We are excited to announce the general availability of Azure Storage Discovery, a fully managed service that delivers enterprise-wide visibility into your data estate in Microsoft Azure Blob Storage and Azure Data Lake Storage. Azure Storage Discovery helps you optimize storage costs, comply with security best practices, and drive operational efficiency. With the included Microsoft Copilot in Azure integration, all decision makers and data users can access and uncover valuable data management insights using simple, everyday language—no specialized programming or query skills required. The intuitive experience provides advanced data visualizations and actional intelligence that are most important to you.
Businesses are speeding up digital transformation by storing large amounts of data in Azure Storage for AI, analytics, cloud native apps, HPC, backup, and archive. This data spans multiple subscriptions, regions, and accounts to meet workload needs and compliance rules. The data sprawl makes it challenging to track data growth, spot unexpected data reduction, or optimize costs without clear visibility into data trends and access patterns. Organizations struggle to identify which datasets and business units drive growth and usage the most. Without a global view and streamlined insights across all storage accounts, it’s challenging to ensure data availability, residency, security, and redundancy are consistently aligned with best practices and regulatory compliance requirements.
Azure Storage Discovery makes it simple to gain and analyze insights to manage such large data estates.
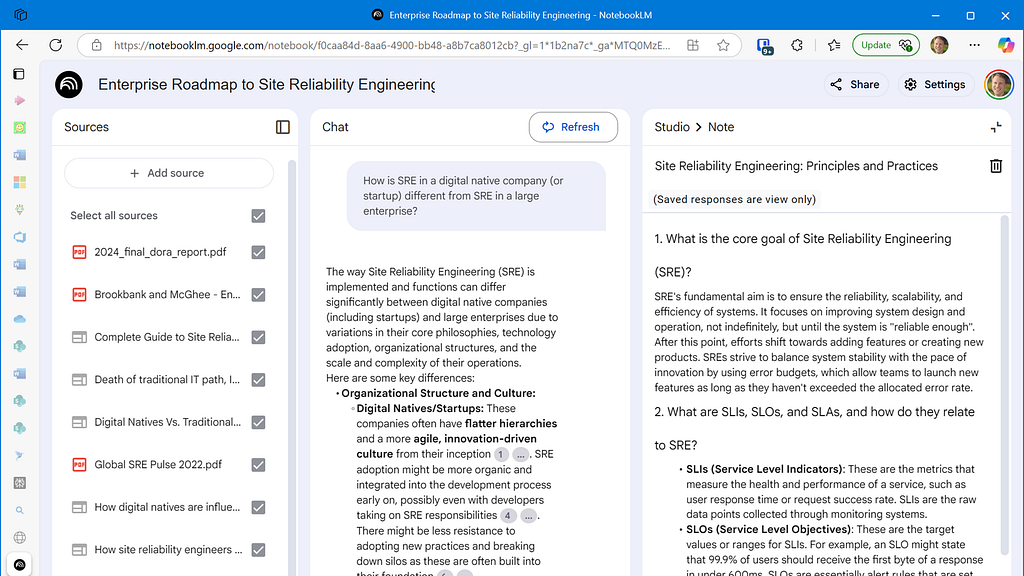
Analyze your data estate with Azure Storage Discovery
Azure Storage Discovery lets you easily set up a workspace with storage accounts from any region or subscription you can access. The first insights are available in less than 24 hours, and you can get started by analyzing your data estate.
Unlock intelligent insights using natural language with Copilot in Azure
Use natural language to ask for the storage insights you need to accomplish your storage management goals. Copilot in Azure expresses them using rich data visualizations, like tables and charts.
Interactive reports built into the Azure portal
Azure Storage Discovery generates out-of-box dashboards you can access from the Azure portal, with insights that help you visualize and analyze your data estate. The reports include filters for your storage data estate by region, redundancy, and performance, allowing you to quickly drill down and uncover the insights important to you.
Advanced storage insights
The reports deliver insights, at a glance, across multiple dimensions, helping you manage your data effectively:
- Capacity: Insights about resource, object sizes, and counts aggregated by subscriptions, resource groups, and storage accounts with growth trends.
- Activity: Visualize transactions, ingress, and egress for insights on how your storage is accessed and utilized.
- Security: Highlights critical security configurations of your storage resources with outliers including public network access, shared access key, anonymous access to blobs, and encryption settings.
- Configurations: Surfaces configuration patterns across your storage accounts like redundancy, lifecycle management, inventory, and others.
- Errors: Highlights failed operations and error codes to help identify patterns of issues that might be impacting workloads.
Kickstart your insights for free, including 15 days of historical data
Getting started is easy with access to 15 days of historical insights within hours of deploying your Azure Storage Discovery workspace. The standard pricing plan offers the most comprehensive set of insights, while the free pricing plan gets you going with the basics.
Analyze long term trends with 18 months of insights
The Azure Storage Discovery workspace with the standard pricing plan, will retain insights for up to 18 months so you can analyze long-term trends and any business or season specific workload patterns.
Azure Storage Discovery is available to you today! You can learn more about Azure Storage Discovery here and even get started in the Azure Portal here.
Use Copilot to solve the most important business problems
During the design of Azure Storage Discovery, we spoke with many customers across various business-critical roles, such as IT managers, data engineers, and CIOs. We realized AI could simplify onboarding by removing the need for infrastructure deployment or coding knowledge. As a result, we included Copilot in Azure Storage Discovery from the start. It offers insights beyond standard reports and dashboards using natural language queries to deliver actionable information through visualizations like trend charts and tables.
To get started, simply navigate to your Azure Storage Discovery workspace resource in the Azure portal, and activate Copilot.
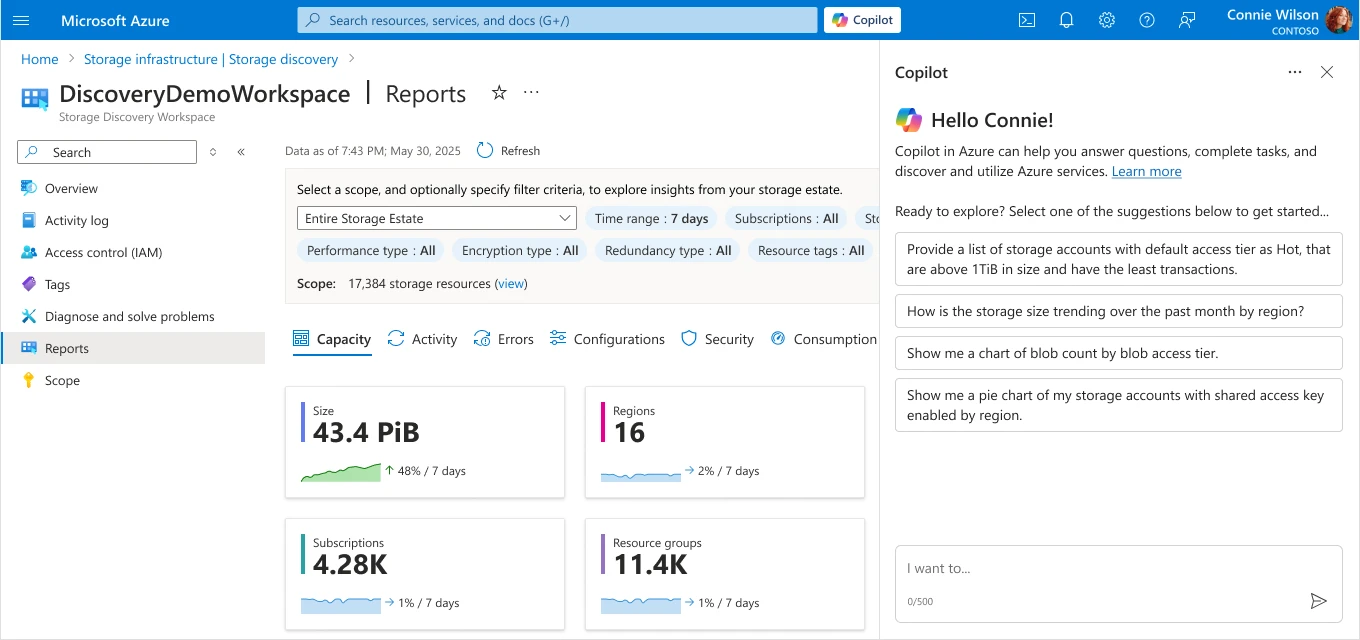
Identify opportunity to optimize costs
Understanding storage size trends is crucial for cost optimization, and analyzing these trends by region and performance type can reveal important patterns about how the data is evolving over time. With Azure Storage Discovery’s 18 months of data retention, you can uncover long-term trends and unexpected changes across your data estate, while Copilot quickly visualizes storage size trends broken down by region.
“How is the storage size trending over the past month by region?”
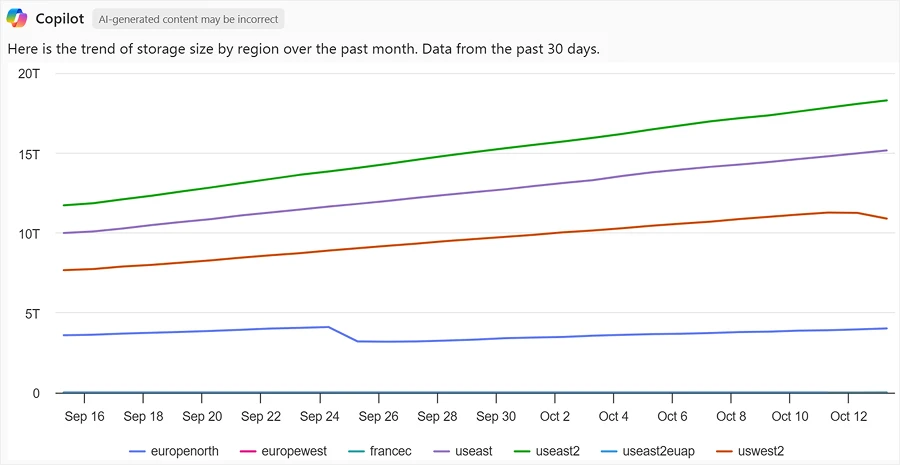
Finding cost-saving opportunities across many storage accounts can be difficult, but Copilot simplifies this by highlighting accounts with the highest savings potential based on capacity and transactions as shown below.
“Provide a list of storage accounts with default access tier as Hot, that are above 1TiB in size and have the least transactions”
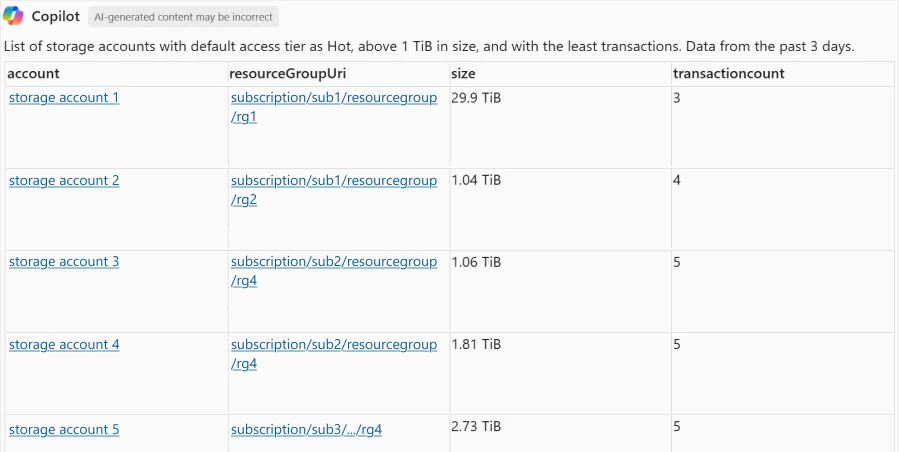
Before taking any action, you can dive even deeper into the insights by evaluating distributions. For example, a distribution of access tiers across blobs.
“Show me a chart of blob count by blob access tier”
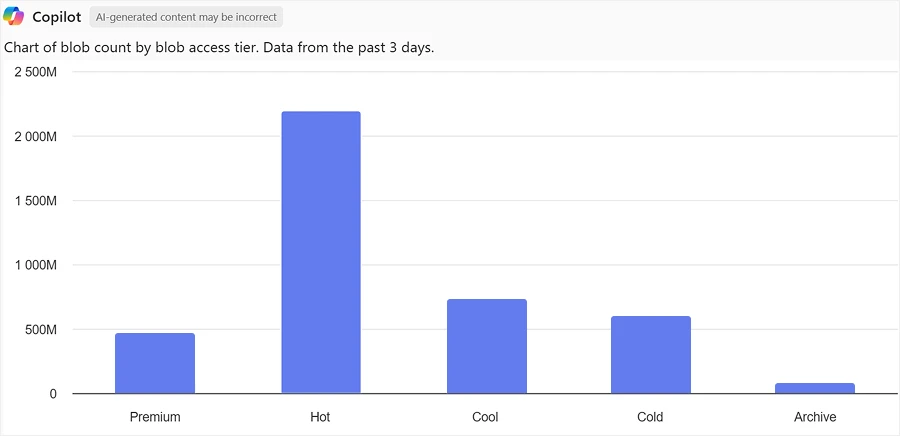
Knowing that the majority of objects are still in the Hot tier provides immediate opportunities to reduce costs by enabling Azure Storage Actions to tier down or even delete data that is not accessed frequently. Azure Storage Actions is a fully managed, serverless platform that automates data management tasks—like tiering, retention, and metadata updates—across millions of blobs in Azure Blob Storage and Data Lake Storage.
Assess whether storage configurations align with security best practices
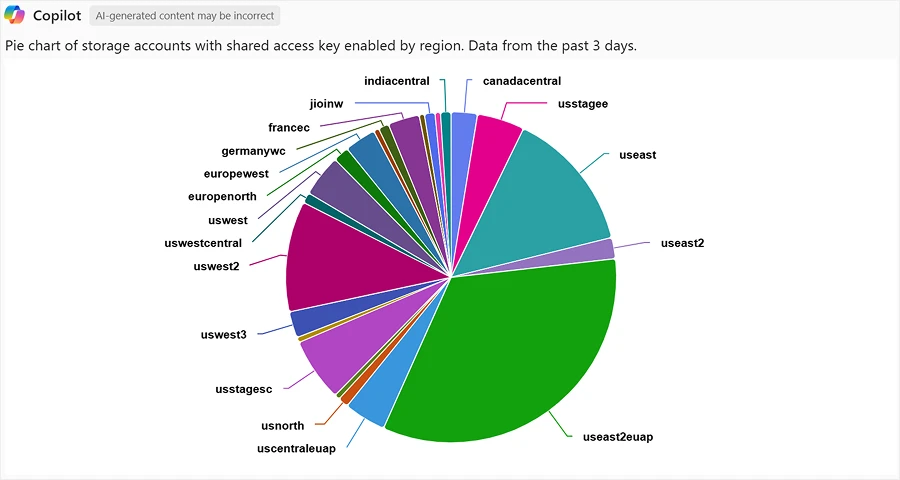
For better storage security, Microsoft recommends using Microsoft Entra ID with managed identities instead of Shared Key authentication. Azure Storage Discovery enables you to quickly see that there are still many storage accounts with shared access keys enabled and drill down into a list of Storage accounts that need optimization.
“Show me a pie chart of my storage accounts with shared access key enabled by region”
Manage your data redundancy requirements
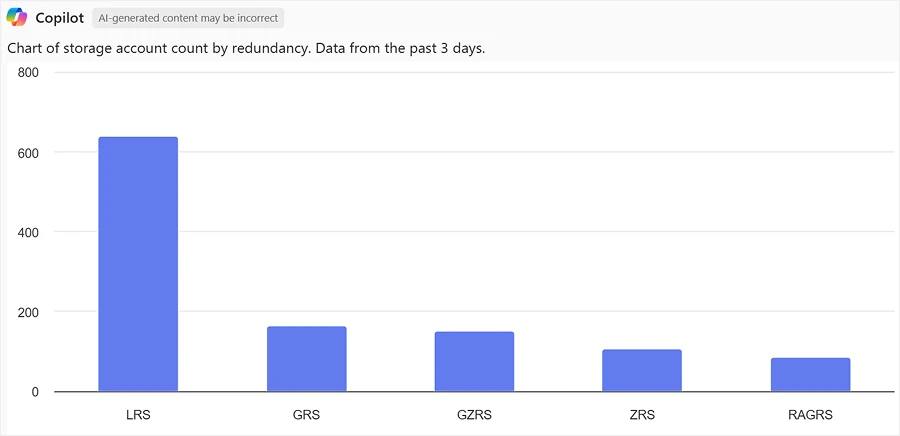
Azure provides several redundancy options to meet data availability, disaster recovery, performance, and cost needs. These choices should be regularly reviewed against risks and benefits for an effective storage strategy. Azure Storage Discovery quickly shows the redundancy configuration for all storage accounts and allows you to analyze the most suitable option for each workload and critical business data.
“Show me a chart of my storage account count by redundancy”
Pricing and availability
A single Azure Storage Discovery workspace can analyze the subscriptions and storage accounts from all supported regions. Learn more about the regions supported by Azure Storage Discovery here. The service offers a free pricing plan with insights related to capacity and configurations retained for up to 15 days and a standard pricing plan that also includes advanced insights related to activity, errors, and security configurations. Insights are retained for up to 18 months, allowing you to analyze trends and business cycles.
Learn more about the pricing plans in the Azure Storage Discovery documentation and access the prices for your region here.
Get started with Azure Storage Discovery
Getting started with Azure Storage Discovery is easy. Simply follow these two steps:
- Configure an Azure Storage Discovery workspace and select the set of subscriptions and resource groups containing your storage accounts.
- Define the “Scopes” that represent your business groups or workloads.
That’s it! Give it a moment. Once a workspace is configured, Azure Storage Discovery starts aggregating the relevant insights and makes them available to you via intuitive charts. You’ll find them in the Azure portal, on different report pages of your workspace. We’ll even look back in time and provide 15 days of historic data. Your insights are typically available within a few hours.
To get started, visit Azure Storage Discovery in the Azure Marketplace.
You can also deploy via the brand new Storage Center in the Azure portal. Find Azure Storage Discovery in the “Data management” section.
Want to read more before deploying? The planning guide walks you through all the important considerations for a successful Azure Storage Discovery deployment.
We’d love to hear your feedback. What insights are most valuable to you? What would make Azure Storage Discovery more valuable for your business? Let us know at: StorageDiscoveryFeedback@service.microsoft.com.
The post From queries to conversations: Unlock insights about your data using Azure Storage Discovery—now generally available appeared first on Microsoft Azure Blog.