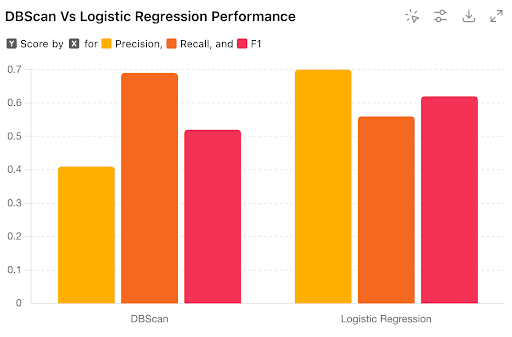
Using logistic regression, there was an 18% improvement against the baseline.
Performance
While the median number of tabs for people using the feature is relatively small (~25), there are some “power” users whose tab count reaches the thousands. This would cause the tab grouping feature to take uncomfortably long.
This was part of the reason why we switched from a clustering based approach to a linear model.
Using our performance framework, we found that the p99 of running logistic regression compared to a clustering based method such as KMeans improved by 33%.
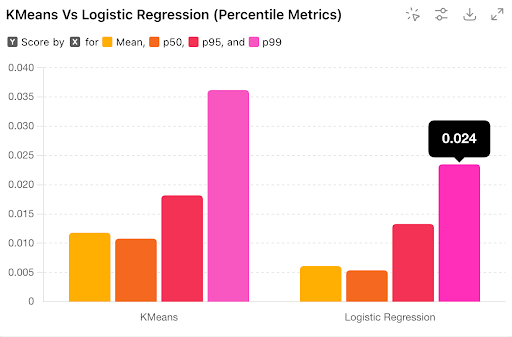
Future work here would involve improving F1 score. These could be by adding a time-related component as part of the inference (we are more likely to group tabs together that we’ve opened at the same time) or using a fine-tuned embedding model for our use case.
Thanks for reading
All of our work is open source. If you are a developer feel free to peruse our source code on our model training, or view our topic model on Huggingface.
Feel free to try the feature and let us know what you think!

Take control of your internet
Download FirefoxThe post Under the hood: How Firefox suggests tab groups with local AI appeared first on The Mozilla Blog.