There is another update available for Microsoft’s delightful PowerToys utility collection. Hot on the heels of the recent release that saw the addition of a new tool comes PowerToys v0.90.1. Coming so soon after version 0.90.0 shows the pace at which those developing PowerToys are working and in this, instance it sees important improvements to the brand-new Command Palette module. There is a lot that could be learned by the Windows 11 development team from the speed at which issues have been fixed in PowerToys. See also: While it is always slightly disappointing to have a PowerToys release which does… [Continue Reading]

|
Sr. Content Developer at Microsoft, working remotely in PA, TechBash conference organizer, former Microsoft MVP, Husband, Dad and Geek.
|

Pennsylvania, USA

Ryan chats with Amr Awadallah, founder and CEO of GenAI platform Vectara. They cover how retrieval-augmented generation (RAG) has advanced, why fact-checking and accurate data are essential in building AI applications, and how Vectara’s Mockingbird model seeks to minimize hallucinations.
Pennsylvania, USA
The ongoing proliferation of AI coding tools is not only boosting developers’ efficiency, it also signals a future where AI will generate a growing share of all new code. GitHub CEO Thomas Dohmke (opens in new tab) predicted as much in 2023, when he said that “sooner than later, 80% of the code is going to be written by Copilot.”
Both large and small software companies are already heavily using AI to generate code. Y Combinator’s Garry Tan (opens in new tab) noted that 95% of code for a quarter of Y Combinator’s latest batch of startups was written by large language models.
In fact, most developers spend the majority of their time debugging code, not writing it. As maintainers of popular open-source repositories, this resonates with us. But what if an AI tool could propose fixes for hundreds of open issues, and all we had to do was approve them before merging? This was what motivated us to maximize the potential time savings from AI coding tools by teaching them to debug code.
By debugging we mean the interactive, iterative process to fix code. Developers typically hypothesize why their code crashed, then gather evidence by stepping through the program and examining variable values. They often use debugging tools like pdb (Python debugger) to assist in gathering information. This process is repeated until the code is fixed.
Today’s AI coding tools boost productivity and excel at suggesting solutions for bugs based on available code and error messages. However, unlike human developers, these tools don’t seek additional information when solutions fail, leaving some bugs unaddressed, as you can see in this simple demo of how a mislabeled column stumps today’s coding tools (opens in new tab). This may leave users feeling like AI coding tools don’t understand the full context of the issues they are trying to solve.
Introducing debug-gym
A natural research question emerges: to what degree can LLMs use interactive debugging tools such as pdb? To explore this question, we released debug-gym (opens in new tab) – an environment that allows code-repairing agents to access tools for active information-seeking behavior. Debug-gym expands an agent’s action and observation space with feedback from tool usage, enabling setting breakpoints, navigating code, printing variable values, and creating test functions. Agents can interact with tools to investigate code or rewrite it, if confident. We believe interactive debugging with proper tools can empower coding agents to tackle real-world software engineering tasks and is central to LLM-based agent research. The fixes proposed by a coding agent with debugging capabilities, and then approved by a human programmer, will be grounded in the context of the relevant codebase, program execution and documentation, rather than relying solely on guesses based on previously seen training data.
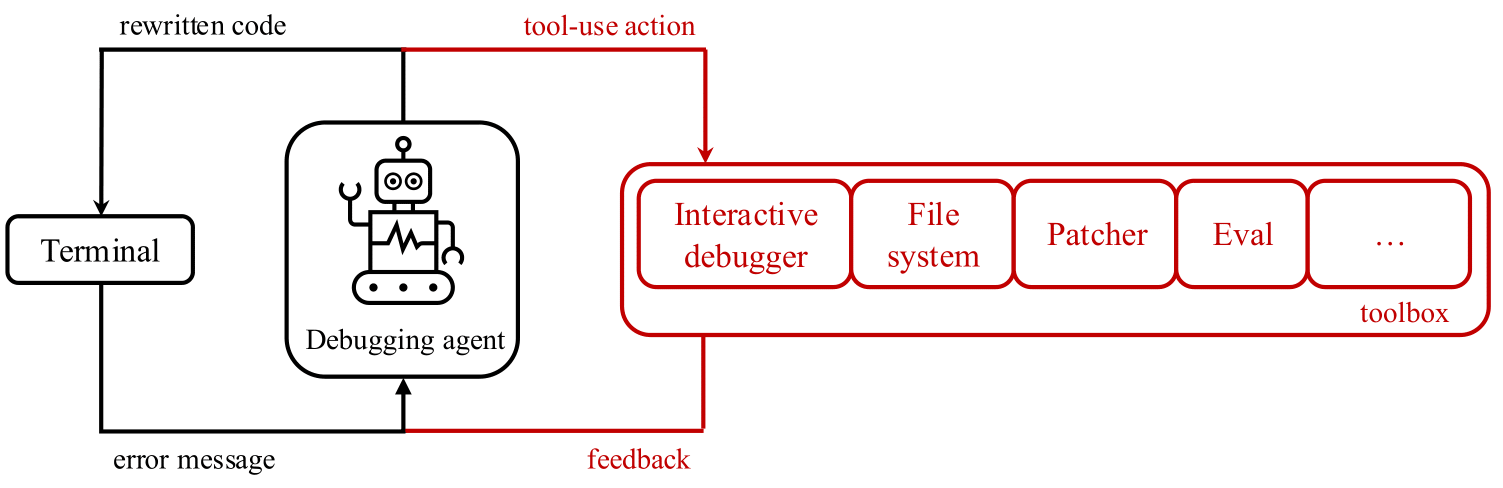
Debug-gym is designed and developed to:
- Handle repository-level information: the full repository is available to agents in debug-gym, allowing them to navigate and edit files.
- Be robust and safe: to safeguard both the system and the development process, debug-gym runs code within sandbox Docker containers. This isolates the runtime environment, preventing harmful actions while still allowing thorough testing and debugging.
- Be easily extensible: debug-gym was conceived with extensibility in mind and provides practitioners with the possibility of easily adding new tools.
- Be text-based: debug-gym represents observation information in structured text (e.g., JSON format) and defines a simple syntax for text actions, making the environment fully compatible with modern LLM-based agents.
With debug-gym, researchers and developers can specify a folder path to work with any custom repository to evaluate their debugging agent’s performance. Additionally, debug-gym includes three coding benchmarks to measure LLM-based agents’ performance in interactive debugging: Aider for simple function-level code generation, Mini-nightmare for short, hand-crafted buggy code examples, and SWE-bench for real-world coding problems requiring a comprehensive understanding of a large codebase and a solution in the format of a GitHub pull request.
To learn more about debug-gym and start using it to train your own debugging agents, please refer to the technical report (opens in new tab) and GitHub (opens in new tab).
Early experimentation: promising signal
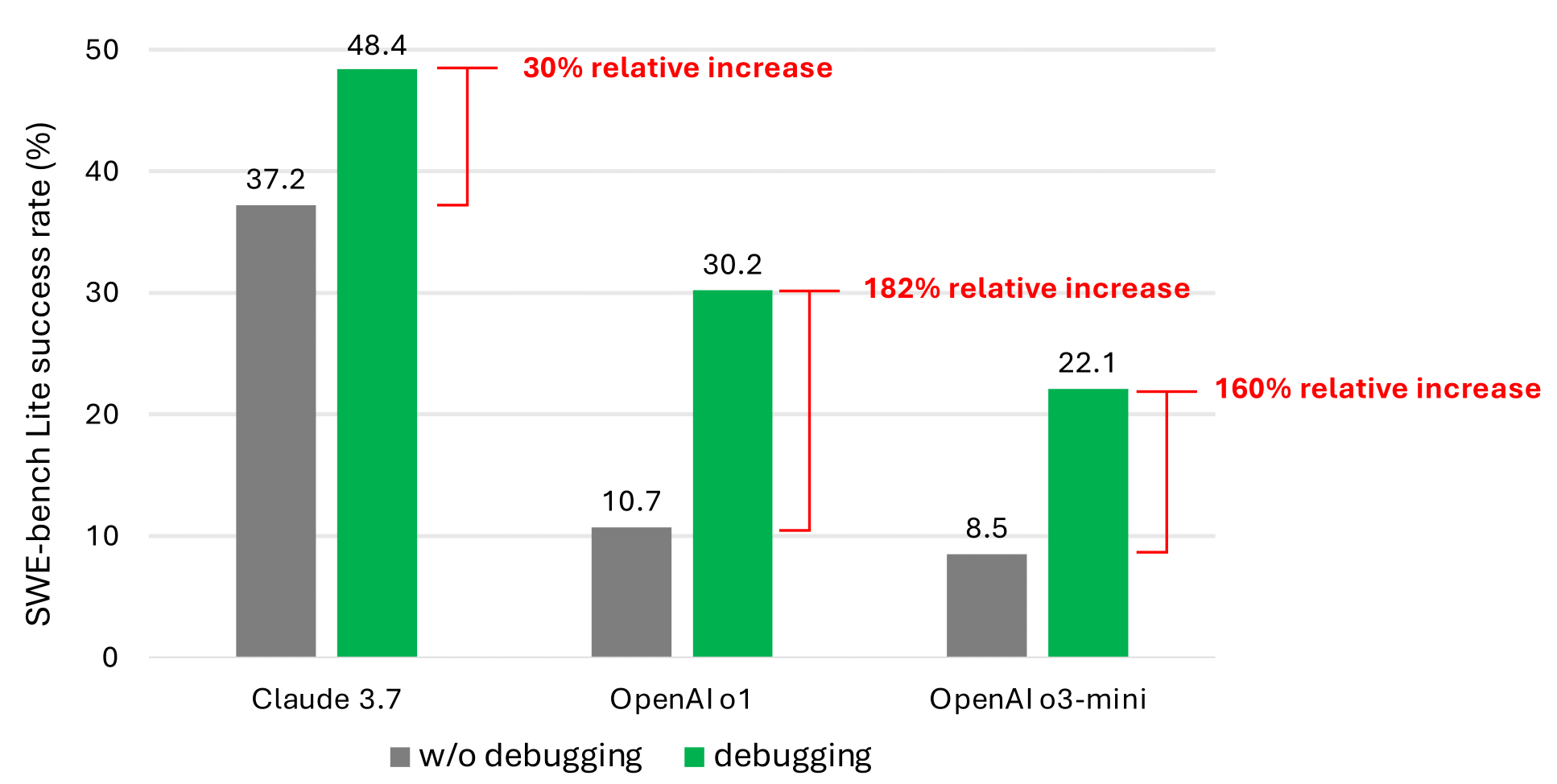
For our initial attempt to validate that LLMs perform better on coding tests when they have access to debugging tools, we built a simple prompt-based agent and provided it with access to the following debug tools: eval, view, pdb, rewrite, and listdir. We used nine different LLMs as the backbone for our agent. Detailed results can be found in the technical report (opens in new tab). (opens in new tab)
Even with debugging tools, our simple prompt-based agent rarely solves more than half of the SWE-bench (opens in new tab)Lite issues. We believe this is due to the scarcity of data representing sequential decision-making behavior (e.g., debugging traces) in the current LLM training corpus. However, the significant performance improvement (as shown in the most promising results in the graph below) validates that this is a promising research direction.
Microsoft research podcast

Ideas: AI and democracy with Madeleine Daepp and Robert Osazuwa Ness
As the “biggest election year in history” comes to an end, researchers Madeleine Daepp and Robert Osazuwa Ness and Democracy Forward GM Ginny Badanes discuss AI’s impact on democracy, including the tech’s use in Taiwan and India.
Future work
We believe that training or fine-tuning LLMs can enhance their interactive debugging abilities. This requires specialized data, such as trajectory data that records agents interacting with a debugger to gather information before suggesting a fix. Unlike conventional reasoning problems, interactive debugging involves generating actions at each step that trigger feedback from the environment. This feedback helps the agent make new decisions, requiring dense data like the problem description and the sequence of actions leading to the solution.
Our plan is to fine-tune an info-seeking model specialized in gathering the necessary information to resolve bugs. The goal is to use this model to actively build relevant context for a code generation model. If the code generation model is large, there is an opportunity to build a smaller info-seeking model that can provide relevant information to the larger one, e.g., a generalization of retrieval augmented generation (RAG), thus saving AI inference costs. The data collected during the reinforcement learning loop to train the info-seeking model can also be used to fine-tune larger models for interactive debugging.
We are open-sourcing debug-gym to facilitate this line of research. We encourage the community to help us advance this research towards building interactive debugging agents and, more generally, agents that can seek information by interacting with the world on demand.
Acknowledgements
We thank Ruoyao Wang for their insightful discussion on building interactive debugging agents, Chris Templeman and Elaina Maffeo for their team coaching, Jessica Mastronardi and Rich Ciapala for their kind support in project management and resource allocation, and Peter Jansen for providing valuable feedback for the technical report.
Opens in a new tabThe post Debug-gym: an environment for AI coding tools to learn how to debug code like programmers appeared first on Microsoft Research.
Pennsylvania, USA
This week, we discuss the rise of MCP, Google’s Agent2Agent protocol, and 20 years of Git. Plus, lazy ways to get rid of your junk.
Watch the YouTube Live Recording of Episode 514
Runner-up Titles
- They like to keep it tight, but I’ll distract them
- Bring some SDT energy
- Salesforce is where AI goes to struggle
- I like words
Rundown
Relevant to your Interests
- JFrog Survey Surfaces Limited DevSecOps Gains - DevOps.com
- Raspberry Pi’s sliced profits are easier to swallow than its valuation
- 'I begin spying for Deel':
- Bill Gates Publishes Original Microsoft Source Code in a Blog Post
- WordPress.com owner Automattic is laying off 16 percent of workers
- Intel, TSMC recently discussed chipmaking joint venture
- TikTok deal scuttled because of Trump's tariffs on China
- NVIDIA Finally Adds Native Python Support to CUDA
- Cloudflare Acquires Outerbase
- UK loses bid to keep Apple appeal against demand for iPhone 'backdoor' a secret
- Cloud Asteroids | Wiz
- Unpacking Google Cloud Platform’s Acquisition Of Wiz
- Trade, Tariffs, and Tech
- Google Workspace gets automation flows, podcast-style summaries
- Zelle is shutting down its app. Here’s how you can still use the service
- One year ago Redis changed its license – and lost most of its external contributors
- Tailscale raises $160 Million (USD) Series C to build the New Internet
Nonsense
Listener Feedback
Conferences
- Tanzu Annual Update AI PARTY!, April 16th, Coté speaking
- DevOps Days Atlanta, April 29th-30th
- Cloud Foundry Day US, May 14th, Palo Alto, CA, Coté speaking
- Free AI workshop, May 13th. day before Cloud Foundry Day
- NDC Oslo, May 21st-23th, Coté speaking
SDT News & Community
- Join our Slack community
- Email the show: questions@softwaredefinedtalk.com
- Free stickers: Email your address to stickers@softwaredefinedtalk.com
- Follow us on social media: Twitter, Threads, Mastodon, LinkedIn, BlueSky
- Watch us on: Twitch, YouTube, Instagram, TikTok
- Book offer: Use code SDT for $20 off "Digital WTF" by Coté
- Sponsor the show: ads@softwaredefinedtalk.com
Recommendations
- Brandon: KONNWEI KW208 12V Car Battery Tester
- Matt: Search Engine: The Memecoin Casino
- Coté: :Knipex Cobra High-Tech Water Pump Pliers
Photo Credits
Download audio: https://aphid.fireside.fm/d/1437767933/9b74150b-3553-49dc-8332-f89bbbba9f92/00ad35fa-3008-4aad-87d1-e4e9660e81cc.mp3
Pennsylvania, USA
We're sitting down with Eric Matthes, the educator, author, and developer behind Django Simple Deploy. If you've ever struggled with taking that final step of getting your Django app onto a live server (without spending days wrestling with DevOps complexities), then give Django Simple Deploy a look. Eric shares how Django Simple Deploy automates away the boilerplate parts of deployment, so you can focus on building features instead of deciphering endless configs. We'll talk about this new project's journey to 1.0, the range of hosting platforms it supports, and why it's not just for beginners.
Episode sponsors
Worth Recruiting
Talk Python Courses
Download audio: https://talkpython.fm/episodes/download/500/django-simple-deploy-and-other-devops-things.mp3
Episode sponsors
Worth Recruiting
Talk Python Courses
Links from the show
django-simple-deploy documentation: readthedocs.io
django-simple-deploy repository: github.com
Python Crash Course book: ehmatthes.github.io
Code Red: codered.cloud
Docker: docker.com
Caddy: caddyserver.com
Bunny.net CDN: bunny.net
Platform.sh: platform.sh
fly.io: fly.io
Heroku: heroku.com
Watch this episode on YouTube: youtube.com
Episode transcripts: talkpython.fm
--- Stay in touch with us ---
Subscribe to Talk Python on YouTube: youtube.com
Talk Python on Bluesky: @talkpython.fm at bsky.app
Talk Python on Mastodon: talkpython
Michael on Bluesky: @mkennedy.codes at bsky.app
Michael on Mastodon: mkennedy
django-simple-deploy repository: github.com
Python Crash Course book: ehmatthes.github.io
Code Red: codered.cloud
Docker: docker.com
Caddy: caddyserver.com
Bunny.net CDN: bunny.net
Platform.sh: platform.sh
fly.io: fly.io
Heroku: heroku.com
Watch this episode on YouTube: youtube.com
Episode transcripts: talkpython.fm
--- Stay in touch with us ---
Subscribe to Talk Python on YouTube: youtube.com
Talk Python on Bluesky: @talkpython.fm at bsky.app
Talk Python on Mastodon: talkpython
Michael on Bluesky: @mkennedy.codes at bsky.app
Michael on Mastodon: mkennedy
Download audio: https://talkpython.fm/episodes/download/500/django-simple-deploy-and-other-devops-things.mp3
Pennsylvania, USA
Like all good pricing questions, if you ask how much AI will cost, the answer is “it depends.” Assuming you are building an AI-enabled application, your design decisions will influence that cost - including both traditional architecture components and your choice of AI models. This article looks at application architectures, tokens, and carbon emissions.
What does an AI application look like?
When thinking about an AI application, AI is just one component. Good architecture design starts with clear requirements and right-sizing the entire application stack to meet business needs. If your application is mission critical and/or customer facing, you’re likely to incur additional costs from design choices that improve resiliency, availability and redundancy, including geo-redundancy, load balancing etc.
Example 1: This application provides a front end for customers and store admins, REST APIs for sending data to RabbitMQ message queue and MongoDB database, and console apps to simulate traffic. https://learn.microsoft.com/azure/aks/open-ai-quickstart
Example 2: A reference .NET application implementing an e-commerce website using a services-based architecture with .NET Aspire. https://github.com/dotnet/eshop
https://github.com/Azure-Samples/eShopOnAzure
Example 3: An application that provides text transcripts from podcast audio files. https://learn.microsoft.com/azure/architecture/ai-ml/idea/process-audio-files
You might be familiar with how architecture components like AKS, PostgreSQL, Azure Functions or Azure Storage are priced, but you’ll need to add estimated costs for your AI services. This starts with understanding how AI services are charged.
AI service pricing structures
Azure OpenAI Service – pricing examples Apr 2025 USD
The first thing to note is that AI models usually work on a cost basis related to the number of “tokens” that are used. Tokens are the billing meter of AI models. I say “usually”, because text-to-speech models are based on the number of characters processed. Fine-tuning models also have hourly rates, from the moment of deployment, with no way to suspend them/power them down like you can a virtual machine.
Tokens are the way an AI model interprets characters, of both input (i.e. prompts) and output (responses). We use tokens because they are consistent, whereas the conversion from characters to token varies. Newer models are more efficient at breaking words into tokens, for example recognising “I’m” as one token instead of two “I” and “’m”. Token counts also vary between different languages (e.g. English or Spanish). AI models don’t see words like humans do but look at common sequences of characters and predict the next token in a sequence.
OpenAI provides a tokenizer where you can insert a sample of text, and it will convert it to tokens. In the example video below, we’ve generated a sample of a conversation that someone might have with a website chatbot regarding products for hiking.
By generating a token number, we could multiple that by how many current website users we have, how many we think may interact with a chatbot, and a little room for growth. Note: this math is just based on input tokens – the characters submitted by the human, not the AI response (which is charged as output tokens). It’s advantageous to optimize the number of tokens processed by the AI service, and we’ll discuss that in more detail in a later post.
That’s not the only AI service that Microsoft offers though. As another example, Azure AI Search has a more familiar SKU approach, with SKUs having a combination of storage, indexes and scale out limits, at an hourly rate per scale unit:
Azure AI Search – Pricing example Apr 2025 USD
Architecture, usage and cost considerations
For all workloads, including AI, the FinOps Framework capabilities of architecting for the cloud and planning & estimating are key. This is a combination of understanding architectures & usage patterns, understanding the impacts of architecture change, and defining the scope and requirements of your estimates. You can’t figure out how much AI will cost if you don’t understand how it is billed. And you may make design decisions that are not cost optimized if you don’t consider how to optimize or cache tokens (input/output).
It also helps to accurately estimate how much your AI workload will be used, but especially if AI hasn’t been adopted in your organization yet, this may require a smaller launch group or proof of concept to test your usage assumptions.
Carbon Emissions
Whether your organization has formal Environment, Social and Governance (ESG) reporting requirements or not, most people understand that AI services need significant computing power. That’s not something that’s visible on a pricing sheet. The FinOps Foundation includes guidelines for considering sustainability, setting targets and making data visible. And now the Azure Carbon Optimization reporting in the Azure Portal allows you to understand in depth the emissions resulting from your use of Microsoft Azure services.
Learn more at aka.ms/AzureCarbonOptimization or try our interactive guide on the Azure Carbon Optimization tool.
Coming up next
Next time, we’ll explore cost controls for AI services - what exists to help us limit our AI costs, or get more visibility of them at a granular level?
Learn more
Managing the cost of AI: Leveraging the FinOps Framework
Microsoft Azure Pricing Calculator
Plan to manage costs for Azure OpenAI Service
Plan and manage costs of an Azure AI Search service
FinOps Foundation FinOps for AI Community: Community calls, resources and conference sessions
FinOps Foundation Cloud Sustainability Community
Microsoft eBook: Managing Environmental, Social, and Governance goals through FinOps Best Practices
Pennsylvania, USA
Next Page of Stories