Deep dive into the Blazor renderer, component lifecycle, and advanced rendering optimizations using ShouldRender, RenderFragments, and lifecycle methods.

|
Sr. Content Developer at Microsoft, working remotely in PA, TechBash conference organizer, former Microsoft MVP, Husband, Dad and Geek.
|

Pennsylvania, USA


Sam Ransbotham teaches a class in machine learning as a professor of business analytics at Boston College, and what he’s witnessing in the classroom both excites and terrifies him.
Some students are using AI tools to create and accomplish amazing things, learning and getting more out of the technology than he could have imagined. But in other situations, he sees a concerning trend: students “phoning things into the machine.”
The result is a new kind of digital divide — but it’s not the one you’d expect.
Boston College provides premier tools to students at no cost, to ensure that socioeconomics aren’t the differentiator in the classroom. But Ransbotham, who hosts the “Me, Myself and AI” podcast from MIT Sloan Management Review, worries about “a divide in technology interest.”
“The deeper that someone is able to understand tools and technology, the more that they’re able to get out of those tools,” he explained. “A cursory usage of a tool will get a cursory result, and a deeper use will get a deeper result.”
The problem? “It’s a race to mediocre. If mediocre is what you’re shooting for, then it’s really quick to get to mediocre.”
He explained, “Boston College’s motto is ‘Ever to Excel.’ It’s not ‘Ever to Mediocre.’ And the ability of students to get to excellence can be hampered by their ease of getting to mediocre.”
That’s one of the topics on this special episode of the GeekWire Podcast, a collaboration with Me, Myself and AI. Sam and I compare notes from our podcasts and share our own observations on emerging trends and long-term implications of AI. This is a two-part series across our podcasts — you can find the rest of our conversation on the Me, Myself and AI feed.
Continue reading for takeaways from this episode.
AI has a measurement problem: Sam, who researched Wikipedia extensively more than a decade ago, sees parallels to the present day. Before Wikipedia, Encyclopedia Britannica was a company with employees that produced books, paid a printer, and created measurable economic value. Then Wikipedia came along, and Encyclopedia Britannica didn’t last.
Its economic value was lost. But as he puts it: “Would any rational person say that the world is a worse place because we now have Wikipedia versus Encyclopedia Britannica?”
In other words, traditional economic metrics don’t fully capture the net gain in value that Wikipedia created for society. He sees the same measurement problem with AI.
“The data gives better insights about what you’re doing, about the documents you have, and you can make a slightly better decision,” he said. “How do you measure that?”
Content summarization vs. generation: Sam’s “gotta have it” AI feature isn’t about creating content — it’s about distilling information to fit more into his 24 hours.
“We talk a lot about generation and the generational capabilities, what these things can create,” he said. “I find myself using it far more for what it can summarize, what it can distill.”
Finding value in AI, even when it’s wrong: Despite his concerns about students using AI to achieve mediocrity, Sam remains optimistic about what people can accomplish with AI tools.
“Often I find that the tool is completely wrong and ridiculous and it says just absolute garbage,” he said. “But that garbage sparks me to think about something — the way that it’s wrong pushes me to think: why is that wrong? … and how can I push on that?”
Searching for the signal in the noise: Sam described the goal of the Me, Myself and AI podcast as cutting through the polarizing narratives about artificial intelligence.
“There’s a lot of hype about artificial intelligence,” he said. “There’s a lot of naysaying about artificial intelligence. And somewhere between those, there is some signal, and some truth.”
Listen to the full episode above, subscribe to GeekWire in Apple, Spotify, or wherever you listen, and find the rest of our conversation on the Me, Myself and AI podcast feed.
Pennsylvania, USA
IntelliJ IDEA’s source code has been publicly available for more than 15 years, helping millions of developers learn, experiment, and contribute to their IDE and build their own tools. Now, we’re taking our commitment to open-source to the next level by making it even easier for the community to explore, build, and contribute!
What’s New?
CI/CD Pipelines via GitHub Actions
To simplify the building process, we’ve set up CI/CD pipelines using GitHub Actions. This allows anyone to build their own version of IntelliJ IDEA directly from its source code without having to manually configure a build environment.
The corresponding GitHub action and workflows are part of the repository, ready for use right after you fork the repo. Please refer to the GitHub documentation to learn more about how to manage workflows.
Open-Source Builds
If you don’t want to apply changes and only need a pure open-source build, we also publish open-source builds of IntelliJ IDEA directly to GitHub. This means you can now access ready-to-use open-source builds without needing to set up a build environment from scratch.
Build Your Own IDE
Building an open-source version of IntelliJ IDEA has never been easier!
- Fork and clone the Repository
Start by visiting the open-source IntelliJ IDEA GitHub repository to access the source code. - Make the changes and push them
- Use CI/CD Pipelines
With GitHub Actions, you can skip the manual setup process and use preconfigured pipelines to build IntelliJ IDEA directly from the codebase. This eliminates the need for configuring complex dependencies and ensures that you always work with a consistent environment. - Test and Run
Once the build is complete, run IntelliJ IDEA on your system to see your changes in action. - Contribute and Collaborate
If you’re making changes to the codebase, you can submit pull requests, fix issues, or collaborate with other contributors. This is a great way to grow as a developer while giving back to the community.
Building locally still works as it used to. This guide provides detailed steps, whether you’re contributing to IntelliJ Platform (JetBrains’ OSS platform for building IDEs), exploring new capabilities, or simply learning how IntelliJ IDEA works under the hood.
IntelliJ IDEA’s open-source codebase serves as the foundation not only for IntelliJ IDEA itself but also for other popular development tools such as Android Studio, HCL Volt MX Iris, and Adobe AEM Developer Tools. Additionally, it powers many internal solutions used daily by developers in a wide range of industries. We are fully committed to ensuring that IntelliJ IDEA’s open-source codebase remains reliable, efficient, and ready for what’s next.
If you’d like more details or want to contribute, visit the IntelliJ Platform page and be a part of the vibrant IntelliJ IDEA development community!
Pennsylvania, USA
AI Assisted Coding: Swimming in AI - Managing Tech Debt in the Age of AI-Assisted Coding
In this special episode, Lou Franco, veteran software engineer and author of "Swimming in Tech Debt," shares his practical approach to AI-assisted coding that produces the same amount of tech debt as traditional development—by reading every line of code. He explains the critical difference between vibecoding and AI-assisted coding, why commit-by-commit thinking matters, and how to reinvest productivity gains into code quality.
Vibecoding vs. AI-Assisted Coding: Reading Code Matters
"I read all the code that it outputs, so I need smaller steps of changes."
Lou draws a clear distinction between vibecoding and his approach to AI-assisted coding. Vibecoding, in his definition, means not reading the code at all—just prompting, checking outputs, and prompting again. His method is fundamentally different: he reads every line of generated code before committing it. This isn't just about catching bugs; it's about maintaining architectural control and accountability. As Lou emphasizes, "A computer can't be held accountable, so a computer can never make decisions. A human always has to make decisions." This philosophy shapes his entire workflow—AI generates code quickly, but humans make the final call on what enters the repository. The distinction matters because it determines whether you're managing tech debt proactively or discovering it later when changes become difficult.
The Moment of Shift: Staying in the Zone
"It kept me in the zone. It saved so much time! Never having to look up what a function's arguments were... it just saved so much time."
Lou's AI coding journey began in late 2022 with GitHub Copilot's free trial. He bought a subscription immediately after the trial ended because of one transformative benefit: staying in the flow state. The autocomplete functionality eliminated constant context switching to documentation, Stack Overflow searches, and function signature lookups. This wasn't about replacing thinking—it was about removing friction from implementation. Lou could maintain focus on the problem he was solving rather than getting derailed by syntax details. This experience shaped his understanding that AI's value lies in removing obstacles to productivity, not in replacing the developer's judgment about architecture and design.
Thinking in Commits: The Right Size for AI Work
"I think of prompts commit-by-commit. That's the size of the work I'm trying to do in a prompt."
Lou's workflow centers on a simple principle: size your prompts to match what should be a single commit. This constraint provides multiple benefits. First, it keeps changes small enough to review thoroughly—if a commit is too big to review properly, the prompt was too ambitious. Second, it creates a clear commit history that tells a story about how the code evolved. Third, it enables easy rollback if something goes wrong. This commit-sized thinking mirrors good development practices that existed long before AI—small, focused changes that each accomplish one clear purpose. Lou uses inline prompting in Cursor (Command-K) for these localized changes because it keeps context tight: "Right here, don't go look at the rest of my files... Everything you need is right here. The context is right here... And it's fast."
The Tech Debt Question: Same Code, Same Debt
"Based on the way I've defined how I did it, it's exactly the same amount of tech debt that I would have done on my own... I'm faster and can make more code, but I invest some of that savings back into cleaning things up."
As the author of "Swimming in Tech Debt," Lou brings unique perspective to whether AI coding creates more technical debt. His answer: not if you're reading and reviewing everything. When you maintain the same quality standards—code review, architectural oversight, refactoring—you generate the same amount of debt as manual coding. The difference is speed. Lou gets productivity gains from AI, and he consciously reinvests a portion of those gains back into code quality through refactoring. This creates a virtuous cycle: faster development enables more time for cleanup, which maintains a codebase that's easier for both humans and AI to work with. The key insight is that tech debt isn't caused by AI—it's caused by skipping quality practices regardless of how code is generated.
When Vibecoding Creates Debt: AI Resistance as a Symptom
"When you start asking the AI to do things, and it can't do them, or it undoes other things while it's doing them... you're experiencing the tech debt a different way. You're trying to make changes that are on your roadmap, and you're getting resistance from making those changes."
Lou identifies a fascinating pattern: tech debt from vibecoding (without code review) manifests as "AI resistance"—difficulty getting AI to make the changes you want. Instead of compile errors or brittle tests signaling problems, you experience AI struggling to understand your codebase, undoing changes while making new ones, or producing code with repetition and tight coupling. These are classic tech debt symptoms, just detected differently. The debt accumulates through architecture violations, lack of separation of concerns, and code that's hard to modify. Lou's point is profound: whether you notice debt through test failures or through AI confusion, the underlying problem is the same—code that's difficult to change. The solution remains consistent: maintain quality practices including code review, even when AI makes generation fast.
Can AI Fix Tech Debt? Yes, With Guidance
"You should have some acceptance criteria on the code... guide the LLM as to the level of code quality you want."
Lou is optimistic but realistic about AI's ability to address existing tech debt. AI can definitely help with refactoring and adding tests—but only with human guidance on quality standards. You must specify what "good code" looks like: acceptance criteria, architectural patterns, quality thresholds. Sometimes copy/paste is faster than having AI regenerate code. Very convoluted codebases challenge both humans and AI, so some remediation should happen before bringing AI into the picture. The key is recognizing that AI amplifies your approach—if you have strong quality standards and communicate them clearly, AI accelerates improvement. If you lack quality standards, AI will generate code just as problematic as what already exists.
Reinvesting Productivity Gains in Quality
"I'm getting so much productivity out of it, that investing a little bit of that productivity back into refactoring is extremely good for another kind of productivity."
Lou describes a critical strategy: don't consume all productivity gains as increased feature velocity. Reinvest some acceleration back into code quality through refactoring. This mirrors the refactor step in test-driven development—after getting code working, clean it up before moving on. AI makes this more attractive because the productivity gains are substantial. If AI makes you 30% faster at implementation, using 10% of that gain on refactoring still leaves you 20% ahead while maintaining quality. Lou explicitly budgets this reinvestment, treating quality maintenance as a first-class activity rather than something that happens "when there's time." This discipline prevents the debt accumulation that makes future work progressively harder.
The 100x Code Concern: Accountability Remains Human
"Directionally, I think you're probably right... this thing is moving fast, we don't know. But I'm gonna always want to read it and approve it."
When discussing concerns about AI generating 100x more code (and potentially 100x more tech debt), Lou acknowledges the risk while maintaining his position: he'll always read and approve code before it enters the repository. This isn't about slowing down unnecessarily—it's about maintaining accountability. Humans must make the decisions because only humans can be held accountable for those decisions. Lou sees potential for AI to improve by training on repository evolution rather than just end-state code, learning from commit history how codebases develop. But regardless of AI improvements, the human review step remains essential. The goal isn't to eliminate human involvement; it's to shift human focus from typing to thinking, reviewing, and making architectural decisions.
Practical Workflow: Inline Prompting and Small Changes
"Right here, don't go look at the rest of my files... Everything you need is right here. The context is right here... And it's fast."
Lou's preferred tool is Cursor with inline prompting (Command-K), which allows him to work on specific code sections with tight context. This approach is fast because it limits what AI considers, reducing both latency and irrelevant changes. The workflow resembles pair programming: Lou knows what he wants, points AI at the specific location, AI generates the implementation, and Lou reviews before accepting. He also uses Claude Code for full codebase awareness when needed, but the inline approach dominates his daily work. The key principle is matching tool choice to context needs—use inline prompting for localized changes, full codebase tools when you need broader understanding. This thoughtful tool selection keeps development efficient while maintaining control.
Resources and Community
Lou recommends Steve Yegge's upcoming book on vibecoding. His website, LouFranco.com, provides additional resources.
About Lou Franco
Lou Franco is a veteran software engineer and author of Swimming in Tech Debt. With decades of experience at startups, as well as Trello, and Atlassian, he's seen both sides of debt—as coder and leader. Today, he advises teams on engineering practices, helping them turn messy codebases into momentum.
You can link with Lou Franco on LinkedIn and visit his website at LouFranco.com.
Download audio: https://traffic.libsyn.com/secure/scrummastertoolbox/20251125_Lou_Franco_Tue.mp3?dest-id=246429
Pennsylvania, USA
Listening to the voices of young people is crucial in creating genuinely effective learning resources. That’s why we recently ran a survey of students who use Ada Computer Science, our platform designed to help students learn and revise key computer science concepts.
“The different topics are nicely categorised and it is easy to find the information I wish to revise.” – Ada Computer Science student
We were delighted to hear from 103 students, most of whom are 16–19 years old and studying in England, and their insights are invaluable in helping us to continue to develop Ada CS.
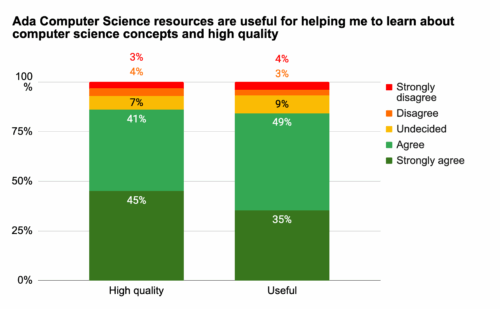
Students think Ada CS is high quality and useful
The most common ways students use Ada CS are for revision and to check whether they understand concepts. The majority of respondents are building Ada CS into their regular study habits, with over half of respondents using the platform every week.

We were pleased to see the benefits of updates we’ve made, including a redesign of the question finder released in March 2025 — students reported that it is easy to navigate the platform and find what they need: 81% reported being able to find relevant content, and 77% could find the questions they were looking for.
“It’s SO EASY to find exactly what I want.” – Ada Computer Science student
Overall, students perceive Ada CS as both useful for learning about computer science concepts and of high quality. They reported finding the content clear, with a good level of detail.
“The topics are broken down into easily digestible sections, and the provided diagrams really help with understanding the topics.” – Ada Computer Science student
“The resource is really well designed, short and concise.” – Ada Computer Science student
We also received helpful suggestions for future improvements. Students shared feedback on how the information on the platform is presented, asking for more concise, revision-friendly content as well as guidance for exploring concepts in more depth. We’ll therefore be looking into alternative ways to structure content as we continue to develop Ada CS.
Students rate the quizzes highly
The most popular feature is the quizzes and practice questions, including the immediate feedback and hints provided. Students value how these resources help them solidify their knowledge, learn from mistakes, and prepare for assessments.
“The questions are clear and make me think, they’re relevant to my studies and the hints for the questions are very useful.” – Ada Computer Science student
We also appreciated the suggestions we received for how we can further develop this feature, for example, creating more questions, extending the range of question types per topic, and making improvements to the hints.
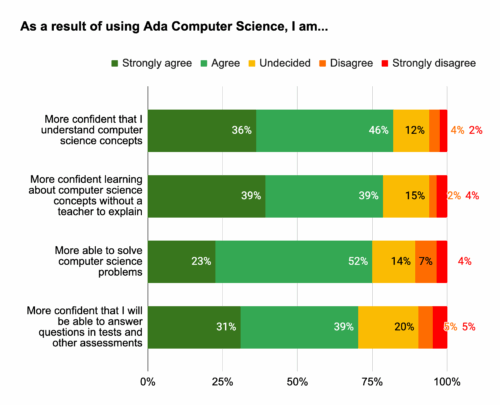
Impact on learning
Students also feel that using Ada CS has a tangible impact on their learning. 82% agreed they were more confident that they understand CS concepts as a result of using Ada CS and 79% feel more confident learning about computer science concepts without a teacher to explain.
“I do CS A level but I hadn’t done the GCSE and I found that all of the resources gave me enough information to learn the concepts from scratch and now I’m much more confident in my knowledge of the theory.” – Ada Computer Science student
What’s coming next?
Students provided us with lots of useful feedback and suggestions for how we can further improve Ada CS, especially relating to practice questions. We’re already working on adding more questions across topics, creating more challenging questions, and adding more question types that will enhance students’ learning experience. We’ve got some other exciting developments in the pipeline too, which we’ll announce soon!
Thank you to everyone who took the time to complete the survey. These findings are invaluable for shaping the future of Ada Computer Science, helping us to continue to provide the best possible learning platform for students.
The post How Ada Computer Science empowers students: Survey findings appeared first on Raspberry Pi Foundation.
Pennsylvania, USA

AWS introduces flat-rate pricing plans for website delivery and security, offering predictable monthly costs with no overages. Combining CloudFront CDN, DDoS protection, and more, tiers start from free to $1,000/month. This shift enables seamless scaling for applications and simplifies budgeting, empowering developers to innovate without fear of unexpected charges.
By Steef-Jan Wiggers
Pennsylvania, USA
Next Page of Stories