Galaxy XR costs $1,800, nearly half the price of the Vision Pro.

|
Sr. Content Developer at Microsoft, working remotely in PA, TechBash conference organizer, former Microsoft MVP, Husband, Dad and Geek.
|

Pennsylvania, USA

If you’re like me, you love writing code – it’s fun and solves real problems. But too often, we end up wrestling with tooling before we can even start, especially in Python with its dreadful dependency management.
Using pip is like assembling IKEA furniture without instructions. Add a single package, and suddenly you’re battling dependency conflicts, version chaos, and cryptic errors – decoding them feels like reading an ancient language.
I can’t even run a simple script without either polluting my global environment or creating a virtual environment for a one-off script I’ll never run again.
It’s ridiculous how something that should simplify our lives makes it more complicated, especially compared to other ecosystems. Having previously worked with Ruby and its beautiful and mature gem system, I felt like switching to Python downgraded my experience.
Simplifying Python projects with uv
As engineers, we desire simple, robust, and predictable solutions. Yet here I was, praying that my environment wouldn’t implode every time I made a tiny change or – God forbid – updated a package version.
After some search (and reading the excellent book Hypermodern Python Tooling), I’ve found an alternative that solved most of my issues in one swoop: uv – a fast, modern, and reliable Python dependency management tool.
It streamlined the internal process of developing Python services within our team and made us more productive. Our builds are faster, and it eliminated all the complexity we had from using many different tools.
In this article, I’ll convince you to leave your comfort zone and switch to using uv as your go-to tool for everything and anything Python.
The hellscape that is Python tooling
In terms of tooling, entering the Python ecosystem while previously working with Ruby (and privately with Go) felt like I replaced a reliable Toyota with a carriage drawn by a malnourished horse.
Virtual environments, pip, and dependency management wasted many engineering hours that we could have spent writing code (and producing actual value!).
Spinning up a new microservice tested your patience, as the tooling tried to ruin your day with a broken package, an unreadable error message, or sluggish build times because the cache didn’t update somewhere.
Let’s talk about real-world examples
Dependency management with pip behaves unpredictably. It can’t build anything beyond the simplest dependency graph. When you work on legacy code (and you absolutely will), updating it often breaks your functionalities. You can only debug by endlessly examining the output of pip freeze until that command engraves itself in your brain like an ancient chant.
The core problems come from the fact that pip doesn’t guarantee that two runs of installing dependencies will also install the same sub-dependencies. If you want to know more, there’s a great article about this.
Virtual environments devour disk space. The concept sounds great: if project A uses one version of dependency X, and project B uses another, you isolate them in virtual environments so every project keeps its source of truth. But in practice, you quickly drain your memory when running many Python services, each with its own project.
The problem worsens with AI-based projects: in the AI space, we often use PyTorch and that single dependency consumes at least 936MB for the CPU version and 1.8GB for the GPU version (numbers taken from the PyTorch forums, here and here).
Imagine running multiple AI projects – if we keep this up, our disk space disappears.

Say Hi to uv!
Now that we’ve established how badly Python needs better tooling, let’s look at uv.
What exactly is uv? According to their website, uv is a high-speed Python package and project manager written in Rust. Integrating uv into your workflow eliminates most of the tools you currently rely on – it directly replaces pip, pip - tools, poetry, and many more.
The core design philosophy focuses on giving you one Python development tool while also delivering extreme speed (we’ll test this later).
“Alright,” you might ask, “what can this magical tool do?” Great question! Let’s look at some of uv’s most compelling features.
Project dependency management
Managing your Python project with uv is extremely simple because uv provides first-class project support built around declarative manifests and universal lockfiles (similar to those in the JS ecosystem and Poetry).
This setup ensures reproducible installs and fast syncs. You initialize projects with uv init, add and declare dependencies (e.g., numpy and lang chain), and generate fully pinned lockfiles with uv lock.
After that, subsequent environment creations or updates (“syncs”) use that lockfile to reproduce identical sub-dependency graphs every time. In practice, this stops the endless back-and-forth of “works on my machine” messages via Slack.
Unlike plain pip install, which can produce different sub-dependency graphs on repeated runs (creating inconsistent project environments), uv lock locks everything down – you won’t encounter surprises halfway through a deployment pipeline.

Running standalone scripts
Whipping up a quick Python script to try something out is amazing – until you need packages without standard Python. Then the experience quickly turns into venv juggling and ad-hoc pip installs.
With uv, we can run standalone scripts without creating new environments: just run uv run --with [your packages] script.py to auto-install any dependencies to the cache and run your script. These commands install packages on the fly, and you can later lock them with uv lock if needed.
You can even embed metadata into your scripts to declare dependencies and required Python versions, like so:
# /// script
# requires-python = ">=3.13"
# dependencies = [
# "langchain",
# "typer==0.12.3",
# ]
# ///
import os
import langchain
# ... rest of your script ...You can save this script and run it efficiently with uv run script.py. Thanks to uv’s speedy resolver and global cache, the script runs repeatably and in milliseconds. You can finally spend less time fighting your environment and more time doing what you actually want: writing code.
Disk-Space Efficiency
Uv maintains a global cache of all downloaded packages. Once you fetch any version of a package (even a sub-dependency!), you never need to re-download or duplicate it across projects. By comparison, pip re-downloads wheels into each virtual environment, and Poetry duplicates caches in projects – these approaches waste massive amounts of disk space, which matters especially for AI-based projects and workflows.
To get a bit technical, uv keeps a single copy of each exact release in a global cache directory. Any project that needs the same version can access it via a symlink, rather than copying the entire package into the project. Beyond this cache, uv writes project-specific artifacts (e.g., compiled wheels) into a per-project store. Since both stores use content hashes to identify files, uv instantly detects duplicates.
This means that if two projects depend on langchain-0.3.24, uv stores that version only once.
The real-world impact is visible in multi-project AI workflows. As AI engineers, we often maintain and juggle multiple PyTorch-based services.
We drastically reduce total disk usage by sharing the PyTorch wheel (approximately 1.8 GB) across various projects. As the memory footprint from dependencies shrinks, scaling up microservice-based architectures becomes more manageable.
This improvement is crucial for CI pipelines and developer workstations, which can run multiple microservices simultaneously.
Speed!
One of the main drawbacks of working in the AI space is the sheer size of all the packages and tools that a modern AI service uses. Installing all those dependencies takes time, slows down our CI/CD pipeline, and hampers our developer experience.
Naturally, install speed becomes crucial in such scenarios. The makers of uv provide speed comparison benchmarks, testing their tool against pip and Poetry.
Across all scenarios (warm/cold installs and warm/cold resolution), uv outperforms pip and Poetry by orders of magnitude.

These results come directly from uv’s official benchmarks. These benchmarks install Trio’s official dependencies. Let’s see how uv’s benefits impact our developer workflow.
Comparing uv to other tools when building an AI microservice
To compare uv with other tools (in this case, pip and poetry), we’ll walk through the common steps of building a Python application and see how much easier it is to use uv. The typical steps for creating a Python app include:
- Initializing a project
- Adding dependencies
- Locking/freezing your dependencies
- Installing/syncing packages
- Running scripts and notebooks (handy for AI/ML engineers)
To provide an at-a-glance comparison, we’ve summarized these steps in a table:

Testing Install Speed on a “real” AI microservice
To compare the experience of using uv with other tools like pip and poetry, let’s build a basic AI microservice. We’ll start with these dependencies:
fastapi==0.110.2
uvicorn[standard]==0.29.0
# AI/GenAI/LLM related
transformers==4.40.1
torch==2.2.2
scipy==1.13.0
scikit-learn==1.5.0
numpy==1.26.4
sentence-transformers==2.7.0
langchain==0.1.16
# Pydantic for data validation
pydantic==2.7.1
# Async tools
httpx==0.27.0
# Background tasks and scheduling
celery==5.4.0
redis==5.0.4
# Observability (logging, tracing, monitoring)
opentelemetry-api==1.25.0
opentelemetry-sdk==1.25.0
# Environment variables
python-dotenv==1.0.1
# ORM
sqlalchemy==2.0.30
This setup doesn’t mimic a real AI microservice; it just represents what you’d commonly find in one. We’ll create this as a Python project using three different build tools: pip, Poetry, and uv. Then, we’ll benchmark how fast these tools install the dependencies.
We’ll use Python 3.12 for our virtual environment, which should not affect the results. In addition, we run this test on Ubuntu 22.04.5 LTS. For all tests, we perform a cold installation (no cache), followed by a warm installation (with cache).

Keep in mind that cold install times depend heavily on your network speed and bandwidth, and your ISP can throttle TCP, affecting the results.
Why uv wins?
Swapping between multiple CLIs introduces cognitive overload – uv ends that. With pip and venv, you constantly toggle between Python’s venv module, manual requirements files, and pip installs. Poetry tries to put everything under its own umbrella, but still makes you chain together poetry install , poetry lock , and poetry run.
By contrast, uv gives you a single tool for all your needs and covers every workflow step. It just works. Under the hood, uv’s dependency resolver and global cache guarantee repeatable installs without spinning wheels or bloated environments.
Every project shares the same content-address store, which prevents duplicate downloads and wasted disk space.
Since uv builds from the ground up with modern workflows in mind, it provides first-class support for Python version management (Poetry requires a separate tool, pyenv, for this), workspaces (missing from Poetry), script metadata that turns Python files into portable executables (not supported by Poetry), and even built-in publishing capabilities.
In short, uv gives you a simple, lean, and fast pipeline while simultaneously replacing the old ways of dependency management in Python.
Uv in production – benefits and lessons learned
After careful consideration, we slowly started adopting uv as our go-to tool for writing new Python microservices, especially in AI. By switching to uv, we consolidated our workflow under one tool and leveraged its many benefits. The results speak for themselves: consistent, millisecond-scale installs, smaller container layers, and zero “it worked on my machine” issues across all environments.
The benefits are measurable, too. Our average CI/CD pipeline build time dropped by half for services we migrated to uv. Running multiple services locally became easier because uv provides a global cache and symlinks to dependencies, greatly reducing disk usage.
In addition, uv.lock ensures every branch and pipeline uses the same dependency graph, eliminating surprise version bumps or broken sub-dependencies.
Finally, our cognitive workload as developers decreased significantly as we removed multiple tools from our toolchain, dramatically reducing maintenance overhead.
After using uv for some time, we also discovered a few valuable tricks:
- Cache Management – Periodically running
uvcache prune keeps the cache directory clean by removing all unused entries. - Accelerator Configuration – Following uv’s PyTorch integration guide lets us pin CPU vs. CUDA builds per service declaratively, avoiding manual URL overrides. This approach allows us to install CUDA-enabled PyTorch on Linux, CPU-only builds on MacOS, and even include custom flags to enable or disable GPU builds when needed.
You should give uv a chance
As we’ve seen, traditional Python tooling too often slows us down, wastes space, and forces us to hope for reproducible builds. Uv cuts through that noise with a single, fast binary that handles every step of your workflow – from project initialization to publishing.
Uv runs much faster than its competitors, and its universal lockfile guarantees deterministic builds that work everywhere, every time.
Whether you build heavy AI pipelines, ship microservices, or maintain a monorepo filled with standalone scripts and notebooks, uv brings consistency, performance, and simplicity to your workflow.
Stop wrestling with half-baked tools and give uv a spin today – I promise it will turn your dependency hellscape into a clean, reliable experience!

The post Tame Python Chaos With uv – The Superpower Every AI Engineer Needs appeared first on ShiftMag.
Pennsylvania, USA
This article is part of a series on the Sens-AI Framework—practical habits for learning and coding with AI.
A few decades ago, I worked with a developer who was respected by everyone on our team. Much of that respect came from the fact that he kept adopting new technologies that none of us had worked with. There was a cutting-edge language at the time that few people were using, and he built an entire feature with it. He quickly became known as the person you’d go to for these niche technologies, and it earned him a lot of respect from the rest of the team.
Years later, I worked with another developer who went out of his way to incorporate specific, obscure .NET libraries into his code. That too got him recognition from our team members and managers, and he was viewed as a senior developer in part because of his expertise with these specialized tools.
Both developers built their reputations on deep knowledge of specific technologies. It was a reliable career strategy that worked for decades: Become the expert in something valuable but not widely known, and you’d have authority on your team and an edge in job interviews.
But AI is changing that dynamic in ways we’re just starting to see.
In the past, experienced developers could build deep expertise in a single technology (like Rails or React, for example) and that expertise would consistently get them recognition on their team and help them stand out in reviews and job interviews. It used to take months or years of working with a specific framework before a developer could write idiomatic code, or code that follows the accepted patterns and best practices of that technology.
But now AI models are trained on countless examples of idiomatic code, so developers without that experience can generate similar code immediately. That puts less of a premium on the time spent developing that deep expertise.
The Shift Toward Generalist Skills
That change is reshaping career paths in ways we’re just starting to see. The traditional approach worked for decades, but as AI fills in more of that specialized knowledge, the career advantage is shifting toward people who can integrate across systems and spot design problems early.
As I’ve trained developers and teams who are increasingly adopting AI coding tools, I’ve noticed that the developers who adapt best aren’t always the ones with the deepest expertise in a specific framework. Rather, they’re the ones who can spot when something looks wrong, integrate across different systems, and recognize patterns. Most importantly, they can apply those skills even when they’re not deep experts in the particular technology they’re working with.
This represents a shift from the more traditional dynamic on teams, where being an expert in a specific technology (like being the “Rails person” or the “React expert” on the team) carried real authority. AI now fills in much of that specialized knowledge. You can still build a career on deep Rails knowledge, but thanks to AI, it doesn’t always carry the same authority on a team that it once did.
What AI Still Can’t Do
Both new and experienced developers routinely find themselves accumulating technical debt, especially when deadlines push delivery over maintainability, and this is an area where experienced engineers often distinguish themselves, even on a team with wide AI adoption. The key difference is that an experienced developer often knows they’re taking on debt. They can spot antipatterns early because they’ve seen them repeatedly and take steps to “pay off” the debt before it gets much more expensive to fix.
But AI is also changing the game for experienced developers in ways that go beyond technical debt management, and it’s starting to reshape their traditional career paths. What AI still can’t do is tell you when a design or architecture decision today will cause problems six months from now, or when you’re writing code that doesn’t actually solve the user’s problem. That’s why being a generalist, with skills in architecture, design patterns, requirements analysis, and even project management, is becoming more valuable on software teams.
Many developers I see thriving with AI tools are the ones who can:
- Recognize when generated code will create maintenance problems even if it works initially
- Integrate across multiple systems without being deep experts in each one
- Spot architectural patterns and antipatterns regardless of the specific technology
- Frame problems clearly so AI can generate more useful solutions
- Question and refine AI output rather than accepting it as is
Practical Implications for Your Career
This shift has real implications for how developers think about career development:
For experienced developers: Your years of expertise are still important and valuable, but the career advantage is shifting from “I know this specific tool really well” to “I can solve complex problems across different technologies.” Focus on building skills in system design, integration, and pattern recognition that apply broadly.
For early-career developers: The temptation might be to rely on AI to fill knowledge gaps, but this can be dangerous. Those broader skills—architecture, design judgment, problem-solving across domains—typically require years of hands-on experience to develop. Use AI as a tool, but make sure you’re still building the fundamental thinking skills that let you guide it effectively.
For teams: Look for people who can adapt to new technologies quickly and integrate across systems, not just deep specialists. The “Rails person” might still be valuable, but the person who can work with Rails, integrate it with three other systems, and spot when the architecture is heading for trouble six months down the line is becoming more valuable.
The developers who succeed in an AI-enabled world won’t always be the ones who know the most about any single technology. They’ll be the ones who can see the bigger picture, integrate across systems, and use AI as a powerful tool while maintaining the critical thinking necessary to guide it toward genuinely useful solutions.
AI isn’t replacing developers. It’s changing what kinds of developer skills matter most.

Pennsylvania, USA
This article was written by an external contributor.

When it comes to writing short scripts or CRUDs, Python is a great choice. With its rich ecosystem and broad adoption, it can be easily used to scrape some data or to perform data analysis. However, maintaining a large codebase in Python can be very problematic.
Python’s dynamic typing and mutable nature, while offering flexibility for rapid development, may present additional considerations in larger codebases. Event-loop-based coroutines can be tricky and may lead to subtle issues in practice . Finally, the single-threaded and dynamically typed nature of this language makes Python code significantly less efficient than most of its modern competitors.
JVM is one of the fastest runtime platforms, making Java nearly as efficient as C. Most benchmarks show that Python code is 10 to 100 times slower than Java code. One big research paper compared the performance of multiple languages and showed that Python code is 74x more CPU-expensive than code in C, where Java code is only 1.8x more expensive. However, due to its long-standing commitment to backward compatibility, Java can feel verbose for certain tasks. Kotlin, building on that same ecosystem and offering the same efficiency, gives you access to a powerful typesystem, with modern language features focused on performance and developer ergonomics.
Those are the key reasons we can hear from companies or teams that decide to switch from Python to Kotlin. The Kotlin YouTube channel recently published Wolt’s success story, but that is only one voice among many. Kotlin is an all-around sensible choice for a range of projects, as it shares many similarities with Python. At the same time, Kotlin offers better performance, safety, and a much more powerful concurrency model. Let’s see those similarities and differences in practice.
Similarities between Python and Kotlin
When teaching Kotlin to both Python and Java developers, I was often surprised to discover that many Kotlin features are more frequently reported as intuitive by Python developers than their Java counterparts. Both languages offer concise syntax. Let’s compare some very simple use cases in both languages:
val language = "Kotlin"
println("Hello from $language")
// prints "Hello from Kotlin"
val list = listOf(1, 2, 3, 4, 5)
for (item in list) {
println(item)
}
// prints 1 2 3 4 5 each in a new line
fun greet(name: String = "Guest") {
println("Hello, $name!")
}
greet() // prints "Hello, Guest!"
language = "Python"
print(f"Hello from {language}")
# prints "Hello from Python"
list = [1, 2, 3, 4, 5]
for item in list:
print(item)
# prints 1 2 3 4 5 each in a new line
def greet(name="Guest"):
print(f"Hello, {name}!")
greet() # prints "Hello, Guest!"
At first glance, there are only minor syntactic differences. Kotlin presents features well-known to Python developers, like string interpolation, concise loops, and default parameters. However, even in this simple example, we can see some advantages that Kotlin has over Python. All properties are statistically typed, so language is of type String, and list is of type List<Int>. That not only allows for low-level optimizations, but it also brings enhanced safety and better IDE support. All variables in the code above are also defined as immutable, so we cannot accidentally change their values. To change them, we would need to use var instead of val. The same goes for the list I used in this snippet – it is immutable, so we cannot accidentally change its content. To create a mutable list, we would need to use mutableListOf and type it as MutableList<Int>. This strong distinction between mutable and immutable types is a great way to avoid accidental changes, which are often the source of bugs in Python programs.
There are other advantages of Kotlin over Python that are similarly apparent in the above example. Python’s default arguments are static, so changing them influences all future calls. This is a well-known source of very sneaky bugs in Python programs. Kotlin’s default arguments are evaluated at each call, so they are safer.
Kotlin
fun test(list: MutableList<Int> = mutableListOf()) {
list.add(1)
println(list)
}
test() // prints [1]
test() // prints [1]
test() // prints [1]
Python
def test(list=[]): list.append(1) print(list) test() # prints [1] test() # prints [1, 1] test() # prints [1, 1, 1]
Let’s talk about classes. Both languages support classes, inheritance, and interfaces. To compare them, let’s look at a simple data class in both languages:
Kotlin
data class Post( val id: Int, val content: String, val publicationDate: LocalDate, val author: String? = null ) val post = Post(1, "Hello, Kotlin!", LocalDate.of(2024, 6, 1)) println(post) // prints Post(id=1, content=Hello, Kotlin!, publicationDate=2024-06-01, author=null)
Python
@dataclass
class Post:
id: int
content: str
publication_date: date
author: Optional[str] = None
post = Post(1, "Hello, Python!", datetime.date(2024, 6, 1))
print(post) # prints Post(id=1, content='Hello, Python!', publication_date=datetime.date(2024, 6, 1), author=null)
Kotlin has built-in support for data classes, which automatically allows such objects to be compared by value, destructured, and copied. Python requires an additional decorator to achieve similar functionality. This class is truly immutable in Kotlin, and thanks to static typing, it requires minimal memory. Outside of that, both implementations are very similar. Kotlin has built-in support for nullability, which in Python is expressed with the Optional type from the typing package.
Now, let’s define a repository interface and its implementation in both languages. In Kotlin, we can use Spring Data with coroutine support, while in Python, we can use SQLAlchemy with async support. Notice that in Kotlin, there are two kinds of properties: Those defined inside a bracket are constructor parameters, while those defined within braces are class properties. So in SqlitePostRepository, crud is expected to be passed in the constructor. The framework we use will provide an instance of PostCrudRepository, which is generated automatically by Spring Data.
Kotlin
interface PostRepository {
suspend fun getPost(id: Int): Post?
suspend fun getPosts(): List<Post>
suspend fun savePost(content: String, author: String): Post
}
@Service
class SqlitePostRepository(
private val crud: PostCrudRepository
) : PostRepository {
override suspend fun getPost(id: Int): Post? = crud.findById(id)
override suspend fun getPosts(): List<Post> = crud.findAll().toList()
override suspend fun savePost(content: String, author: String): Post =
crud.save(Post(content = content, author = author))
}
@Repository
interface PostCrudRepository : CoroutineCrudRepository<Post, Int>
@Entity
data class Post(
@Id @GeneratedValue val id: Int? = null,
val content: String,
val publicationDate: LocalDate = LocalDate.now(),
val author: String
)
Python
class PostRepository(ABC):
@abstractmethod
async def get_post(self, post_id: int) -> Optional[Post]:
pass
@abstractmethod
async def get_posts(self) -> List[Post]:
pass
@abstractmethod
async def save_post(self, content: str, author: str) -> Post:
pass
class SqlitePostRepository(PostRepository):
def __init__(self, session: AsyncSession):
self.session = session
async def get_post(self, post_id: int) -> Optional[Post]:
return await self.session.get(Post, post_id)
async def get_posts(self) -> List[Post]:
result = await self.session.execute(select(Post))
return result.scalars().all()
async def save_post(self, content: str, author: str) -> Post:
post = Post(content=content, author=author)
self.session.add(post)
await self.session.commit()
await self.session.refresh(post)
return post
class Post(Base):
__tablename__ = "posts"
id: Mapped[int] = Column(Integer, primary_key=True, index=True)
content: Mapped[str] = Column(String)
publication_date: Mapped[date] = Column(Date, default=date.today)
author: Mapped[str] = Column(String)
Those implementations are very similar in many ways, and the key differences between them result from choices made by the frameworks, not the languages themselves. Python, due to its dynamic nature, encourages the use of untyped objects or dictionaries; however, such practices are generally discouraged in modern times. Both languages provide numerous tools for libraries to design effective APIs. On the JVM, these languages often depend on annotation processing, whereas in Python, decorators are more common. Kotlin leverages a mature and well-developed Spring Boot ecosystem, but it also offers lightweight alternatives such as Ktor or Micronaut. Python has Flask and FastAPI as popular lightweight frameworks, and Django as a more heavyweight framework.
In a backend application, we also need to implement services, which are classes that implement business logic. They often do some collection or string processing. Kotlin provides a comprehensive standard library with numerous useful functions for processing collections and strings. All those functions are named and called in a very consistent way. In Python, we can make nearly all transformations available in Kotlin, but to do so, we need to use many different kinds of constructs. In the code below, I needed to use top-level functions, methods on lists, collection comprehensions, or even classes from the collections package. Those constructs are not very consistent, some of them are not very convenient, and are not easily discoverable. You can also see that complicated notation for defining lambda expressions in Python harms collection processing APIs. Collection and string processing in Kotlin is much more pleasant and productive.
Kotlin
class PostService(
private val repository: PostRepository
) {
suspend fun getPostsByAuthor(author: String): List<Post> =
repository.getPosts()
.filter { it.author == author }
.sortedByDescending { it.publicationDate }
suspend fun getAuthorsWithPostCount(): Map<String?, Int> =
repository.getPosts()
.groupingBy { it.author }
.eachCount()
suspend fun getAuthorsReport(): String =
getAuthorsWithPostCount()
.toList()
.sortedByDescending { (_, count) -> count }
.joinToString(separator = "n") { (author, count) ->
val author = author ?: "Unknown"
"$author: $count posts"
}
.let { "Authors Report:n$it" }
}
Python
class PostService:
def __init__(self, repository: "PostRepository") -> None:
self.repository = repository
async def get_posts_by_author(self, author: str) -> List[Post]:
posts = await self.repository.get_posts()
filtered = [post for post in posts if post.author == author]
sorted_posts = sorted(
filtered,
key=lambda p: p.publication_date,
reverse=True
)
return sorted_posts
async def get_authors_with_post_count(self) -> Dict[Optional[str], int]:
posts = await self.repository.get_posts()
counts = Counter(p.author for p in posts)
return dict(counts)
async def get_authors_report(self) -> str:
counts = await self.get_authors_with_post_count()
items = sorted(counts.items(), key=lambda kv: kv[1], reverse=True)
lines = [
f"{(author if author is not None else 'Unknown')}: {count} posts"
for author, count in items
]
return "Authors Report:n" + "n".join(lines)
Before we finish our comparison, let’s complete our example backend application by defining a controller that exposes our service through HTTP. Until now, I have used Spring Boot, which is the most popular framework for Kotlin backend development. This is how it can be used to define a controller:
Kotlin
@Controller
@RequestMapping("/posts")
class PostController(
private val service: PostService
) {
@GetMapping("/{id}")
suspend fun getPost(@PathVariable id: Int): ResponseEntity<Post> {
val post = service.getPost(id)
return if (post != null) {
ResponseEntity.ok(post)
} else {
ResponseEntity.notFound().build()
}
}
@GetMapping
suspend fun getPostsByAuthor(@RequestParam author: String): List<Post> =
service.getPostsByAuthor(author)
@GetMapping("/authors/report")
suspend fun getAuthorsReport(): String =
service.getAuthorsReport()
}
However, we noticed that many Python developers prefer a lighter and simpler framework, and their preferred choice for such functionality is Ktor. Ktor allows users to define a working application in just a couple of lines of code. This is a complete Ktor Server application that implements a simple in-memory text storage (it requires no other configuration or dependencies except Ktor itself):
Kotlin
fun main() = embeddedServer(Netty, port = 8080) {
routing {
var value = ""
get("/text") {
call.respondText(value)
}
post("/text") {
value = call.receiveText()
call.respond(HttpStatusCode.OK)
}
}
}.start(wait = true)
I hope that this comparison helped you see both the key similarities and differences between Python and Kotlin. As we’ve seen, Kotlin has many features that are very intuitive for Python developers. At the same time, Kotlin offers many improvements over Python, especially in terms of safety. It has a powerful static type system that prevents many common bugs, built-in support for immutability, and a very rich and consistent standard library.
To summarize, I believe it’s fair to say that both languages are very similar in many ways, but Kotlin brings a number of improvements – some small, some big. In addition, Kotlin offers some unique features that are not present in Python, the biggest one probably being a concurrency model based on coroutines.
kotlinx.coroutines vs. Python asyncio
The most modern approach to concurrency in Kotlin and Python is based on coroutines. In Python, the most popular library for this purpose is asyncio, while in Kotlin, there is the Kotlin kotlinx.coroutines library. Both libraries can start lightweight asynchronous tasks and await their completion. However, there are some important differences between them.
Let’s start with the hallmark feature of kotlinx.coroutines: first-class support for structured concurrency. Let’s say that you implement a service like SkyScanner, which searches for the best flight offers. Now, let’s suppose a user makes a search, which results in a request or the opening of a WebSocket connection to our service. Our service needs to query multiple airlines to return the best offers. Let’s then suppose that this user left our page soon after searching. All those requests to airlines are now useless and likely very costly, because we have a limited number of ports available to make requests. However, implementing explicit cancellation of all those requests is very hard. Structured concurrency solves that problem. With kotlinx.coroutines, every coroutine started by a coroutine is its child, and when the parent coroutine is cancelled, all its children are cancelled too. This way, our cancellation is automatic and reliable.
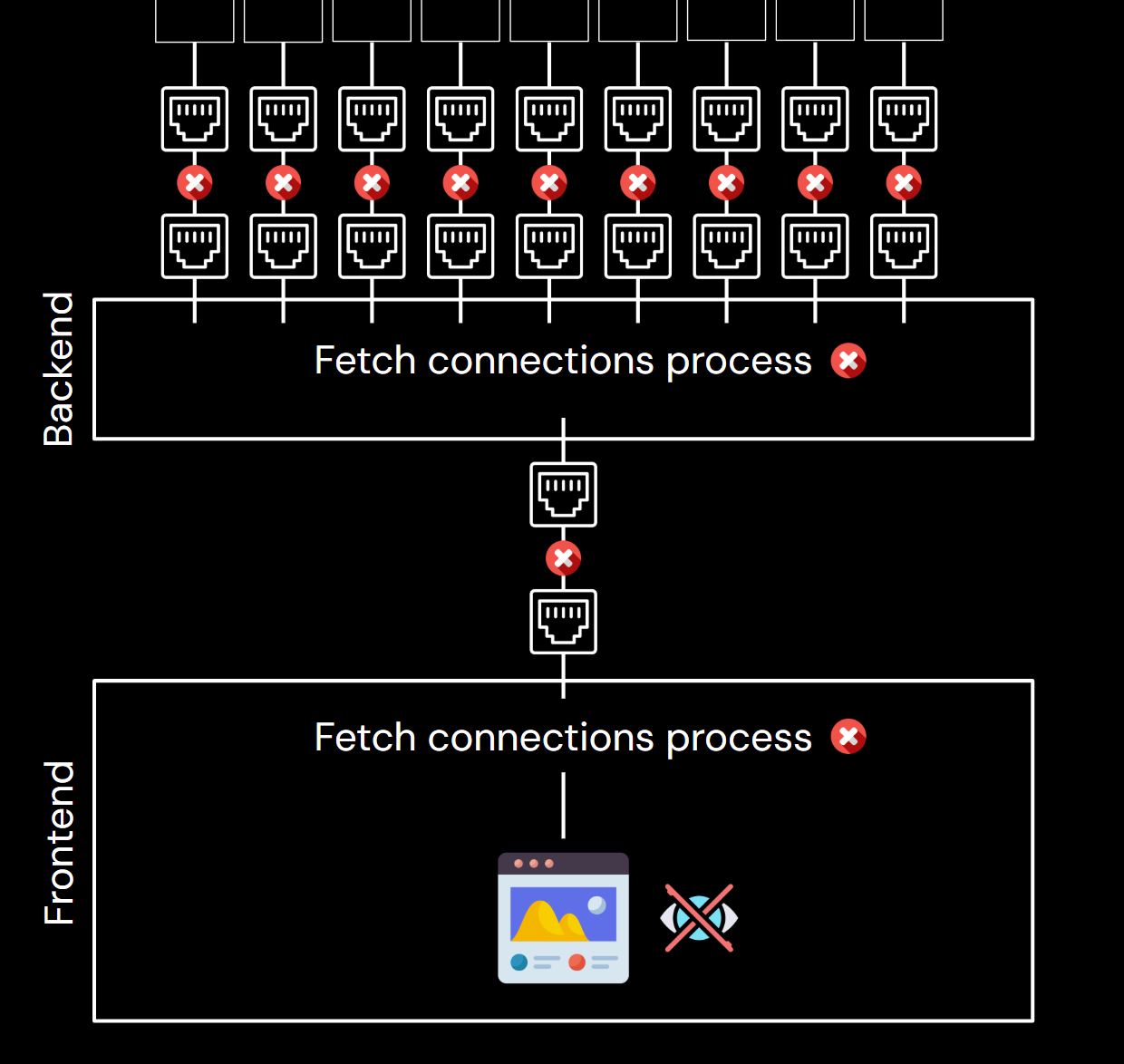
However, structured concurrency goes even further. If getting a resource requires loading two other resources asynchronously, an exception in one of those two resources will cancel the other one too. This way, kotlinx.coroutines ensures that we use our resources in the most efficient way. In Python, asyncio introduced TaskGroup in version 3.11, which offers some support for structured concurrency, but it is far from what kotlinx.coroutines offer, and it requires explicit usage.
Kotlin
suspend fun fetchUser(): UserData = coroutineScope {
// fetchUserDetails is cancelled if fetchPosts fails
val userDetails = async { api.fetchUserDetails() }
// fetchPosts is cancelled if fetchUserDetails fails
val posts = async { api.fetchPosts() }
UserData(userDetails.await(), posts.await())
}
The second important difference is thread management. In Python, asyncio runs all tasks on a single thread. Notice that this is not utilizing the power of multiple CPU cores, and it is not suitable for CPU-intensive tasks. Using kotlinx.coroutines, coroutines can typically run on a thread pool (by default as big as the number of CPU cores). This way, coroutines better utilize the power of modern hardware. Of course, coroutines can also run on a single thread if needed, which is quite common in client applications.
Another big advantage of coroutines is their testing capabilities. kotlinx.coroutines provides built-in support for testing asynchronous code over a predetermined simulated timeframe, removing the need to wait while the code is tested in real time. This way, we can test asynchronous code in a deterministic way, without any flakiness. We can also easily simulate all kinds of scenarios, like different delays from dependent services. In Python, testing asynchronous code is possible using third-party libraries, but this method is not as powerful and convenient as with coroutines.
Kotlin
@Test
fun `should fetch data asynchronously`() = runTest {
val api = mockk<Api> {
coEvery { fetchUserDetails() } coAnswers {
delay(1000)
UserDetails("John Doe")
}
coEvery { fetchPosts() } coAnswers {
delay(1000)
listOf(Post("Hello, world!"))
}
}
val useCase = FetchUserDataUseCase(api)
val userData = useCase.fetchUser()
assertEquals("John Doe", userData.user.name)
assertEquals("Hello, world!", userData.posts.single().title)
assertEquals(1000, currentTime)
}
Finally, kotlinx.coroutines offer powerful support for reactive streams through the Flow type. It is perfect for representing websockets or streams of events. Flow processing can be easily transformed using operators consistent with collection processing. It also supports backpressure, which is essential for building robust systems. Python has async generators, which can be used to represent streams of data, but they are not as powerful and convenient as Flow.
Kotlin
fun notificationStatusFlow(): Flow<NotificationStatus> =
notificationProvider.observeNotificationUpdate()
.distinctUntilChanged()
.scan(NotificationStatus()) { status, update ->
status.applyNotification(update)
}
.combine(
userStateProvider.userStateFlow()
) { status, user ->
statusFactory.produce(status, user)
}
Performance comparison
One of the key benefits of switching from Python to Kotlin is performance. Python applications can be fast when they use optimized native libraries, but Python itself is not the fastest language. As a statically typed language, Kotlin can be compiled to optimized bytecode that runs on the JVM platform, which is a highly optimized runtime. In consequence, Kotlin applications are typically faster than Python applications.
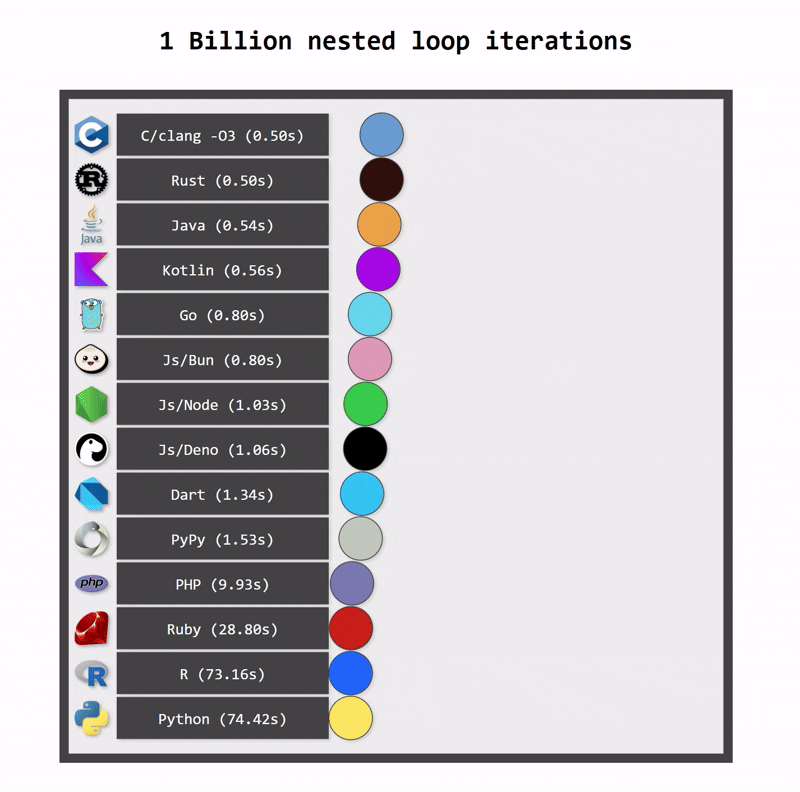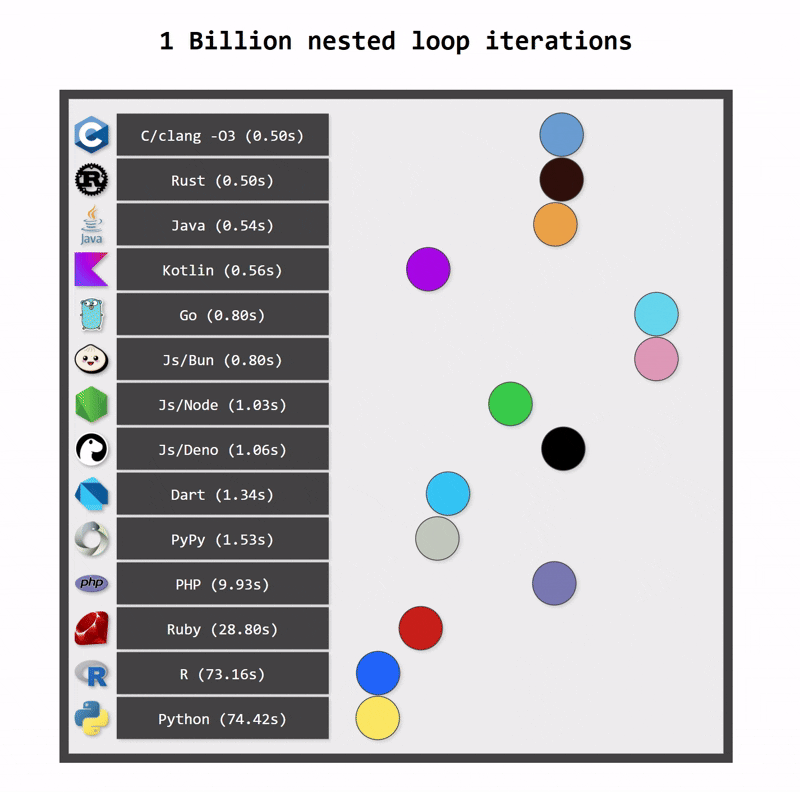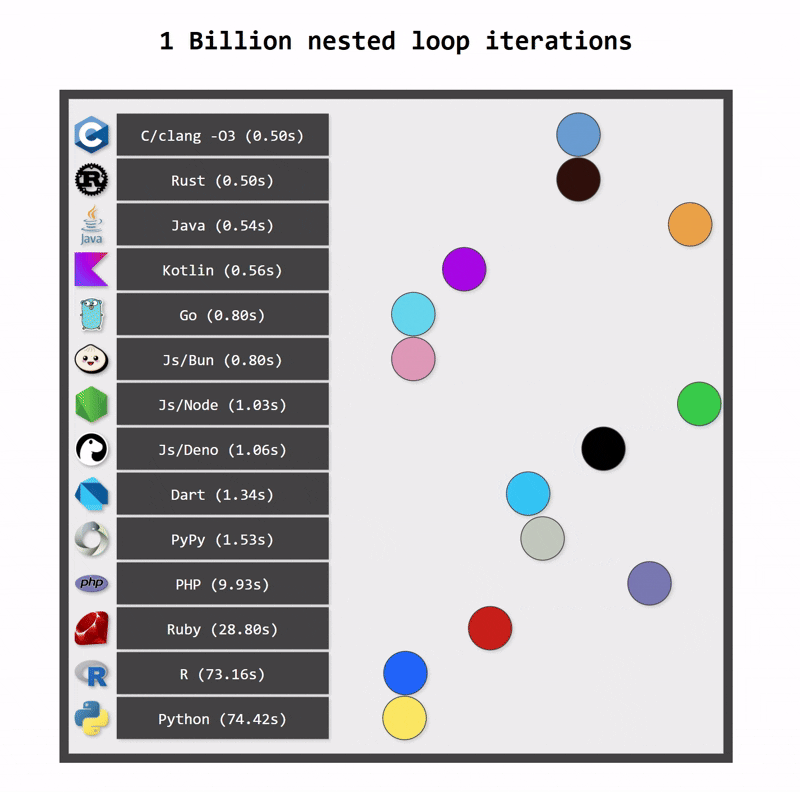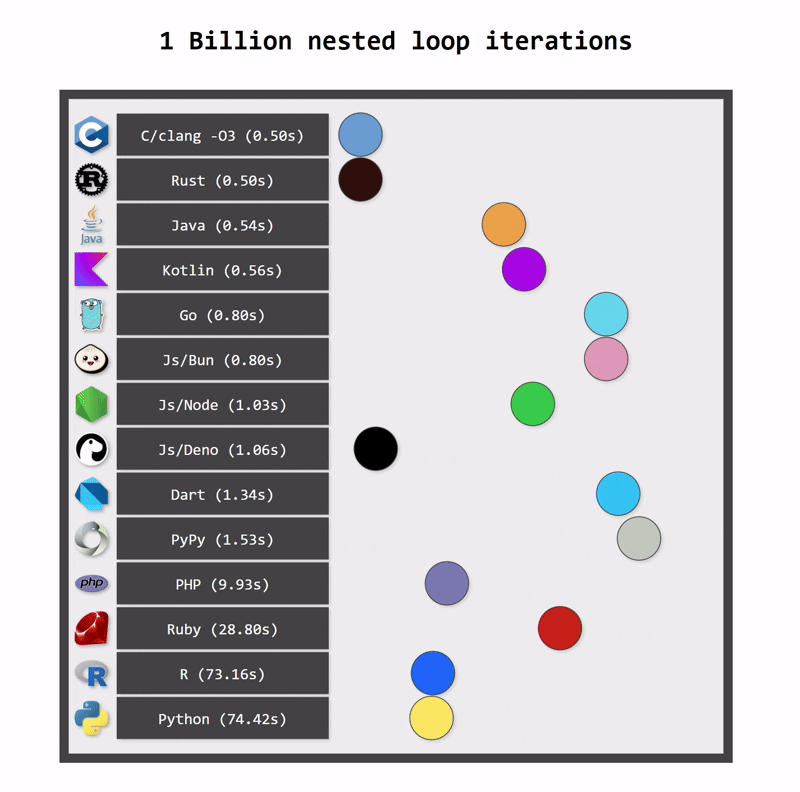
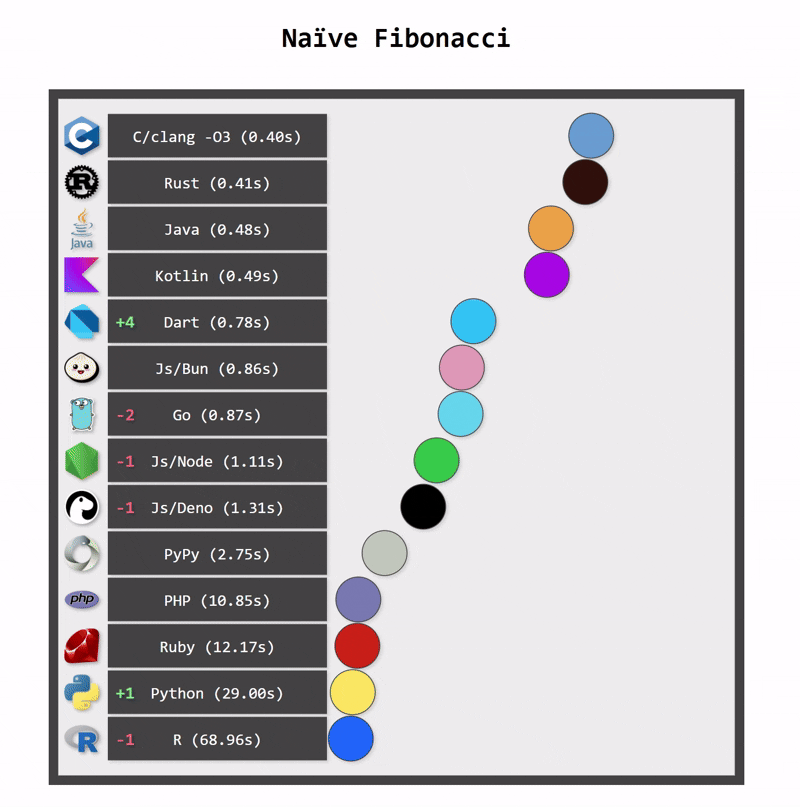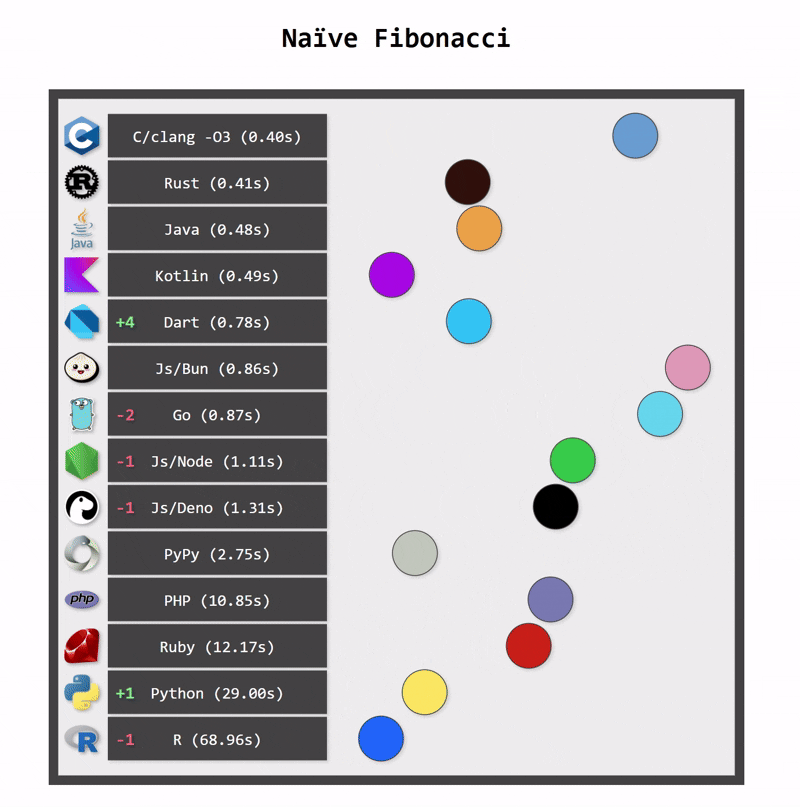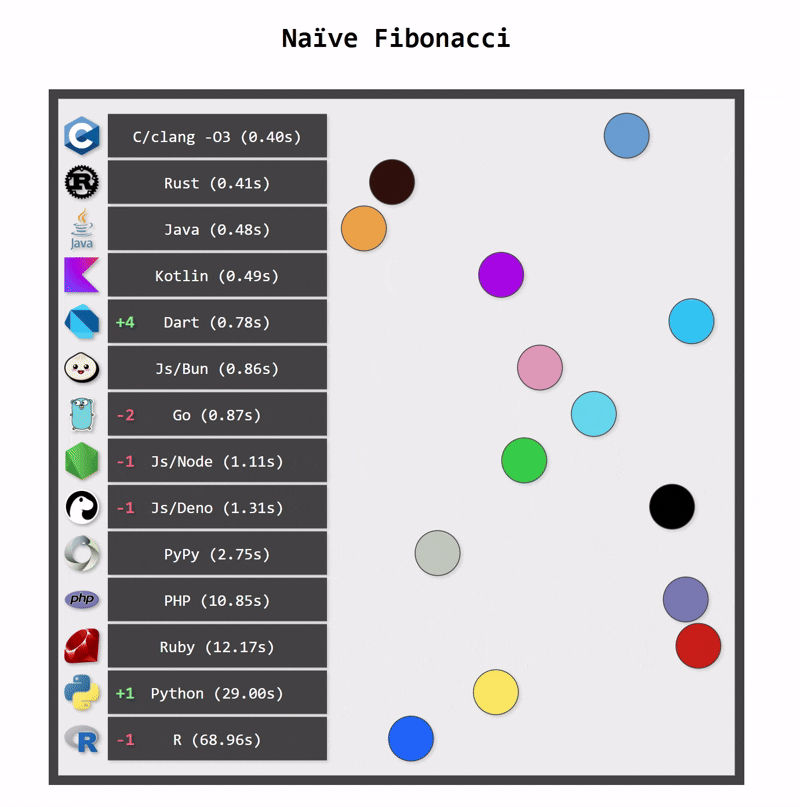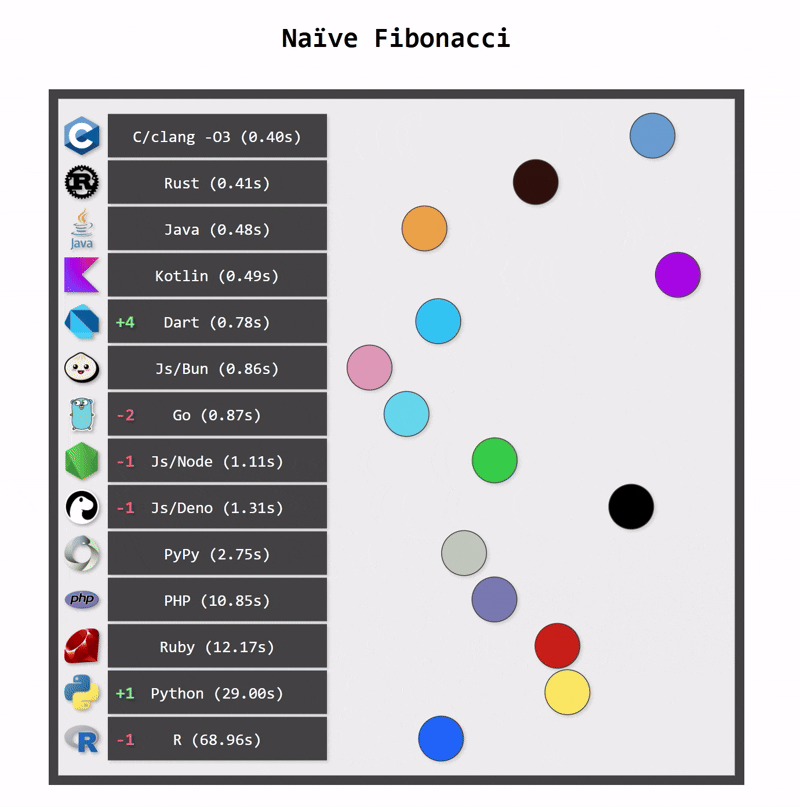
Kotlin applications also use fewer resources. One reason for this is Kotlin’s more efficient memory management (a consequence of static typing). Another reason is structured concurrency, which ensures that resources are cancelled when they are no longer needed.
Interoperability
Kotlin is fully interoperable with Java. This means that Kotlin applications can use everything from the rich Java ecosystem. Everything that can be used in Java can easily be used in Kotlin as well (see interoperability guide).
It is also possible to bridge between Kotlin and Python using libraries like JPype or Py4J. Nowadays, some libraries support further interoperability, like zodable, which allows generating Zod schemas from Kotlin data classes.
Summary
I love Kotlin and I love Python. I’ve used both languages extensively throughout my career. In the past, Python had many clear advantages over Kotlin, such as a richer ecosystem, more libraries, and scripting capabilities. In some domains, like artificial intelligence, I still find Python to be a better choice. However, for backend development, Kotlin is clearly the better option today. It offers similar conciseness and ease of use as Python, but it is faster, safer, and scales better. If you consider switching from Python to Kotlin for your backend development, it is a transition worth making.
Pennsylvania, USA

Developers, project managers and even executives use the term “technical debt” to explain delays, instability or rising maintenance costs. Its meaning is simple and relatable: We cut corners to deliver faster, take on “debt” and later repay it through bug fixes, refactoring or rewriting code.
Yet, there is another, far more dangerous type of debt: architecture debt. Unlike technical debt, architecture debt is not visible in a pull request. It doesn’t appear as a broken unit test or a security vulnerability in a code scanner. It grows silently when the overall structure of systems, integrations and processes is flawed. It’s systemic rather than local, and it often reveals itself only when a transformation program stalls, a cloud migration fails or an AI initiative cannot scale.
So why do companies so often confuse technical debt with architecture debt? And why does this confusion cost businesses millions?
The House vs. City Metaphor
Imagine a house. If a stair breaks, a pipe leaks or the electrical wiring fails, everyone notices right away. These are visible problems that demand immediate repair.
In IT terms, this is technical debt: a local issue in the codebase, test coverage or infrastructure. One team, or even one engineer, can usually address it. It may be painful, but it is tangible, diagnosable and often well understood.

Now imagine an entire city. Every house might be freshly painted, every apartment renovated, every room in perfect condition. Yet, if the city’s road network is poorly designed, if the water supply is fragmented or if zoning rules are inconsistent, the city will gradually descend into dysfunction. Traffic jams will paralyze movement, residents will waste hours commuting and emergency services won’t reach their destinations in time.
This is architecture debt. It doesn’t manifest as a single broken stair — it reveals itself in systemic failures caused by misalignment and lack of coordination across the whole environment.

The same principle applies to IT landscapes. A development team might deliver clean, modular code. CI/CD pipelines may run flawlessly, and tests all pass in green. Yet beneath this surface, the enterprise often runs multiple overlapping platforms with fragile, undocumented point-to-point integrations. Architectural principles exist on paper but are inconsistently enforced.
The result is predictable: Every new initiative, from digital transformation to AI adoption, encounters hidden friction and costly delays.
The metaphor matters because it highlights visibility versus invisibility. Technical debt is obvious — like a leaky roof you can’t ignore. Architecture debt is subtle — like poor city planning that only becomes undeniable when gridlock makes life unworkable. And while fixing a broken stair is straightforward, redesigning an entire transportation system takes years, coordination and investment.
Why Companies Confuse Technical and Architecture Debt
- The symptoms look deceptively similar. Both types of debt produce the same visible symptoms: delays, outages and higher costs. But the causes differ: Technical debt stems from code shortcuts, while architecture debt arises from systemic flaws such as platform duplication or broken data governance. Because the outcomes look alike, organizations often mislabel everything as “tech debt,” missing the deeper structural cause.
- The focus stays on fixing code. Executives often fall back on a default response: “If we just hire more developers, we’ll clear the backlog.” This works when the problem is technical debt — adding engineers can indeed accelerate refactoring or bug fixes. But architecture debt doesn’t yield to brute force. Ten extra developers cannot fix platform sprawl, reconcile fragmented data models or redesign an integration landscape. These are structural issues that require governance, architecture boards and cross-domain design, not simply more coding power.
- Architecture debt hides in plain sight. Technical debt has clear indicators: bug density, test coverage, code complexity scores. These appear naturally in developer dashboards and project reports. Architecture debt, however, rarely shows up in Jira tickets or automated scans. Few organizations track duplicate platforms, undocumented interfaces or integration complexity. Without such metrics, architecture debt remains invisible until a major transformation grinds to a halt.
- Organizational silos reinforce the confusion. Most teams optimize for their own scope. A development squad ensures its microservice runs smoothly. A project manager hits local milestones. A vendor delivers a contract. But no one owns the end-to-end structure — the city rather than the house. Architecture decisions become scattered: One domain picks a new Software as a Service tool, another adopts its own data model, a third chooses a different cloud provider. Over time, these siloed decisions accumulate into architecture debt that no single team recognizes until it is too late.
- Language itself blurs the lines. “Tech debt” has become a catch-all phrase in corporate vocabulary. Business stakeholders rarely distinguish between fixing a brittle function and untangling a decade of integration spaghetti. The term’s popularity masks important differences: One is tactical and correctable, the other is strategic and deeply structural. By calling everything “technical debt,” companies miss the chance to create practices, funding models and remediation plans specifically designed for architecture debt.
Diagnosing Architecture Debt
For specialists, the key is to make the invisible visible. Techniques include the following.
- Duplicate platforms: Count how many systems perform overlapping functions (five human resources systems, three customer-relationship management tools). High duplication signals structural inefficiency.
- Integration complexity: Measure the number of point-to-point connections versus API gateways, enterprise service buses (ESBs) or event-driven models.
- Principle violations: Track how many systems lack defined owners, documented interfaces or compliance with enterprise standards.
- Latency chains: Calculate end-to-end data flow time across multiple hops. If data must pass through six legacy systems before reaching an AI model, architecture debt is the bottleneck.
- Configuration management database (CMDB) completeness: Use ServiceNow or a similar tool to measure the percentage of applications with filled ownership, life cycle and dependency fields.
These metrics help shift architecture debt from abstract concept to quantifiable problem.
Real-World Cases
AI adoption blocked by data silos
A company builds advanced machine learning (ML) models to forecast demand. The data scientists are skilled, the models promising. But data resides in five separate legacy systems with no unified schema. Integration projects drag on for months. The result: The AI program stalls, not because of poor algorithms, but because of architecture debt in data pipelines.
Cloud migration and the immovable legacy
During a cloud migration, 30% of applications can’t move. They depend on outdated middleware, proprietary protocols or undocumented dependencies. The migration slows, and costs skyrocket. The issue is architecture debt in integration and platform dependencies, not technical debt in the code.
Resilience gaps in infrastructure
An enterprise invests heavily in monitoring and incident response. Still, outages persist. The real culprit: an outdated network architecture designed for 2005 traffic patterns, not modern workloads. This is architecture debt in infrastructure design, invisible to dashboards focused only on uptime.
The Consequences of Ignoring Architecture Debt
- Financial waste: Garner and McKinsey studies show that up to 40% of digital transformation budgets are consumed by untangling hidden architectural problems. Because these costs rarely appear in business cases, programs that start with a $50 million budget can balloon to $70 million to $80 million once hidden dependencies surface.
- Program delays: Architectural weaknesses extend timelines dramatically. A 12-month program often drifts into 24 to 36 months once hidden silos or outdated middleware emerge, and many deliver only a fraction of their intended value because resources are consumed by firefighting. For specialists, unresolved architecture debt is the single biggest threat to predictable delivery — more damaging than resourcing gaps or shifting requirements.
- Technological stagnation: Architecture debt locks companies into the past. AI, automation and cloud adoption initiatives don’t fail because teams lack skill. They fail because underlying systems are fragmented, unscalable or incompatible. In fact, 70% to 80% of AI projects fail to scale beyond pilot. Without a unified data platform, AI models never leave the lab. Without rationalized applications, automation pilots don’t scale. Without decoupled integration, cloud migrations stall. The result: Organizations spend years talking about innovation while still running critical processes on legacy mainframes or fragile middleware.
- Increased risk exposure: Old integrations and outdated platforms are not just inefficient — they are dangerous. Legacy systems were a contributing factor in over 60% of major cyber incidents. Architecture debt creates hidden single points of failure, undocumented dependencies and weak security perimeters. A minor outage in one system can cascade into a businesswide incident. Similarly, fragmented landscapes increase the attack surface for cyber threats, while lack of resilience planning undermines business continuity. For highly regulated industries, this also translates into compliance risk: Auditors increasingly expect evidence that architectural controls are in place, not just operational ones.
- Erosion of trust (new, expanded consequence): Perhaps the most subtle consequence is the erosion of trust between IT and the business. When every initiative runs over budget, misses deadlines or delivers less than promised, stakeholders lose faith in IT’s ability to execute. This reputational damage is difficult to repair and often leads to shadow IT — business units bypassing enterprise processes altogether. Ironically, this only accelerates the accumulation of new architecture debt.
![]()
What Can Be Done: 5 Steps
- Officially define architecture debt. Organizations must recognize architecture debt as a category distinct from technical debt. This requires clear definitions and communication to both technical and business leaders.
- Build metrics and dashboards. Track the following:
- The percentage of systems without owners.
- Point-to-point integrations.
- CMDB completeness and accuracy.
- The percentage of platforms aligned with architectural principles.
- Practice architecture observability. Just as site reliability engineers monitor service reliability, architects must monitor the structural health of the IT landscape: scalability, modularity, principle adherence.
- Run architecture reviews. Beyond code reviews, organizations should hold systematic architecture reviews for projects and domains.
- Manage debt as a portfolio. Not all debt needs immediate repayment. Like managing a financial portfolio, organizations should prioritize by business impact — addressing the costliest blockers first while consciously tolerating manageable inefficiencies.
Expanded Specialist Insights
- Integration patterns matter. The choice of integration architecture is often the difference between manageable complexity and long-term paralysis. Point-to-point integrations may work in the short term, but they scale poorly. Every new system exponentially increases dependencies. By contrast, API-first strategies and event-driven architectures decouple services, reduce systemic coupling and improve resilience. For specialists, this isn’t just a design preference, it’s a debt-management strategy. Shifting from legacy ESB spaghetti to asynchronous event hubs or API gateways can lower failure domains, speed up onboarding of new services and cut integration costs by double digits.
- Governance is architecture in action. Architecture isn’t just diagrams; it’s the operational discipline of enforcing standards. Without governance boards, review gates and principal compliance checks, architecture debt grows faster than it can be repaid. Effective governance creates a feedback loop: Each project is reviewed not just for delivery but for alignment with long-term enterprise principles. Specialists know that without governance, every “local optimization” becomes tomorrow’s systemic problem. For example, allowing teams to adopt overlapping SaaS tools without architectural oversight results in fragmented landscapes that later block consolidation and automation.
- Link debt to business KPIs. Architecture debt becomes meaningful to executives only when it connects to business outcomes. Instead of abstract warnings, architects should show how debt directly slows time to market, increases operating cost per transaction or reduces system resilience during incidents. For example, duplicating finance platforms may not look critical until leaders see the effect: increased reconciliation time, higher audit risks and slower financial close — a challenge reported by 42% of CFOs in Deloitte’s 2023 Finance Transformation Survey. By translating architectural debt into the same KPIs tracked at the board level, specialists ensure visibility and funding for remediation.

- Architecture debt and AI. The rise of AI amplifies the risks of architecture debt. AI models thrive on clean, accessible and governed data, yet architecture debt often means data silos, inconsistent schemas and poor lineage tracking. Even world-class models will fail to scale if pipelines are fragmented or unobservable. For specialists, this means architecture is no longer just an IT foundation, it is a direct enabler of AI success. A single broken data lineage can undermine model explainability, making regulatory compliance impossible. Conversely, organizations that actively reduce architecture debt in their data ecosystems gain a competitive edge: Their AI initiatives reach production faster and deliver measurable business outcomes.
- Think of observability beyond code. Most observability practices today focus on applications and infrastructure — uptime, latency, error rates. But architecture debt requires a new dimension of observability: structural monitoring. This means tracking system dependencies, integration bottlenecks and principal compliance in near-real time. For example, dashboards that show the percentage of undocumented APIs or latency across data pipelines allow architects to detect architecture debt before it cripples delivery. Just as site reliability engineers measure reliability, architects must measure structural health.
- Adopt portfolio thinking for debt remediation. Not all debt can or should be repaid immediately. Treating debt as a portfolio creates discipline: Some items are high-interest and must be resolved quickly (such as undocumented critical integrations), while others can be tolerated if managed (two overlapping SaaS tools in low-risk domains). Using risk-adjusted prioritization allows architects to align remediation with business value, rather than chasing every inefficiency. This approach also helps secure executive funding by linking remediation plans to measurable return on investment.
Conclusion
Technical debt is visible. Everyone can point to buggy code, missing tests or a legacy function that needs rewriting. Architecture debt is hidden, and that makes it far more dangerous. It accumulates quietly in duplicated platforms, fragile integrations and outdated governance models. And while technical debt slows delivery, architecture debt stalls entire transformations.
Looking ahead, organizations that fail to address architecture debt will struggle to adopt AI at scale, modernize for cloud or meet rising cybersecurity and compliance demands. The winners will be those that treat architecture debt as a board-level risk and invest in continuous architecture observability, governance and remediation.
For specialists, the message is clear: Stop treating “tech debt” as a catch-all phrase. Build the practices, metrics and governance to make architecture debt visible and actionable.
In the era of AI and data-driven enterprises, reducing architecture debt will no longer be a technical choice. It will be a strategic differentiator that separates the companies that can transform from those that will fall behind.
The post Technical Debt vs. Architecture Debt: Don’t Confuse Them appeared first on The New Stack.
Pennsylvania, USA
The open source Redis fork is slowly getting support across Microsoft’s various platforms.
Pennsylvania, USA
Next Page of Stories