Go, the ancient board game that China, Japan and South Korea all claim as part of their cultural heritage, is struggling to expand its global footprint because the three nations that dominate it cannot agree on something as basic as a common rulebook.
When Go was registered with the International Mind Sports Association alongside chess and bridge, organizers had to adopt the American Go Association's rules because the East Asian trio failed to reach consensus. In 2025, China's Ke Jie withdrew from a title match at a Seoul tournament after receiving repeated penalties for violating a rule that the South Korean Go association had introduced mid-tournament. China's Go association responded by barring foreign players, most of them South Korean, from its domestic competitions.
It also doesn't help that the game's commercial appeal is fading. Japan's Nihon Ki-in, the country's main Go association, has started exploring a potential sale of its Tokyo headquarters. Young people across the region are gravitating toward chess, shogi, and video games instead.
Microsoft’s headquarters in Redmond, Washington. | Image: Getty Images
Microsoft's library of books is so heavy that it once caused a campus building to sink, according to an unproven legend among employees. Now those physical books, journals, and reports, and many of Microsoft's digital subscriptions to leading US newspapers, are disappearing in a shift described inside Microsoft as an "AI-powered learning experience."
Microsoft started cutting back on its employee subscriptions to news and reports services in November, with some publishers receiving an automated email cancellation of a contract. "This correspondence serves as official notification that Microsoft will not renew any existing contracts upon the …
To keep a platform like GitHub available and responsive, it’s critical to build defense mechanisms. A whole lot of them. Rate limits, traffic controls, and protective measures spread across multiple layers of infrastructure. These all play a role in keeping the service healthy during abuse or attacks.
We recently ran into a challenge: Those same protections can quietly outlive their usefulness and start blocking legitimate users. This is especially true for protections added as emergency responses during incidents, when responding quickly means accepting broader controls that aren’t necessarily meant to be long-term. User feedback led us to clean up outdated mitigations and reinforced that observability is just as critical for defenses as it is for features.
We apologize for the disruption. We should have caught and removed these protections sooner. Here’s what happened.
What users reported
We saw reports on social media from people getting “too many requests” errors during normal, low-volume browsing, such as when following a GitHub link from another service or app, or just browsing around with no obvious pattern of abuse.
Users encountered a “Too many requests” error during normal browsing.
These were users making a handful of normal requests hitting rate limits that shouldn’t have applied to them.
What we found
Investigating these reports, we discovered the root cause: Protection rules added during past abuse incidents had been left in place. These rules were based on patterns that had been strongly associated with abusive traffic when they were created. The problem is that those same patterns were also matching some logged-out requests from legitimate clients.
These patterns are combinations of industry-standard fingerprinting techniques alongside platform-specific business logic — composite signals that help us distinguish legitimate usage from abuse. But, unfortunately, composite signals can occasionally produce false positives.
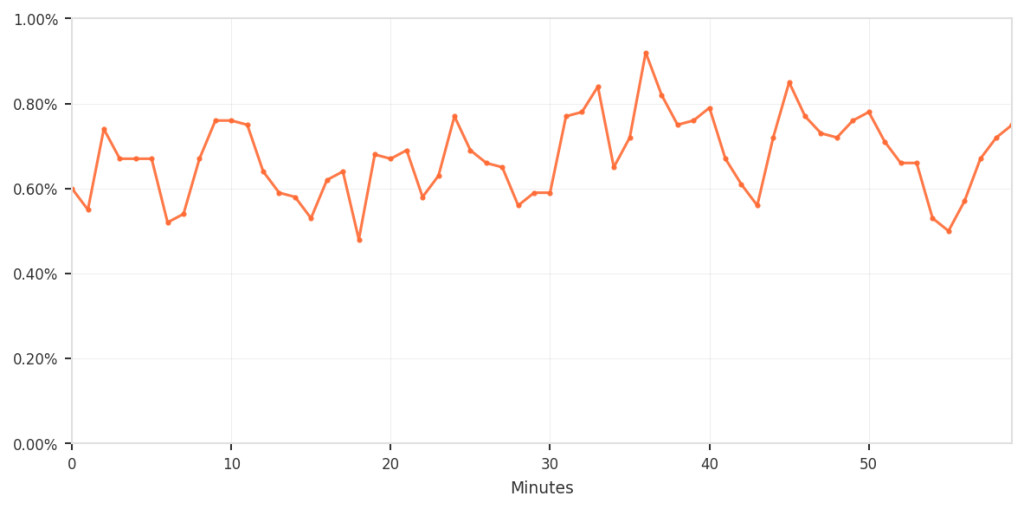
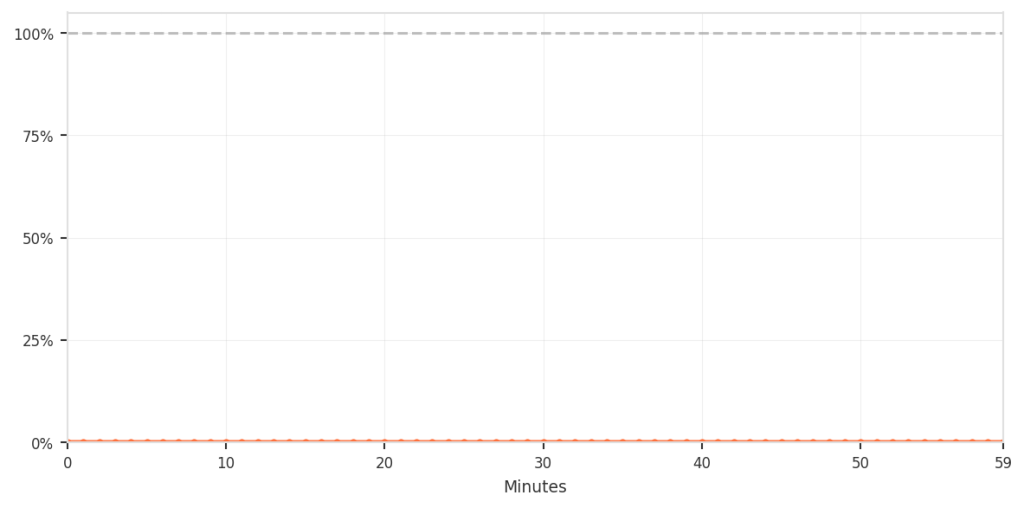
The composite approach did provide filtering. Among requests that matched the suspicious fingerprints, only about 0.5–0.9% were actually blocked; specifically, those that also triggered the business-logic rules. Requests that matched both criteria were blocked 100% of the time.
Not all fingerprint matches resulted in blocks — only those also matching business logic patterns.
The overall impact was small but consistent; however, for the customers who were affected, we recognize that any incorrect blocking is unacceptable and can be disruptive. To put all of this in perspective, the following shows the false-positive rate relative to total traffic.
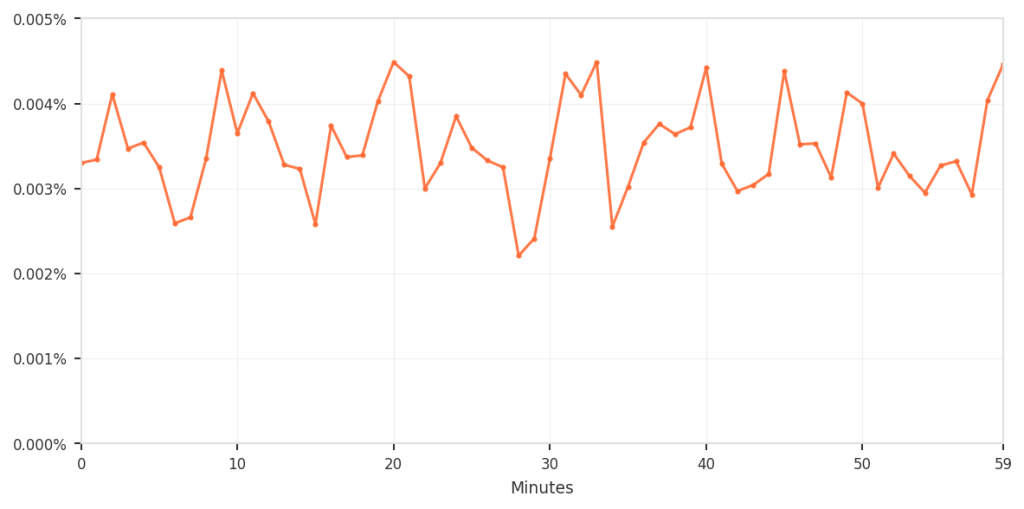
False positives represented roughly 0.003-0.004% of total traffic.
Although the percentage was low, it still meant that real users were incorrectly blocked during normal browsing, which is not acceptable. The chart below zooms in specifically on this false-positive pattern over time.
In the hour before cleanup, approximately 3-4 requests per 100,000 (0.003-0.004%) were incorrectly blocked.
This is a common challenge when defending platforms at scale. During active incidents, you need to respond quickly, and you accept some tradeoffs to keep the service available. The mitigations are correct and necessary at that moment. Those emergency controls don’t age well as threat patterns evolve and legitimate tools and usage change.
Without active maintenance, temporary mitigations become permanent, and their side effects compound quietly.
Tracing through the stack
The investigation itself highlighted why these issues can persist. When users reported errors, we traced requests across multiple layers of infrastructure to identify where the blocks occurred.
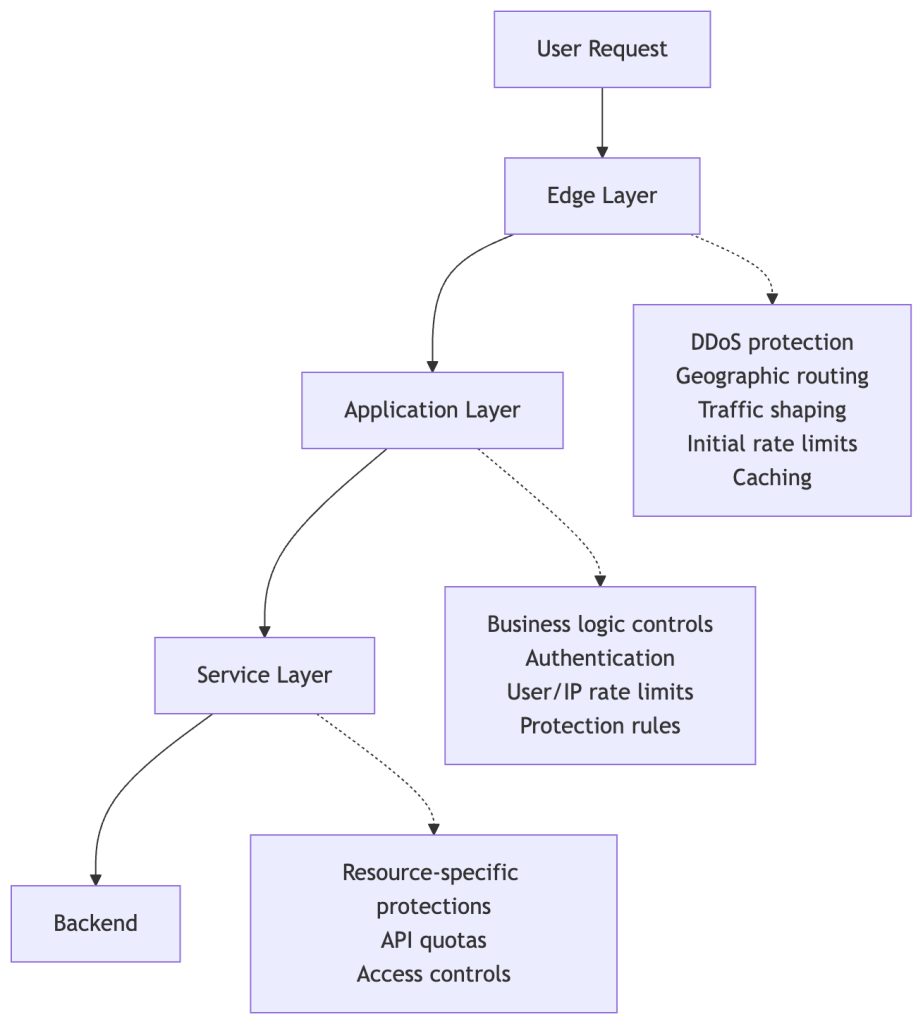
To understand why this tracing is necessary, it helps to see how protection mechanisms are applied throughout our infrastructure. We’ve built a custom, multi-layered protection infrastructure tailored to GitHub’s unique operational requirements and scale, building upon the flexibility and extensibility of open-source projects like HAProxy. Here’s a simplified view of how requests flow through these defense layers (simplified to avoid disclosing specific defense mechanisms and to keep the concepts broadly applicable):
Each layer has legitimate reasons to rate-limit or block requests. During an incident, a protection might be added at any of these layers depending on where the abuse is best mitigated and what controls are fastest to deploy.
The challenge: When a request gets blocked, tracing which layer made that decision requires correlating logs across multiple systems, each with different schemas.
In this case, we started with user reports and worked backward:
User reports provided timestamps and approximate behavior patterns.
Edge tier logs showed the requests reaching our infrastructure.
Application tier logs revealed 429 “Too Many Requests” responses.
Protection rule analysis ultimately identified which rules matched these requests.
The investigation took us from external reports to distributed logs to rule configurations, demonstrating that maintaining comprehensive visibility into what’s actually blocking requests and where is essential.
The lifecycle of incident mitigations
Here’s how these protections outlived their purpose:
Each mitigation was necessary when added. But the controls where we didn’t consistently apply lifecycle management (setting expiration dates, conducting post-incident rule reviews, or monitoring impact) became technical debt that accumulated until users noticed.
What we did
We reviewed these mitigations, analyzing what each one was blocking today versus what it was meant to block when created. We removed the rules that were no longer serving their purpose, and kept protections against ongoing threats.
What we’re building
Beyond the immediate fix, we’re improving the lifecycle management of protective controls:
Better visibility across all protection layers to trace the source of rate limits and blocks.
Treating incident mitigations as temporary by default. Making them permanent should require an intentional, documented decision.
Post-incident practices that evaluate emergency controls and evolve them into sustainable, targeted solutions.
Defense mechanisms – even those deployed quickly during incidents – need the same care as the systems they protect. They need observability, documentation, and active maintenance. When protections are added during incidents and left in place, they become technical debt that quietly accumulates.
Thanks to everyone who reported issues publicly! Your feedback directly led to these improvements. And thanks to the teams across GitHub who worked on the investigation and are building better lifecycle management into how we operate. Our platform, team, and community are better together!
SwirlAI founder Aurimas Griciūnas helps tech professionals transition into AI roles and works with organizations to create AI strategy and develop AI systems. Aurimas joins Ben to discuss the changes he’s seen over the past couple years with the rise of generative AI and where we’re headed with agents. Aurimas and Ben dive into some of the differences between ML-focused workloads and those implemented by AI engineers—particularly around LLMOps and agentic workflows—and explore some of the concerns animating agent systems and multi-agent systems. Along the way, they share some advice for keeping your talent pipeline moving and your skills sharp. Here’s a tip: Don’t dismiss junior engineers.
About the Generative AI in the Real World podcast: In 2023, ChatGPT put AI on everyone’s agenda. In 2026, the challenge will be turning those agendas into reality. In Generative AI in the Real World, Ben Lorica interviews leaders who are building with AI. Learn from their experience to help put AI to work in your enterprise.
This transcript was created with the help of AI and has been lightly edited for clarity.
00.44 All right. So today for our first episode of this podcast in 2026, we have Aurimas Griciūnas of SwirlAI. And he was previously at Neptune.ai. Welcome to the podcast, Aurimas.
01.02 Hi, Ben, and thank you for having me on the podcast.
01.07 So actually, I want to start with a little bit of culture before we get into some technical things. I noticed now it seems like you’re back to teaching people some of the latest ML and AI stuff. Of course, before the advent of generative AI, the terms we were using were ML engineer, MLOps. . . Now it seems like it’s AI engineer and maybe LLMOps. I’m assuming you use this terminology in your teaching and consulting as well.
So in your mind, Aurimas, what are some of the biggest distinctions between that move from ML engineer to AI engineer, from MLOps to LLMOps? What are two to three of the biggest things that people should understand?
02.05 That’s a great question, and the answer depends on how you define AI engineering. I think how most of the people today define it is a discipline that builds systems on top of already existing large language models, maybe some fine-tuning, maybe some tinkering with the models. But it’s not about the model training. It’s about building systems or systems on top of the models that you already have.
So the distinction is quite big because we are no longer creating models. We are reusing models that we already have. And hence the discipline itself becomes a lot more similar to software engineering than actual machine learning engineering. So we are not training models. We are building on top of the models. But some of the similarities remain because both of the systems that we used to build as machine learning engineers and now we build as AI engineers are nondeterministic in their nature.
So some evaluation and practices of how we would evaluate these systems remain. In general, I would even go as far as to say that, there are more differences than similarities in these two disciplines, and it’s really, really hard to properly distinguish three main ones. Right?
03.38 So I would say software engineering, right. . .
03.42 So, I guess, based on your description there, the personas have changed as well.
So in the previous incarnation, you had ML teams, data science teams—they were mostly the ones responsible for doing a lot of the building of the models. Now, as you point out, at most people are doing some sort of posttraining from fine-tuning. Maybe the more advanced teams are doing some sort of RL, but that’s really limited, right?
So the persona has changed. But on the other hand, at some level, Aurimas, it’s still a model, so then you still need the data scientist to interpret some of the metrics and the evals, correct? In other words, if you run with completely just “Here’s a bunch of software engineers; they’ll do everything,” obviously you can do that, but is that something you recommend without having any ML expertise in the team?
04.51 Yes and no. A year ago or two years ago, maybe one and a half years ago, I would say that machine learning engineers were still the best fit for AI engineering roles because we were used to dealing with nondeterministic systems.
They knew how to evaluate something that the output of which is a probabilistic function. So it is more of a mindset of working with these systems and the practices that come from actually building machine learning systems beforehand. That’s very, very useful for dealing with these systems.
05.33 But nowadays, I think already many people—many specialists, many software engineers—have already tried to upskill in this nondeterminism and learn quite a lot [about] how you would evaluate these kinds of systems. And the most valuable specialist nowadays, [the one who] can actually, I would say, bring the most value to the companies building these kinds of systems is someone who can actually build end-to-end, and so has all kinds of skills, starting from being able to figure out what kind of products to build and actually implementing some POC of that product, shipping it, exposing it to the users and being able to react [to] the feedback [from] the evals that they built out for the system.
06.30 But the eval part can be learned. Right. So you should spend some time on it. But I wouldn’t say that you need a dedicated data scientist or machine learning engineer specifically dealing with evals anymore. Two years ago, probably yes.
06.48 So based on what you’re seeing, people are beginning to organize accordingly. In other words, the recognition here is that if you’re going to build some of these modern AI systems or agentic systems, it’s really not about the model. It’s a systems and software engineering problem. So therefore we need people who are of that mindset.
But on the other hand, it is still data. It’s still a data-oriented system, so you might still have pipelines, right? Data pipelines to data teams that data engineers typically maintain. . . And there’s always been this lamentation even before the rise of generative AI: “Hey, these data pipelines maintained by data engineers are great, but they don’t have the same software engineering rigor that, you know, the people building web applications are used to.” What’s your sense in terms of the rigor that these teams are bringing to the table in terms of software engineering practices?
08.09 It depends on who is building the system. AI engineers [comprise an] extremely wide range. An engineer can be an AI engineer. A software engineer could be an AI engineer, and a machine learning engineer can be an AI engineer. . .
08.31 Let me rephrase that, Aurimas. In your mind, [on] the best teams, what’s the typical staffing pattern?
08.39 It depends on the size of the project. If it’s just a project that’s starting out, then I would say a full stack engineer can quickly actually start off a project, build A, B, or C, and continue expanding it. And then. . .
08.59 Mainly relying on some sort of API endpoint for the model?
09.04 Not necessarily. So it can be a Rest API-based system. It can be a stream processing-based system. It can be just a CLI script. I would never encourage [anyone] to build a system which is more complex than it needs to be, because very often when you have an idea, just to prove that it works, it’s enough to build out, you know, an Excel spreadsheet with a column of inputs and outputs and then just give the outputs to the stakeholder and see if it’s useful.
So it’s not always needed to start with a Rest API. But in general, when it comes to who should start it off, I think it’s people who are very generalist. Because at the very beginning, you need to understand end to end—from product to software engineering to maintaining those systems.
10.01 But once this system evolves in complexity, then very likely the next person you would be bringing on—again, depending on the product—very likely would be someone who is good at data engineering. Because as you mentioned before, most of the systems are relying on a very high, very strong integration of these already existing data systems [that] you’re building for an enterprise, for example. And that’s a hard thing to do right. And the data engineers do it quite [well]. So definitely a very useful person to have in the team.
10.43 And maybe eventually, once those evals come into play, depending on the complexity of the product, the team might benefit from having an ML engineer or data scientist in between. But then this is more kind of targeting those cases where the product is complex enough that you actually need some allowances for judges, and then you need to evaluate those LLMs as judges so that your evals are evaluated as well.
If you just need some simple evals—because some of them can be exact assertion-based evals—those can easily be done, I think, by someone who doesn’t have past machine learning experience.
11.36 Another cultural question I have is the following. I would say two years ago, 18 months ago, most of these AI projects were conducted. . . Basically, it was a little more decentralized, in other words. So here’s a group here. They’re going to do something. They’re going to build something on their own and then maybe try to deploy that.
But now recently I’m hearing, Aurimas, and I don’t know if you are hearing the same thing, that, at least in some of these big companies, they’re starting to have much more of a centralized team that can help other teams.
So in other words, there’s a centralized team that somehow has the right experience and has built a few of these things. And then now they can kind of consolidate all those learnings and then help other teams. If I’m in one of these organizations, then I approach these experts. . . I guess in the old, old days—I hate this term—they would use some center of excellence kind of thing. So you will get some sort of playbook and they will help you get going. Sort of like in your previous incarnation at Neptune.ai. . . It’s almost like you had this centralized tool and experiment tracker where someone can go in and learn what others are doing and then learn from each other.
Is this something that you’re hearing that people are going for more of this kind of centralized approach?
13.31 I do hear about these kinds of situations, but naturally, it’s always a big enterprise that’s managed to pull that off. And I believe that’s the right approach because that’s also what we have been doing before GenAI. We had those centers of excellence. . .
13.52 I guess for our audience, explain why you think this is the right approach.
13.58 So, two things why I think it is the right approach. The first thing is that we used to have these platform teams that would build out a shared pool of software that can be reused by other teams. So we kind of defined the standards of how these systems should be operated, and the production and the development. And they would decide what kind of technologies and tech stack should be used within the company. So I think it’s a good idea to not spread too widely in the tools that you’re using.
Also, have template repositories that you can just pool and reuse. Because then not only is it easier to kick off and start your build out of the project, but it also helps control how well this knowledge can actually be centralized, because. . .
14.59 And also there’s security, then there’s governance as well. . .
15.03 For example, yes. The platform side is one of those—just use the same stack and help others build it easier and faster. And the second piece is that obviously GenAI systems are still very young. So [it’s] very early and we really do not have, as some would say, enough reps in building these kinds of systems.
So we learn as we go. With regular machine learning, we already had everything figured out. We just needed some practice. Now, if we learn in this distributed way and then we do not centralize learnings, we suffer. So basically, that’s why you would have a central team that holds the knowledge. But then it should, you know, help other teams implement some new type of system and then bring those learnings back into the central core and then spread those learnings back to other teams.
But this is also how we used to operate in these platform teams in the old days, three years, four years ago.
16.12 Right, right, right, right, right, right, right. But then, I guess, what happened with the release of generative AI is that the platform teams might have moved too slow for the rank and file. And so hence you started hearing about what they call shadow AI, where people would use tools that were not exactly blessed by the platform team. But now I think the platform teams are starting to arrest some of that.
16.42 I wonder if it is platform teams who are kind of catching up, or is it the tools that [are] maturing and the practices that are maturing? I think we are getting more and more reps in building those systems, and now it’s easier to catch up with everything that’s going on. I would even go as far as to say it was impossible to be on top of it, and maybe it wouldn’t even make sense to have a central team.
17.10 A lot of these demos look impressive—generative AI demos, agents—but they fail when you deploy them in the wild. So in your mind, what is the single biggest hurdle or the most common reason why a lot of these demos or POCs fall short or become unreliable in production?
17.39 That again, depends on where we are deploying the system. But one of the main reasons is that it is very easy to build a POC, and then it targets a very specific and narrow set of real-world scenarios. And we kind of believe that it solves [more than it does]. It just doesn’t generalize well to other types of scenarios. And that’s the biggest problem.
18.07 Of course there are security issues and all kinds of stability issues, even with the biggest labs and the biggest providers of LLMs, because those APIs are also not always stable, and you need to take care of that. But that’s an operational issue. I think the biggest issue is not operational. It’s actually evaluation-based, and sometimes even use case-based: Maybe the use case is not the correct one.
18.36 You know, before the advent of generative AI, ML teams and data teams were just starting to get going on observability. And then obviously AI generative AI comes into the picture. So what changes as far as LLMs and generative AI when it comes to observability?
19.00 I wouldn’t even call observability of regular machine learning systems and [of] AI systems the same thing.
Going back to a previous parallel, generative AI observability is a lot more similar to regular software observability. It’s all about tracing your application and then on top of those traces that you collect in the same way as you would collect from the regular software application, you add some additional metadata so that it is useful for performing evaluation actions on your agent AI type of system.
So I would even contrast machine learning observability with GenAI observability because I think these are two separate things.
19.56 Especially when it comes to agents and the agents that involve some sort of tool use, then you’re really getting into kind of software traces and software observability at that point.
20.13 Exactly. Tool use is just a function call. A function call is just a considerable software span, let’s say. Now what’s important for GenAI is that you also know why that tool was selected to be used. And that’s where you trace outputs of your LLMs. And you know why that LLM call, that generation, has decided to use this and not the other tool.
So things like prompts, token counts, and how much time to first token it took for which generation, these kinds of things are what is additional to be traced compared to regular, software tracing.
20.58 And then, obviously, there’s also. . . I guess one of the main changes probably this year will be multimodality, if there’s different types of modes and data involved.
21.17 Right. For some reason I didn’t touch upon that, but you’re right. There’s a lot of difference here because inputs and outputs, it’s hard. First of all, it’s hard to trace these kinds of things like, let’s say, audio input and output [or] video images. But I think [an] even harder kind of problem with this is how do you make sure that the data that you trace is useful?
Because those observability systems that are being built out, like LangSmith, Langfuse, and all of others, you know, how do you make it so that it’s convenient to actually look at the data that you trace, which is not text and not regular software spans? How [do] you build, [or] even correlate, two different audio inputs to each other? How do you do that? I don’t think that problem is solved yet. And I don’t even think that we know what we want to see when it comes to comparing this kind of data next to each other.
22.30 So let’s talk about agents. A friend of mine actually asked me yesterday, “So, Ben, are agents real, especially on the consumer side?” And my friend was saying he doesn’t think it’s real. So I said, actually, it’s more real than people think in the following sense: First of all, deep research, that’s agents.
And then secondly, people might be using applications that involve agents, but they don’t know it. So, for example, they’re interacting with the system and that system involves some sort of data pipeline that was written and is being monitored and maintained by an agent. Sure, the actual application is not an agent. But underneath there’s agents involved in the application.
So to that extent, I think agents are definitely real in the data engineering and software engineering space. But I think there might be more consumer apps that underneath there’s some agents involved that consumers don’t know about. What’s your sense?
23.41 Quite similar. I don’t think there are real, full-fledged agents that are exposed.
23.44 I think people when people think of agents, they think of it as like they’re interacting with the agent directly. And that may not be the case yet.
24.04 Right. So then, it depends on how you define the agent. Is it a fully autonomous agent? What is an agent to you? So, GenAI in general is very useful on many occasions. It doesn’t necessarily need to be a tool-using self-autonomous agent.
24.21 So like I said, the canonical example for consumers would be deep research. Those are agents.
24.30 If you think of that example, it’s a bunch of agents searching across different data collections, and then maybe a central agent unifying and presenting it to the user in a coherent way.
So from that perspective, there probably are agents powering consumer apps. But they may not be the actual interface of the consumer app. So the actual interface might still be rule-based or something.
25.07 True. Like data processing. Some automation is happening in the background. And a deep research agent, that is exposed to the user. Now that’s relatively easy to build because you don’t need to very strongly evaluate this kind of system. Because you expect the user to eventually evaluate the results.
25.39 Or in the case of Google, you can present both: They have the AI summary, and then they still have the search results. And then based on the user signals of what the user is actually consuming, then they can continue to improve their deep research agent.
25.59 So let’s say the disasters that can happen from wrong results were not that bad. Right? So.
26.06 Oh, no, it can be bad if you deploy it inside the enterprise, and you’re using it to prepare your CFO for some earnings call, right?
26.17 True, true. But then you know whose responsibility is it? The agent’s, that provided 100%…?
26.24 You can argue that’s still an agent, but then the finance team will take those results and scrutinize [them] and make sure they’re correct. But an agent prepared the initial version.
26.42 Yeah. So the reason I bring up agents is, do agents change anything from your perspective in terms of eval, observability, and anything else?
26.55 They do a little bit, compared to agent workflows that are not, full agents, the only change that really happens. . . And we are talking now about multi-agent systems, where multiple agents can be chained or looped in together. So really the only difference there is that the length of the trace is not deterministic. And the amount of spans is not deterministic. So in the sense of observability itself, the difference is minimal as long as those agents and multi-agent systems are running in a single runtime.
27.44 Now, when it comes to evals and evaluation, it is different because you evaluate different aspects of the system. You try to discover different patterns of failures. As an example, if you’re just running your agent workflow, then you know what kind of steps can be taken, and then you can be almost 100% sure that the entire path from your initial intent to the final answer is completed.
Now with agent systems and multi-agent systems, you can still achieve, let’s say, input-output. But then what happens in the middle is not a black box, but it is very nondeterministic. Your agents can start looping the same questions between each other. So you need to also look for failure signals that are not present in agentic workflows, like too many back-and-forth [responses] between the agents, which wouldn’t happen in a regular agentic workflow.
Also, for tool use and planning, you need to figure out if the tools are being executed in the correct order. And similar things.
29.09 And that’s why I think in that scenario, you definitely need to collect fine-grained traces, because there’s also the communication between the agents. One agent might be lying to another agent about the status of completion and so on and so forth. So you need to really kind of have granular level traces at that point. Right?
29.37 I would even say that you always need to have written the lower-level pieces, even if you’re running a simple RAG system, which you will learn by the generation system, you still need those granular traces for each of the actions.
29.52 But definitely, interagent communication introduces more points of failure that you really need to make sure that you also capture.
So in closing, I guess, this is a fast-moving field, right? So there’s the challenge for you, the individual, for your professional development. But then there’s also the challenge for you as an AI team in how you keep up. So any tips at both the individual level and at the team level, besides going to SwirlAI and taking courses? [laughs] What other practical tips would you give an individual in the team?
30.47 So for individuals, for sure, learn fundamentals. Don’t rely on frameworks alone. Understand how everything is really working under the hood; understand how those systems are actually connected.
Just think about how those prompts and context [are] actually glued together and passed from an agent to an agent. Do not think that you will be able to just mount a framework right on top of your system, write [a] few prompts, and everything will magically work. You need to understand how the system works from the first principles.
So yeah. Go deep. That’s for individual practitioners.
31.32 When it comes to teams, well, that’s a very good question and a very hard question. Because, you know, in the upcoming one or two years, everything can change so much.
31.44 And then one of the challenges, Aurimas, for example, in the data engineering space. . . It used to be, several years ago, I have a new data engineer in the team. I have them build some basic pipelines. Then they get confident, [and] then they build more complex pipelines and so on and so forth. And then that’s how you get them up to speed and get them more experience.
But the challenge now is a lot of those basic pipelines can be built with agents, and so there’s some amount of entry-level work that used to be the place where you can train your entry-level people. Those are disappearing, which also impacts your talent pipeline. If you don’t have people at the beginning, then you won’t have experienced people later on.
So any tips for teams and the challenge of the pipeline for talent?
32.56 That’s such a hard question. I would like to say, do not dismiss junior engineers. Train them. . .
33.09 Oh, I yeah, I agree completely. I agree completely.
33.14 But that’s a hard decision to make, right? Because you need to be thinking about the future.
33.26 I think, Aurimas, the mindset people have to [have is to] say, okay, so the traditional training grounds we had, in this example of the data engineer, were these basic pipelines. Those are gone. Well, then we find a different way for them to enter. It might be they start managing some agents instead of building pipelines from scratch.
33.58 Yeah. Yeah. We don’t know. The agents even in the data engineering space are still human-in-the-loop. So in other words a human still needs to monitor [them] and make sure they’re working. So that could be the entry-level for junior data engineers. Right?
34.13 Right. But you know that’s the hard part about this question. Then answer is, that could be, but we do not know, and for now maybe it doesn’t make sense. . .
34.28 My point is that if you stop hiring these juniors, I think that’s going to hurt you down the road. So you just hired a junior and hired the junior and then stick them in a different track, and then, as you say, things might change, but then they can adapt. If you hire the right people, they will be able to adapt.
34.50 I agree, I agree, but then, there are also people who are potentially not right for that role, let’s say, and you know, what I. . .
35.00 But that’s true even when you hired them and you assigned them to build pipelines. So same thing, right?
35.08 The same thing. But the thing I see with the juniors and less senior people who are currently building is that we are relying too much on vibe coding. I would also suggest looking for some ways on how to onboard someone new and make sure that the person actually learns the craft and not just comes in and vibe codes his or her way around, making more issues for senior engineers then actually helps.
35.50 Yeah, this is a big topic, but one of the challenges, all I can say is that, you know, the AI tools are getting better at coding at some level because the people building these models are using reinforcement learning and the signal in reinforcement learning is “Does the code run?” So then what people are ending up with now with this newer generation of these models is [that] they vibe code and they will get code that runs because that’s what the reinforcement learning is optimizing for.
But that doesn’t mean that that code doesn’t introduce proper to the right. But on the face of it, it’s running, right? An experienced person obviously can probably handle that.
But anyway, so last word, you get the last word, but take us on a positive note.
36.53 [laughs] I do believe that the future is bright. It’s not grim, not dark. I am very excited about what is happening in the AI space. I do believe that it will not be as fast. . . All this AGI and AI taking over human jobs, it will not happen as fast as everyone is saying. So you shouldn’t be worried about that, especially when it comes to enterprises.
I believe that we already had [very powerful] technology one or one and a half years ago. [But] for enterprises to even utilize that kind of technology, which we already had one and a half years ago, will still take another five years or so to fully actually get the most out of it. So there will be enough work and jobs for at least the upcoming 10 years. And I think, people should not be worried too much about it.
38.06 But in general, eventually, even the ones who will lose their jobs will probably respecialize in that long period of time to some more valuable role.
38.18 I guess I will close with the following advice: The main thing that you can do is just keep using these tools and keep learning. I think the distinction will be increasingly between those who know how to use these tools well and those who do not.
We’re excited to announce the general availability of GitLab Duo Agent Platform. This is an important moment for GitLab, our customers and the industry at large. It is our first step in delivering our vision to bring agentic AI into the entire software development lifecycle.
AI tools have been rapidly improving developers’ ability to write code, and in some cases, developers are reporting 10x productivity gains. Unfortunately, since only about 20% of a developer’s time is spent writing code, the associated improvement in total innovation velocity and delivery gained by AI is incremental. This is often described as the AI paradox in software delivery.
In addition, for many teams, increasing the speed of code authoring has led to new bottlenecks including a larger backlog of code reviews, security vulnerabilities, compliance checks and downstream bug fixes.
GitLab Duo Agent Platform addresses the AI paradox by unlocking intelligent orchestration and agentic AI automation across the software lifecycle.
Learn more in this video, and read more below.
💡 Join GitLab Transcend on February 10 to learn how agentic AI transforms software delivery. Hear from customers and discover how to jumpstart your own modernization journey. Register now.
We're also excited to announce that GitLab customers with active GitLab Premium and Ultimate subscriptions are being credited with $12 and $24 dollars, respectively, in GitLab Credits per user at no additional cost.* These credits will refresh every month and give users access to all GitLab Duo Agent Platform features.
Here is a simple explanation for how GitLab Credits work: a GitLab Credit is a virtual currency used for GitLab’s usage-based products. GitLab Duo Agent Platform usage will draw down on available credits, starting with the included credits mentioned above. From there, customers can decide to commit to a shared pool of credits for their entire organization, or pay for them monthly, on demand. For more information, please check out our article introducing GitLab Credits.
Customers of GitLab Duo Pro or Duo Enterprise subscriptions are welcome to continue using those products, or migrate to Duo Agent Platform at any time. The remainder of your Duo Enterprise contract value can be converted into GitLab Credits at any time. Contact your GitLab representative to learn more.
Here are exciting use cases and capabilities you can try today:
A unified experience for human and agent collaboration
GitLab Duo Agent Platform introduces a unified user experience designed for seamless integration between humans and their AI agents inside GitLab. Developers and their teams can engage Duo Agentic Chat on nearly every page, ask questions contextually, follow async agentic sessions and interact with agents within familiar workflows like issues, merge requests, and pipeline activities — making AI actions transparent and easy to guide through everyday work.
Gitlab Duo Agentic Chat brings true multi-step reasoning across the GitLab Web UI and IDEs, using full lifecycle context from issues, merge requests, pipelines, security findings, and more. Building on the previously released Duo Chat, Agentic Chat can perform actions on your behalf autonomously and help you answer complex questions more comprehensively. It gives every member of the software team accurate, context-aware guidance that helps improve onboarding, code quality, and delivery speed.
Analyze
In the Web UI, Agentic Chat can create issues, epics, merge requests, and provide summaries, highlight key findings, and offer actionable guidance based on real-time context from the specific project, issue, epic, merge request, and more. Agentic Chat helps developers understand unfamiliar code, dependencies, architecture, and project structure, in the IDE or inside a GitLab repo.
Code
Agentic Chat can generate code, configurations, and infrastructure-as-code across a wide range of languages and frameworks. It can help fix bugs, modernize architecture and code, generate tests, and produce documentation for faster onboarding. Directly at developers' fingertips, Agentic Chat is their collaboration partner in VS Code, JetBrains IDEs, Cursor, and Windsurf, with optional user- and workspace-level rules to tailor responses.
CI/CD
Agentic Chat can help you better understand, configure, and troubleshoot existing pipelines, or create new ones from scratch.
Secure
Agentic Chat can explain vulnerabilities, prioritize issues based on reachability, and recommend fixes that can help save you time.
Agents: Specialists that collaborate on demand
GitLab Duo Agent Platform enables developers to delegate tasks to specialized agents. The platform offers a unique combination of foundational, custom, and external agents, all seamlessly integrated into GitLab user experience, making it easy to choose the right agent for any task.
Foundational agents are pre-built by GitLab experts and are ready out-of-the-box to handle the most complex tasks in the software delivery cycle. The following foundational agents are included as part of GitLab Duo Agent Platform’s general availability, with others currently in beta and coming soon.
Planner Agent helps teams structure, prioritize, and break down work directly inside GitLab so planning becomes clearer, faster, and easier to act on.
Security Analyst Agent reviews vulnerabilities and security signals, explains their impact in plain language, and helps teams understand what to address first.
Custom agents can be built using the AI Catalog, a central repository where teams create, publish, manage, and share custom agents and flows across the organization. Teams can create agents and flows with specific context and capabilities to replicate the way their engineering team works — and tackle problems using the engineering standards and guardrails their engineers use.
External agents are seamlessly integrated into GitLab and include some of the very best AI tools available, including Claude Code from Anthropic and Codex CLI from OpenAI. Users will enjoy native GitLab access to these tools for use cases like code generation, code review, and analysis with transparent security and embedded LLM subscriptions.
Together, these approaches give teams flexibility in how they adopt agentic AI, from specialized agents, to organization-specific automation, to integrating external AI tools — all within a single, governed platform.
Flows: Turning multi-step work into repeatable, guided progress
Flows automate complex tasks with multiple agentic workflows, from start to finish.
Our engineering team has built several flows included at GA, with more on the way:
MCP Client: Connect GitLab Duo Agent Platform to the tools your teams already use
The MCP Client enables GitLab Duo Agent Platform in IDEs to securely connect to external systems like Jira, Slack, Confluence, and other MCP-compatible tools to pull in context and take action across your DevSecOps toolchain.
Instead of AI assistance being siloed inside individual tools, the MCP Client allows GitLab Duo Agent Platform to understand and operate across the systems where planning, collaboration, and execution actually happen. This reduces manual context switching and enables more complete, end-to-end AI-powered workflows that reflect how teams work in practice.
Included at GA:
Connection to external MCP-compatible systems such as Jira, Confluence, Slack, Playwright, and Grafana
Configuration at the workspace and user level
Group-level controls to enable or restrict MCP usage
User approval flow for tool access
Support across Agentic Chat in the IDE extensions
We plan to add more features to the GitLab MCP server capability, which is currently in beta, and make it generally available in upcoming releases.
Choose the right model for your team and workloads
GitLab Duo Agent Platform is built on a flexible model selection framework that enables teams to tailor the platform to align with their privacy, security, and compliance needs. GitLab defaults to an optimal LLM for each feature, but administrators have the option to select from supported models such as OpenAI GPT-5 variants, Mistral, Meta Llama, and Anthropic Claude. This gives teams more precise control and flexibility over what is used for chat, coding tasks, and agent interactions for each specific use case, based on your organization’s standards. For a full list of supported models and details on model section configuration, see the Model Selection section of our documentation.
Governance, visibility, and deployment flexibility
The GitLab Duo Agent Platform gives organizations the control and transparency they need to help them adopt AI responsibly, while offering flexible deployment options that work across different environments.
Included at GA:
Available on all platforms: GitLab.com, GitLab Self-Managed, and GitLab Dedicated as part of the GitLab 18.8 release cycle.
Governance and visibility: Teams can see how agents are used, what actions they perform, and how they contribute to work. Usage and activity details help leaders understand adoption, measure impact, and ensure AI is being used appropriately. These controls make it easier to roll out AI at scale with confidence.
Group-based access controls: Administrators can define namespace-level rules governing which users can access GitLab Duo Agent Platform features, supporting flexible adoption from immediate organization-wide enablement to phased rollouts. With LDAP and SAML integration, they can enable governance at scale without manual configuration.
Model selection and self-hosted options: LLM selection is available for all GA features across GitLab.com, Self-Managed, and Dedicated. Top-level namespace owners choose the model, and subgroups inherit those settings automatically. For organizations that want more control, the platform supports self-hosted models for GitLab Self-Managed deployments.
Watch a demo of GitLab Duo Agent Platform in action:
Stay up to date with GitLab
To make sure you’re getting the latest features, security updates, and performance improvements, we recommend keeping your GitLab instance up to date. The following resources can help you plan and complete your upgrade:
Upgrade Path Tool – enter your current version and see the exact upgrade steps for your instance
Upgrade Documentation – detailed guides for each supported version, including requirements, step-by-step instructions, and best practices
By upgrading regularly, you’ll ensure your team benefits from the newest GitLab capabilities and remains secure and supported.
For organizations that want a hands-off approach, consider GitLab’s Managed Maintenance service. Managed Maintenance can help your team stay focused on innovation while GitLab experts keep your Self-Managed instance reliably upgraded, secure, and ready to lead in DevSecOps. Ask your account manager for more information.
* GitLab customers with active Premium and Ultimate subscriptions will automatically receive $12 and $24 of included credits per user, respectively, which will reset each month. These credits are available for a limited time, and are subject to change (see promo terms).
This blog post contains "forward‑looking statements" within the meaning of Section 27A of the Securities Act of 1933, as amended, and Section 21E of the Securities Exchange Act of 1934. Although we believe that the expectations reflected in these statements are reasonable, they are subject to known and unknown risks, uncertainties, assumptions and other factors that may cause actual results or outcomes to differ materially. Further information on these risks and other factors is included under the caption "Risk Factors" in our filings with the SEC. We do not undertake any obligation to update or revise these statements after the date of this blog post, except as required by law.
Today, we’re excited to launch Budget Bytes, a new series for builders who want to create real, AI-powered apps using Azure SQL Database, without expensive infrastructure or guesswork. 🌟 Get started for FREE: https://aka.ms/budgetbytes/freeoffer 🌟
Budget Bytes is built for budget-conscious developers who care about shipping, not just experimenting. Each episode walks through practical patterns for grounding AI in your own data with Azure SQL Database, building full-stack apps with Copilot, exploring agentic RAG architectures, and keeping costs shockingly low
You’ll see step-by-step demos, real architectures, and honest cost math, so you know exactly what you can build today and how to use AI responsibly.
Here’s what’s coming up: ✅ Ground AI in your own data using Azure Foundry + Azure SQL Database. ✅ Build and run a full web app with Copilot + Azure SQL DB, all for under $10. ✅ See an end-to-end Agentic RAG sample using Azure SQL, Azure Container Apps, and Static Web Apps. ✅ Learn how to build AI agents with Copilot Studio + Azure SQL ✅A fireside chat with leaders on Azure SQL Database affordability, AI, and the future of building modern applications.
Whether you’re a student, a startup, a small business, or a seasoned developer, Budget Bytes is your guide to building smarter apps with Azure SQL Database, adding AI with confidence, and staying within budget.