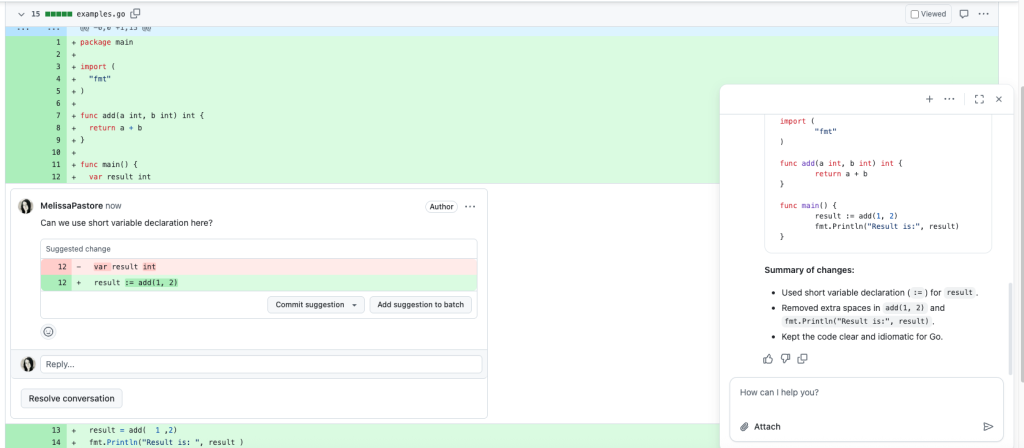
In part 5 of this mini-series, we bring together all main components to form the end-to-end solution for the AI home security system.
We also refine and refactor some of the original Python code.
To recap, this home security system uses motion detection, image capture, and AI-powered person recognition to distinguish between known persons (family, friends) and potential intruders.
It sends alerts when unknown persons are detected.
~
System Components
It’s worth a recap of the hardware and software components that form the solution.
Hardware
The hardware consists of:
- Raspberry Pi 4
- Camera module
- PIR motion sensor connected to GPIO
- Bluetooth speaker for local alerts
An old laptop is also used to host a .NET API.
Software

Some of the files have been renamed to ease readability, the following software components are used in the solution:
- audioplayer.py – audio alert functions
- botmessage.py – Telegram messaging functions
- ClipServer.py – Python server running CLIP model for generating image
- ImageTrainingAndClassification.py – Telegram bot for training person recognition
- MotionDetectionCapture.py – Main motion detection and capture script
- .NET API – Image recognition service with /train and /match endpoints
- Telegram Bot – For receiving security alerts and training the system
Access to MotionDetectionCapture.py and ImageTrainingAndClassification.py scripts and CLIP server is controller from a .NET API.
You can find more information about the above in the earlier blog posts from the series:
Spoiler alert – in part 6 of this series, we will introduce Semantic Kernel.
~
Core Logic Flow
Our refined process flow detailed the following sequence diagram.
Further information from each of the numbers sub processes are also included:

1. Motion Detection & Capture
This sub process is the starting point. The PIR detects changes in radiation and camera activates when this happens. A photo is taken and saved in real-time.
The photo is timestamped and saved to the following location:
/home/admin/repos/HomeSecuritySystem/images/img_YYYYMMDD-HHMMSS.jpg
2. AI Recognition Check
With the image captured, it can be sent to the .NET API /match endpoint.
The steps are as follows:
- .NET API forwards image to CLIP_Server.py running on the Raspberry Pi.
- The CLIP Server generates image embedding/vector using CLIP model.
- .NET API compares new vector against stored trained embeddings.
- The .NET API returns 1 of 2 responses:
-
- MATCH: [PersonName] (Similarity: X.XX)
- NO MATCH FOUND
The system must send alerts if it does not recognisee the person. We have some separate logic for that too.
3. Alert Decision Logic
We don’t always want to be alerted for every image that is captured so must have logic to decide when to send and alert and when to ignore the image.
We build on the .NET API output from the previous step.
The logic is as follows:
3.1 MATCH FOUND (Known Person)
In this branch of logic, a known person is detected and therefore is not a security concern. Main steps are:
- Person is recognized from training data
- No alert sent (silent operation)
3.2 NO MATCH FOUND (Unknown Person)
In this branch of logic, an unknown person was detected which is a security risk. Immediate notification needed!
- Person not recognized = potential intruder
- Play audio alert locally
- Send Telegram message with image and “Intruder alert!” caption
That covers the core logic that forms the basis of the home security system. Next, we can summarise how we can train the system.
~
.NET API Integration
I’m not a Python developer. So, I created a simple .NET API to act as a single-entry point and common surface area to the various Python scripts that are used. The following endpoints are available:
- POST /api/image/train – Train new person with label
- POST /api/image/match – Check if person matches trained data
.NET API Training Flow (/train)
This sequence diagram shows how the home security system handles the training of individuals to be recognised.
It outlines the flow of information between various component from collecting and sending images to processing and storing identity data:

The steps are as follows:
- Send /train [PersonName] command to Telegram bot
- Send photo(s) of the person to train
- .NET API receives image and forwards to CLIP_Server.py
- CLIP Server generates embedding vector for the person’s image
- .NET API stores the embedding with the person’s label
- Future detections of this person will be recognized by comparing vectors
.NET API Person Matching Flow (/match)
The following sequence diagram details the process for performing matching of a newly captured image by the camera / PIR sensor against the systems known training data / persons.
Image verification capabilities are performed in a series of steps using multiple components that include: the Telegram bot, Python script, .NET APU and CLIP model server.

The steps are as follows:
- Send /match command to Telegram bot
- Send a photo to test recognition
- Image is processed through CLIP Server to generate test embedding
- .NET API compares test embedding against all stored embeddings
- Bot responds with match result and similarity score
~
CLIP Server Integration
To generate embeddings, OpenAI’s CLIP (Contrastive Language–Image Pre-training) model is used.
CLIP (Contrastive Language-Image Pre-training) is an AI model developed by OpenAI that understands images and text. CLIP makes it easy for you to encode images into high-dimensional vectors (embeddings).
The .NET API communicates with a Python CLIP server (CLIP_Server.py) to generate image embeddings.
In this system, we use CLIP’s image encoding capabilities to generate numerical representations (embeddings) of people for recognition.
Learn more about CLIP and CLIP_Server.py in part 2 of this series but in essence, here is how it works:
- Input: Raw image file is sent.
- Processing: CLIP model converts image to 512-dimensional vector
- Output: Numerical embedding that uniquely represents the person’s face
- Comparison: Uses cosine similarity to compare embeddings (values from -1 to 1, where 1 = identical)
Sequence diagrams follow and provide low level detail on how these steps are used during the training and matching flows when CLIP is used.
CLIP Training Flow
In this flow, we are using CLIP via CLIP_Server.py to generate embeddings for a person the want to recognise (and subsequently, not send security alerts):

- NET API receives image from Telegram bot
- .NET API calls CLIP_Server.py with image
- CLIP Server uses CLIP model to generate 512-dimensional embedding vector
- .NET API stores embedding with person label for future comparisons
CLIP Matching Flow
In this flow, we see how we are using CLIP via the CLIP_Server.py to generate embeddings for a newly taken photo by the camera/PIR sensor:

- .NET API receives image from motion detection system
- .NET API calls
CLIP_Server.py to generate embedding for new image
- .NET API compares new embedding against all stored embeddings using cosine similarity
- Returns best match if similarity exceeds threshold, otherwise “NO MATCH FOUND”
~
What We Have Built
We’ve reached the end of this summary. At this point, we’ve created an end-to-end AI home security system.
Security benefits of this system include:
- No false alarms from family members and regular visitors
- Immediate alerts for genuine security concerns
- Learning – gets smarter as you train more people
- Visual confirmation – image sent with every alert
- Automated operation – no manual intervention needed
No subscription required and can be run totally on local hardware and software. The only external dependency is on Telegram.
Setup Phase
Main steps involved to start the system are:
- Install and configure hardware (Raspberry Pi, camera, PIR sensor)
- Start CLIP_Server.py to enable AI image processing (Pi)
- Start .NET API service for handling recognition and training requests (Laptop)
- Train the system with photos of all authorized persons (via phone or Postman)
- Test the system with known and unknown faces
- Start motion detection script for continuous monitoring (Pi)
One thing to note is the .NET API stores embeddings in memory, if you stop the API, you need to retrain the system with known persons. Not ideal but easily remedied.
Daily Operation
When running the system will:
- Continuously monitors for motion
- Capture and analyse any detected movement
- Silently allows known persons to pass
- Immediately alerts on unknown persons
Perfect.
~
Technical Notes
Finally, some technical notes related to low-level implementation details. Some of these tweaks helped improve the performance of the system.
- Motion Detection Cooldown: 3-second delay between captures to avoid multiple alerts for same event
- Image Format: JPEG with timestamp naming convention
- API Communication: Asynchronous HTTP requests using aiohttp
- Vector Generation: CLIP model creates 512-dimensional embeddings for face recognition
- Similarity Threshold: Configurable threshold for determining matches (typically 0.7-0.9)
- Error Handling: API failures are logged, system continues monitoring
- GPIO Cleanup: Proper cleanup on system shutdown
You might add your own.
~
Summary
That’s a wrap. In final part of this series, we will introduce Semantic Kernel. This will let us use natural language to reason over and interact with the AI home security system. Stay tuned.
~