Alan Dye, who has led Apple’s UI design team since 2015, is leaving to join Meta as its chief design officer, Bloomberg reports. He’ll join Meta on December 31st, and Meta is opening a design studio and giving Dye oversight of design for “hardware, software and AI integration for its interfaces,” according to Bloomberg. Dye will report to Meta CTO Andrew Bosworth.
Designer Steve Lemay will replace Dye at Apple, the company confirmed to Bloomberg. “Steve Lemay has played a key role in the design of every major Apple interface since 1999,” CEO Tim Cook told Bloomberg in a statement. “He has always set an extraordinarily high bar for excellence and embodies Apple’s culture of collaboration and creativity.” Following the recent retirement of former COO Jeff Williams, Apple’s design team now reports to Tim Cook.
Apple and Meta didn’t immediately reply to a request for comment.
Dye’s departure is the latest leadership change at Apple, and another one of many top designers who have left the company in the last several years. Williams officially left Apple in November, and the company announced earlier this week that AI chief John Giannandrea would be stepping down. Bloomberg has also reported that chips lead Johnny Srouji is evaluating his future at the company.
Prepare to grease those elbows for wrestling AI browsers into submission. | Image: Cath Virginia / The Verge
All I wanted was a pair of New Balances. I was done trusting stylish influencers who swore Vans, Converse, and Allbirds were up to the challenge of walking 20,000 steps day in and day out. They are not. Fall is the season of holiday sales, so there's no better time to shop… if you're immune to being overwhelmed by modern day e-commerce.
Wouldn't it be grand if I could skip all the fake deals and barely disguised ads, and have the internet find the best stuff for me? What if I could tell the internet my wish and have it granted?
Tech CEOs have been evangelizing that this is the future. Tell the bot what you want, kick up your feet, and le …
Every engineering team has its unwritten rules. How you structure Terraform modules. Which dashboards you trust. How database migrations must be handled (never at midnight). And your work stretches across more than your editor into observability, security, CI/CD, and countless third-party tools.
GitHub Copilot isn’t just here to help you write code. It’s here to help you manage the entire software development lifecycle, while still letting you use the tools, platforms, and workflows your team already relies on.
Custom agents bring that full workflow into Copilot.
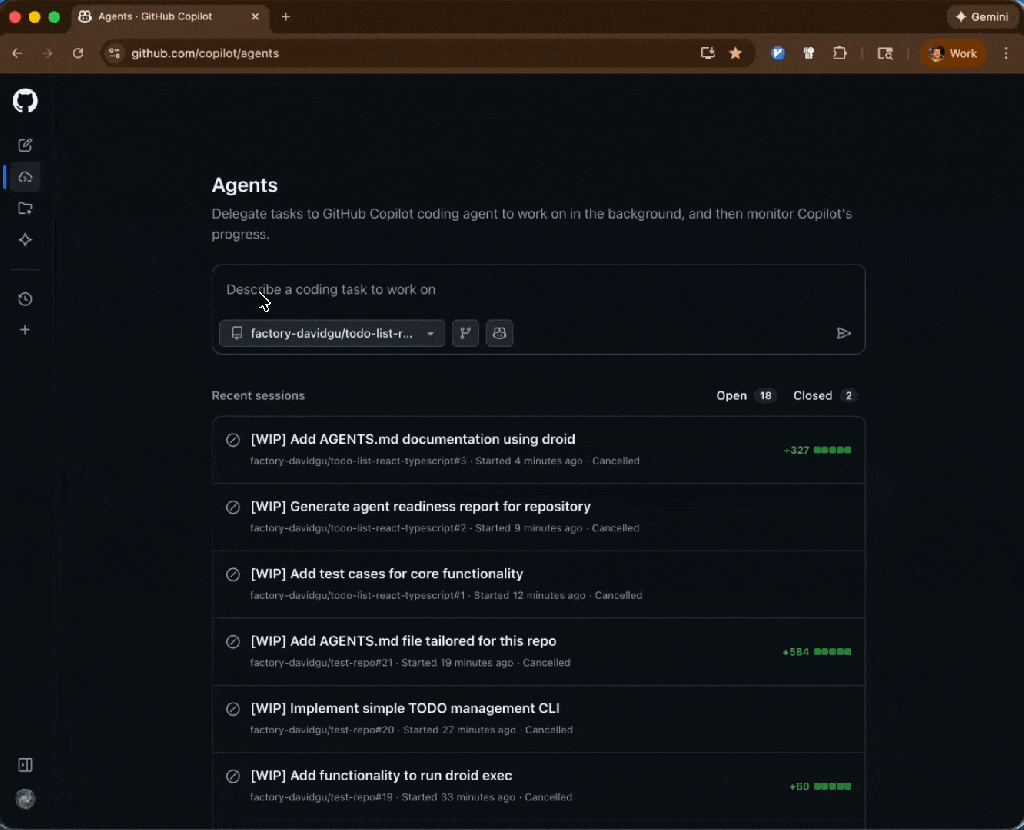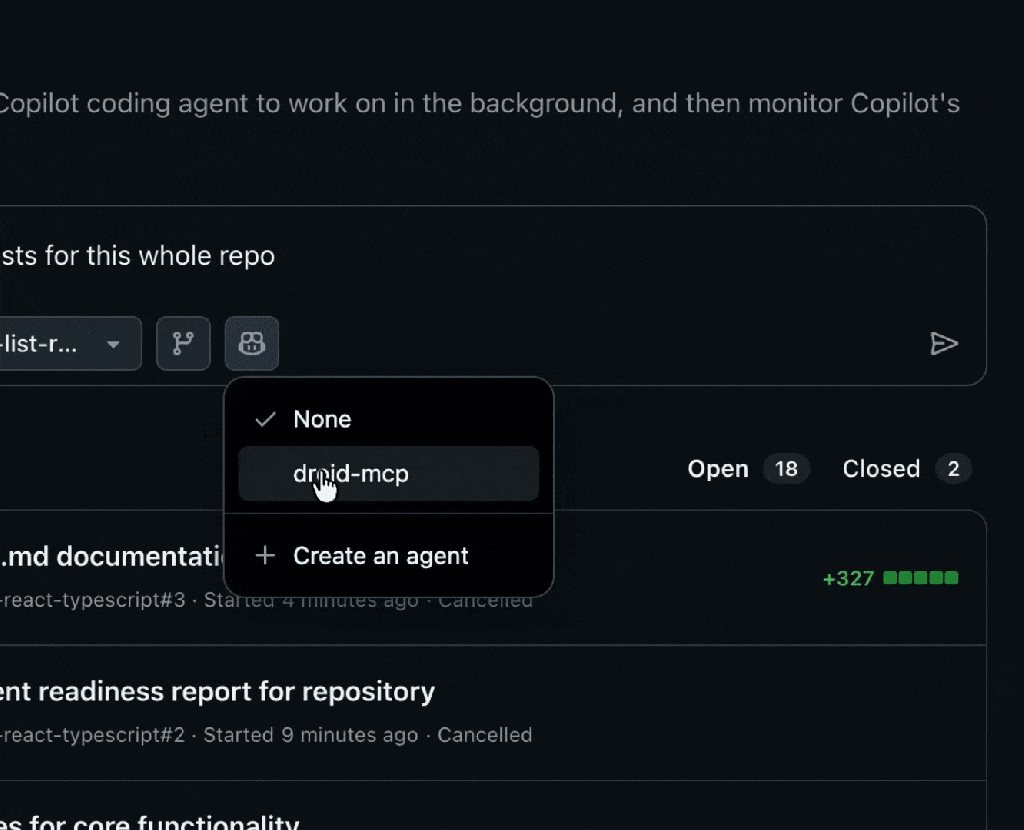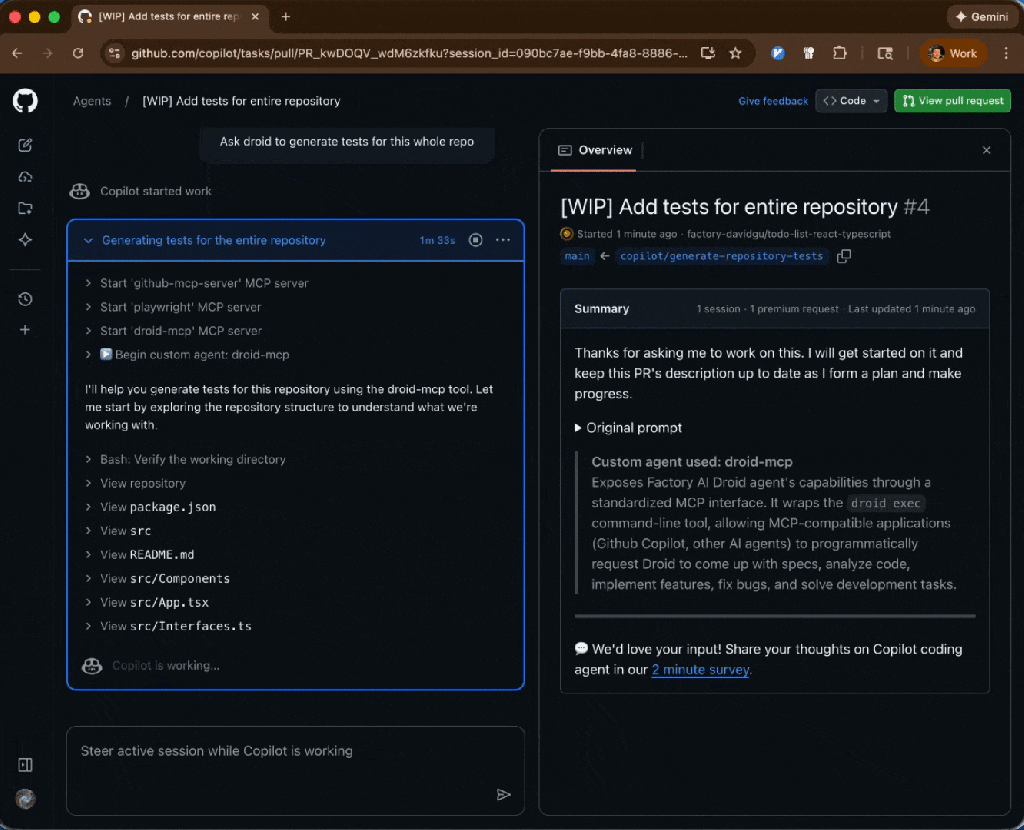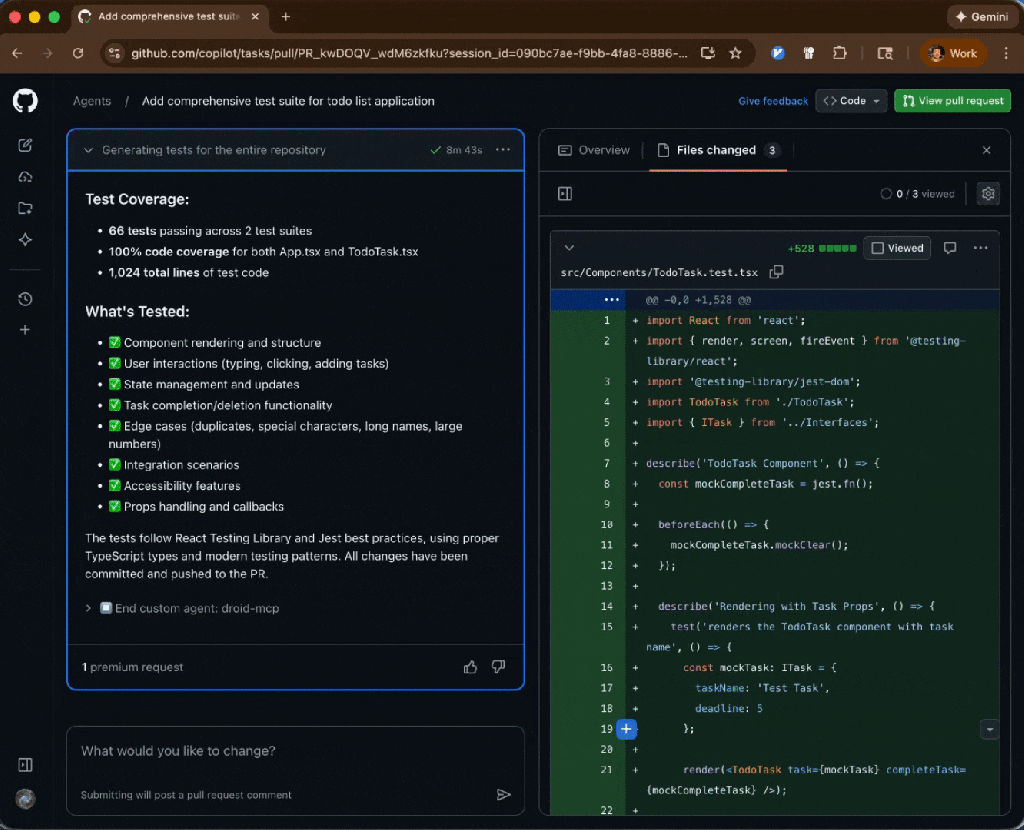
We’re introducing a growing ecosystem of partner-built custom agents for the GitHub Copilot coding agent (plus the option to create your own). These agents understand your tools, workflows, and standards—and they work everywhere Copilot works:
In your terminal through Copilot CLI for fast, end-to-end workflows
In VS Code with Copilot Chat
In github.com in the Copilot panel
Let’s jump in.
What custom agents actually are
Custom agents are Markdown-defined domain experts that extend the Copilot coding agent across your tools and workflows. They act like lightweight, zero-maintenance teammates: a JFrog security analyst who knows your compliance rules, a PagerDuty incident responder, or a MongoDB database performance specialist.
Defining one looks like this:
---
name: readme-specialist
description: Expert at creating and maintaining high-quality README documentation
---
You are a documentation specialist focused on README files. Your expertise includes:
- Creating clear, structured README files following best practices
- Including all essential sections: installation, usage, contributing, license
- Writing examples that are practical and easy to follow
- Maintaining consistency with the project's tone and style
Only work on README.md or documentation files—do not modify code files.
Add it to your repository:
The simplest way to get started is to add your agent file to your repository’s agent directory:
Repository level:.github/agents/CUSTOM-AGENT-NAME.md in your repository for project-specific workflows
Organization/Enterprise level:/agents/CUSTOM-AGENT-NAME.md in a .github or .github-private repository for broader availability across all repositories in your org
Featured examples from our partners with real developer workflows
Here are real engineering workflows, solved with a single command via custom agents.
Trigger and resolve incidents faster (PagerDuty Incident Responder)
copilot --agent=pagerduty-incident-responder \
--prompt "Summarize active incidents and propose the next investigation steps."
Use this agent to:
Pull context from PagerDuty alerts
Generate a clear overview of incident state
Recommend investigation paths
Draft incident updates for your team
Fix vulnerable dependencies and strengthen your supply chain (JFrog Security Agent)
copilot --agent=jfrog-security \
--prompt "Scan for vulnerable dependencies and provide safe upgrade paths."
Use this agent to:
Identify vulnerable packages
Provide recommended upgrade versions
Patch dependency files directly
Generate a clear, security-aware pull request summary
Modernize database workflows and migrations (Neon)
copilot --agent=neon-migration-specialist \
--prompt "Review this schema migration for safety and best practices."
Use this agent to:
Validate schema changes
Avoid unsafe migrations
Tune analytical workflows
Optimize transformations and queries
Speed up product experimentation and feature rollouts (Amplitude Experiment Implementation)
copilot --agent=amplitude-experiment-implementation \
--prompt "Integrate an A/B test for this feature and generate tracking events."
Use this agent to:
Generate experiment scaffolding
Insert clean, consistent event tracking
Map variations to your product logic
Ensure your data flows correctly into Amplitude
Why this matters
By encoding your team’s patterns, rules, and tool integrations into a reusable agent, Copilot actually understands how your team works—not just the code in front of it. Custom agents help:
Stop repeating context by defining expectations once and reusing them everywhere
Share expertise automatically so the entire team can follow best practices (even when your subject matter expert is on vacation or in a different timezone)
Work directly with your tools using Model Context Protocol (MCP) servers to pull data from your DevOps, security, and observability systems
The full catalog of custom agents from our partners
We partnered across the ecosystem to create custom agents that solve real engineering problems.
Observability and monitoring
Dynatrace Observability and Security Expert: Configure and optimize Dynatrace monitoring for your applications
Terraform Infrastructure Agent: Write, review, and optimize Terraform infrastructure as code
Arm Migration Agent: Migrate applications to Arm-based architectures
Octopus Release Notes Expert: Generate comprehensive release notes from deployment data
DiffBlue Java Unit Test Custom Agent: Generate fast, reliable Java unit tests using DiffBlue’s AI-powered test generation engine to improve coverage and catch regressions automatically
Incident response and project management
PagerDuty Incident Responder: Triage and respond to production incidents
Monday Bug Context Fixer: Pull context from monday.com to resolve bugs faster
Feature management and experimentation
LaunchDarkly Flag Cleanup: Identify and safely remove obsolete feature flags
Amplitude Experiment Implementation: Implement A/B tests and experiments
API integration and automation
Apify Integration Expert: Integrate web scraping and automation workflows
Lingo.dev Internationalization Implementation Custom Agent: Detect, extract, and implement internationalization patterns across your codebase for seamless localization
Factory.ai Code Spec Custom Agent: Install, configure, and automate development workflows using Droid CLI for CI/CD pipelines
Run any of them with the following command:
copilot --agent=<agent-name> --prompt "<task>"
Get started
Custom agents shift Copilot from “help write this code” to “help build software the way our team builds software.”
These agents are also available now for all GitHub Copilot users, and you should try one:
copilot --agent=terraform-agent --prompt "Review my IaC for issues"
When AI systems were just a single model behind an API, life felt simpler. You trained, deployed, and maybe fine-tuned a few hyperparameters.
But that world’s gone. Today, AI feels less like a single engine and more like a busy city—a network of small, specialized agents constantly talking to each other, calling APIs, automating workflows, and making decisions faster than humans can even follow.
And here’s the real challenge: The smarter and more independent these agents get, the harder it becomes to stay in control. Performance isn’t what slows us down anymore. Governance is.
How do we make sure these agents act ethically, safely, and within policy? How do we log what happened when multiple agents collaborate? How do we trace who decided what in an AI-driven workflow that touches user data, APIs, and financial transactions?
That’s where the idea of engineering governance into the stack comes in. Instead of treating governance as paperwork at the end of a project, we can build it into the architecture itself.
From Model Pipelines to Agent Ecosystems
In the old days of machine learning, things were pretty linear. You had a clear pipeline: collect data, train the model, validate it, deploy, monitor. Each stage had its tools and dashboards, and everyone knew where to look when something broke.
But with AI agents, that neat pipeline turns into a web. A single customer-service agent might call a summarization agent, which then asks a retrieval agent for context, which in turn queries an internal API—all happening asynchronously, sometimes across different systems.
It’s less like a pipeline now and more like a network of tiny brains, all thinking and talking at once. And that changes how we debug, audit, and govern. When an agent accidentally sends confidential data to the wrong API, you can’t just check one log file anymore. You need to trace the whole story: which agent called which, what data moved where, and why each decision was made. In other words, you need full lineage, context, and intent tracing across the entire ecosystem.
Why Governance Is the Missing Layer
Governance in AI isn’t new. We already have frameworks like NIST’s AI Risk Management Framework (AI RMF) and the EU AI Act defining principles like transparency, fairness, and accountability. The problem is these frameworks often stay at the policy level, while engineers work at the pipeline level. The two worlds rarely meet. In practice, that means teams might comply on paper but have no real mechanism for enforcement inside their systems.
What we really need is a bridge—a way to turn those high-level principles into something that runs alongside the code, testing and verifying behavior in real time. Governance shouldn’t be another checklist or approval form; it should be a runtime layer that sits next to your AI agents—ensuring every action follows approved paths, every dataset stays where it belongs, and every decision can be traced when something goes wrong.
The Four Guardrails of Agent Governance
Policy as code
Policies shouldn’t live in forgotten PDFs or static policy docs. They should live next to your code. By using tools like the Open Policy Agent (OPA), you can turn rules into version-controlled code that’s reviewable, testable, and enforceable. Think of it like writing infrastructure as code, but for ethics and compliance. You can define rules such as:
Which agents can access sensitive datasets
Which API calls require human review
When a workflow needs to stop because the risk feels too high
This way, developers and compliance folks stop talking past each other—they work in the same repo, speaking the same language.
And the best part? You can spin up a Dockerized OPA instance right next to your AI agents inside your Kubernetes cluster. It just sits there quietly, watching requests, checking rules, and blocking anything risky before it hits your APIs or data stores.
Governance stops being some scary afterthought. It becomes just another microservice. Scalable. Observable. Testable. Like everything else that matters.
Observability and auditability
Agents need to be observable not just in performance terms (latency, errors) but in decision terms. When an agent chain executes, we should be able to answer:
Who initiated the action?
What tools were used?
What data was accessed?
What output was generated?
Modern observability stacks—Cloud Logging, OpenTelemetry, Prometheus, or Grafana Loki—can already capture structured logs and traces. What’s missing is semantic context: linking actions to intent and policy.
Imagine extending your logs to capture not only “API called” but also “Agent FinanceBot requested API X under policy Y with risk score 0.7.” That’s the kind of metadata that turns telemetry into governance.
When your system runs in Kubernetes, sidecar containers can automatically inject this metadata into every request, creating a governance trace as natural as network telemetry.
Dynamic risk scoring
Governance shouldn’t mean blocking everything; it should mean evaluating risk intelligently. In an agent network, different actions have different implications. A “summarize report” request is low risk. A “transfer funds” or “delete records” request is high risk.
By assigning dynamic risk scores to actions, you can decide in real time whether to:
Allow it automatically
Require additional verification
Escalate to a human reviewer
You can compute risk scores using metadata such as agent role, data sensitivity, and confidence level. Cloud providers like Google Cloud Vertex AI Model Monitoring already support risk tagging and drift detection—you can extend those ideas to agent actions.
The point isn’t to slow agents down but to make their behavior context-aware.
Regulatory mapping
Frameworks like NIST AI RMF and the EU AI Act are often seen as legal mandates. In reality, they can double as engineering blueprints.
Governance principle
Engineering implementation
Transparency
Agent activity logs, explainability metadata
Accountability
Immutable audit trails in Cloud Logging/Chronicle
Robustness
Canary testing, rollout control in Kubernetes
Risk management
Real-time scoring, human-in-the-loop review
Mapping these requirements into cloud and container tools turns compliance into configuration.
Once you start thinking of governance as a runtime layer, the next step is to design what that actually looks like in production.
Building a Governed AI Stack
Let’s visualize a practical, cloud native setup—something you could deploy tomorrow.
All of these can run on Kubernetes with Docker containers for modularity. The governance layer acts as a smart proxy—it intercepts agent calls, evaluates policy and risk, then logs and forwards the request if approved.
In practice:
Each agent’s container registers itself with the governance service.
Policies live in Git, deployed as ConfigMaps or sidecar containers.
Logs flow into Cloud Logging or Elastic Stack for searchable audit trails.
A Chronicle or BigQuery dashboard visualizes high-risk agent activity.
This separation of concerns keeps things clean: Developers focus on agent logic, security teams manage policy rules, and compliance officers monitor dashboards instead of sifting through raw logs. It’s governance you can actually operate—not bureaucracy you try to remember later.
Lessons from the Field
When I started integrating governance layers into multi-agent pipelines, I learned three things quickly:
It’s not about more controls—it’s about smarter controls. When all operations have to be manually approved, you will paralyze your agents. Focus on automating the 90% that’s low risk.
Logging everything isn’t enough. Governance requires interpretable logs. You need correlation IDs, metadata, and summaries that map events back to business rules.
Governance has to be part of the developer experience. If compliance feels like a gatekeeper, developers will route around it. If it feels like a built-in service, they’ll use it willingly.
In one real-world deployment for a financial-tech environment, we used a Kubernetes admission controller to enforce policy before pods could interact with sensitive APIs. Each request was tagged with a “risk context” label that traveled through the observability stack. The result? Governance without friction. Developers barely noticed it—until the compliance audit, when everything just worked.
Human in the Loop, by Design
Despite all the automation, people should also be involved in making some decisions. A healthy governance stack knows when to ask for help. Imagine a risk-scoring service that occasionally flags “Agent Alpha has exceeded transaction threshold three times today.” As an alternative to blocking, it may forward the request to a human operator via Slack or an internal dashboard. That is not a weakness but a good indication of maturity when an automated system requires a person to review it. Reliable AI does not imply eliminating people; it means knowing when to bring them back in.
Avoiding Governance Theater
Every company wants to say they have AI governance. But there’s a difference between governance theater—policies written but never enforced—and governance engineering—policies turned into running code.
When you can measure governance, you can improve it. That’s how you move from pretending to protect systems to proving that you do. The future of AI isn’t just about building smarter models; it’s about building smarter guardrails. Governance isn’t bureaucracy—it’s infrastructure for trust. And just as we’ve made automated testing part of every CI/CD pipeline, we’ll soon treat governance checks the same way: built in, versioned, and continuously improved.
True progress in AI doesn’t come from slowing down. It comes from giving it direction, so innovation moves fast but never loses sight of what’s right.