xAI has launched Grok Build, "a coding agent of its own to serve as competitor to its rivals' products, such as Anthropic's Claude Code," reports Engadget:
As Bloomberg notes, xAI has been trying to catch up to its rival companies like Anthropic and OpenAI. Elon Musk, the company's founder and CEO, previously admitted that it has fallen behind its competitors when it comes to coding. A couple of months ago, Musk said he was rebuilding xAI "from the foundations up" after several co-founders had left the company. One of the company's executives reportedly told staffers to work on getting Grok to match Claude's performance across various tasks.
More details from PCMag:
Grok Build is currently available in beta to those with a SuperGrok Heavy subscription, which starts at $300 per month. Just download it from the xAI website and log in. It's described as "a powerful new coding agent and CLI for professional software engineering and complex coding work." In its early version, xAI is seeking feedback and looking to fix any bugs... Only a few features have been highlighted, including a plan mode that lets you review, edit, and approve a plan before execution, and support for existing plug-ins and workflows.
Ryan, Kevin, and Travis discuss how impossible it is to keep up with AI’s pace and use recent OpenClaw updates to illustrate what’s happening at the “tip of the spear.” They recap an OpenClaw community-driven plugin architecture overhaul that caused short-term instability but created a smaller stable core with extensible plugins. They cover new voice interaction options, including Discord real-time voice features (buffers, barge-in detection, echo control), bringing agents into Google Meet via Twilio dial-in, and broader implications of voice and multimodal “thinking machines” interaction models. The hosts explore cognitive debt/coherence challenges as AI builds faster than humans can comprehend, and highlight OpenClaw’s security hardening (1,300 advisories processed) plus major memory upgrades that create structured person cards and a wiki-like knowledge base, raising governance and compartmentalization concerns for enterprises. They also note improved commitment tracking, self-modifying/self-building capabilities, and auto-generated skills.
00:00 Welcome Back Setup
00:55 Why Youre Behind
01:13 OpenClaw Overview
02:22 Community Moves Fast
03:04 Plugin Overhaul Fallout
04:25 Stable Core Plugins
05:39 Pick Your AI Strategy
08:48 Cognitive Debt Explained
10:26 Daily Reps Mindset
12:07 Voice Comes to OpenClaw
13:04 Discord Voice and Meet
18:21 Metacognition Modalities
21:30 Do You Need Code
26:09 Voice vs Text Context
29:35 Thinking Machines Tease
29:39 Interaction Models Demo
30:53 Voice Latency Tradeoffs
33:27 Conversation Cues Vision
36:39 OpenClaw Security Hardening
38:31 Memory And Knowledge Base
40:04 Enterprise Governance Dilemma
45:21 Corporate Brain Example
48:59 Auto Commitments Heartbeat
51:45 Stability Updates Skills
52:44 Wrap Up And Thanks
This is a public episode. If you would like to discuss this with other subscribers or get access to bonus episodes, visit aiunprompted.substack.com
PostgreSQL has become foundational to how modern applications are built. It powers everything from early‑stage startups to some of the most demanding production systems in the world. Its longevity isn’t accidental, it’s the result of decades of engineering discipline, community collaboration, and a relentless focus on correctness and extensibility.
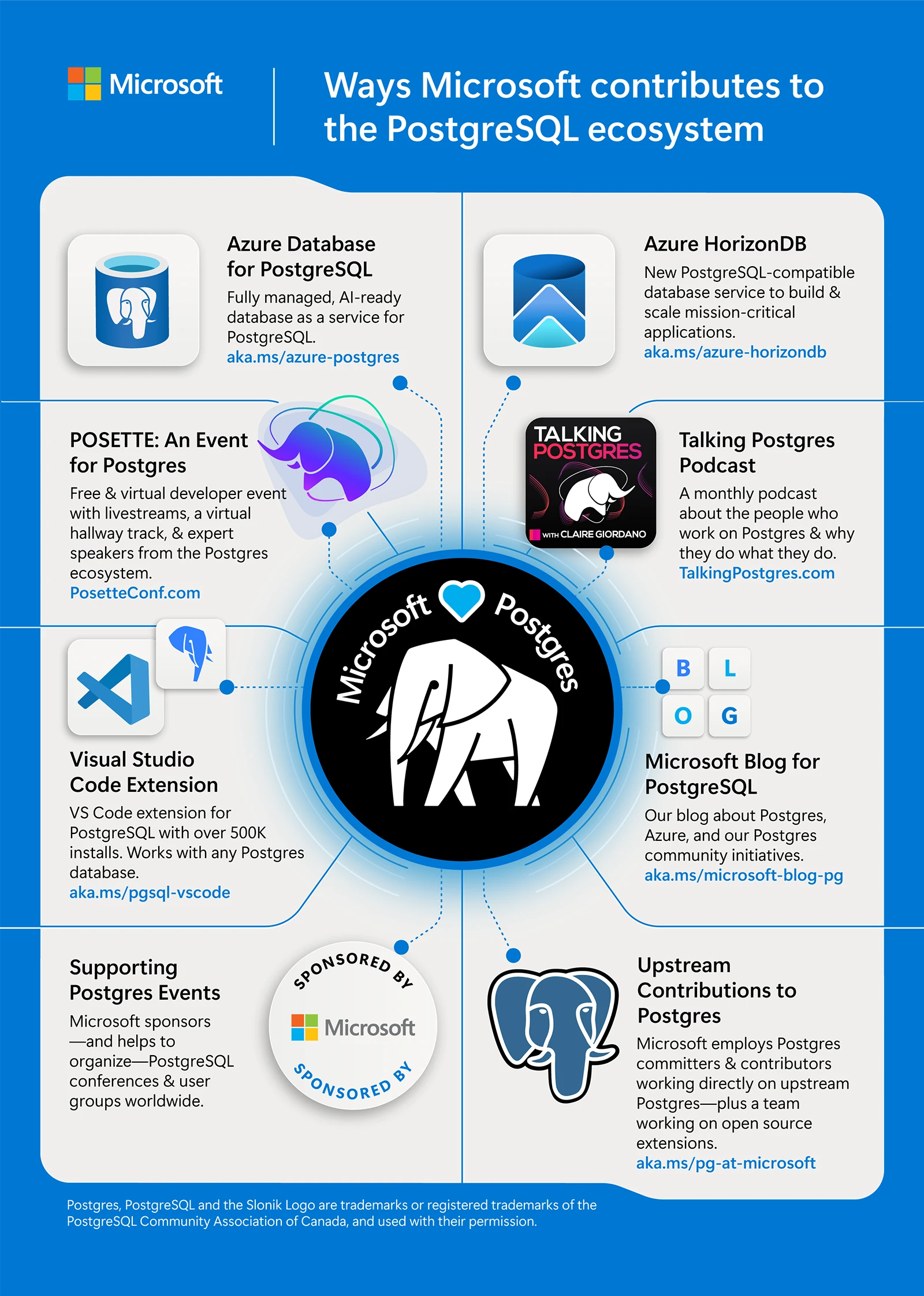
As application architectures evolve, and as AI becomes a default part of the software stack, PostgreSQL continues to adapt. This adaptability is a key reason Microsoft has been investing deeply in PostgreSQL: 345 commits contributed to the latest PostgreSQL release, a team of PostgreSQL committers and contributors working directly on the upstream project, and a growing portfolio of managed services, developer tools, and community programs built around Postgres on Azure. Here’s what’s driving that investment, and what it means for the people building on Postgres today.
Figure 1: This infographic highlights the many ways Microsoft contributes to and supports the PostgreSQL ecosystem
PostgreSQL is trusted with real production systems
PostgreSQL earned its reputation by solving hard problems in production environments: transactional correctness, concurrency control, extensibility, and operational resilience. These characteristics weren’t designed for isolated benchmarks; they emerged through years of running mission critical systems under real pressure.
Microsoft runs PostgreSQL at global scale and sees these same patterns firsthand. Many upstream contributions, such as recent work in PostgreSQL 18 on asynchronous I/O, vacuum behavior, and query planning, are informed directly by production bottlenecks encountered at scale.
This feedback loop works both ways. Improvements made upstream benefit the entire PostgreSQL ecosystem, while lessons learned from large‑scale deployments continue to inform future development.
Databases are becoming part of the AI stack
Databases are no longer isolated storage layers. In modern systems, they increasingly sit inside feedback loops that involve reasoning, ranking, and decision‑making.
Developers building AI‑enabled applications are asking new questions:
How close can vector data live to transactional data?
How can similarity search respect SQL predicates?
How can inference, ranking, and structured data work together without excessive glue code?
As applications scale, not every workload benefits from the same architectural approach.
Some teams want a fully open, single‑node PostgreSQL experience with minimal abstraction. Others need elastic scale, multi‑zone replication, and fast failover but don’t want to push complexity into the application layer.
This diversity is why Microsoft supports multiple PostgreSQL deployment models on Azure:
Microsoft’s investment in PostgreSQL goes beyond product announcements for Azure’s managed services to include shipped code from in-house contributors, upstream collaboration, and production reliability. As our learnings expand, we’ve used these insights to enrich the open-source Postgres engine for the broader community.
Upstream contributions that benefit everyone
Postgres committers and developers at Microsoft actively contribute to the PostgreSQL open source project, working alongside the global community on core improvements. Recent version updates include contributions across:
Asynchronous I/O foundations.
Performance improvements in vacuum and memory management.
Planner and execution enhancements for large datasets.
These changes land upstream first, ensuring that improvements are broadly available not tied to any single cloud or service. A transparent overview of our Postgres work is published annually.
Architectural motivations behind Azure HorizonDB
Azure HorizonDB was built to address a specific class of PostgreSQL workloads that are constrained by single node scaling but not well served by application level sharding. For example, high-throughput, low-latency systems that require horizontal scale without adding application complexity.
Key architectural goals shaped Azure HorizonDB:
Independent scaling of compute and storage.
Failover and recovery operations decoupled from data size.
Azure HorizonDB extends PostgreSQL’s reach while maintaining compatibility expectations that developers rely on.
Improving the developer experience where work actually happens
PostgreSQL has long been a developer‑centric database. Tooling investments on Azure reflect that mindset.
With more than 500,000 installs, the Visual Studio Code extension for PostgreSQL brings provisioning, schema exploration, performance diagnostics, and migration workflows directly into the IDE developers already use. Integrated GitHub Copilot assistance helps with SQL authoring, tuning, and even complex migrations, such as Oracle to PostgreSQL, which is one of the most challenging real world scenarios teams face.
The extension helps to remove unnecessary friction while keeping PostgreSQL familiar.
Investing in the PostgreSQL ecosystem
PostgreSQL’s progress has always depended on its community. That’s why Microsoft’s investment extends beyond products and services.
Microsoft sponsors and helps organize PostgreSQL conferences and user groups worldwide including PGConf.dev, PGConf EU, PGConf India, and many others. POSETTE: An Event for Postgres is a free and virtual Postgres event organized by the Postgres team at Microsoft and in partnership with AMD. It covers a wide range of topics including internals, ecosystem tools, real world debugging stories, and production architectures. This year’s 5th annual event, hosted 16-19 of June, brings together contributors, users, and engineers from across the Postgres community to share what works in practice.
Talking Postgres, a monthly podcast that our team produces, features conversations with people who work with Postgres, from longtime contributors to production engineers solving hard problems at scale.
And the Microsoft Blog for PostgreSQL provides regular deep dives on product updates, migration guidance, and real-world Postgres usage patterns on Azure.
Looking ahead
PostgreSQL is approaching its fourth decade and it’s still accelerating. What began as a research project at UC Berkeley, is now a widely used database for modern applications, from developer experiments to mission-critical production environments.
As the community celebrates this moment, Microsoft’s focus remains consistent:
Strengthening PostgreSQL core through upstream collaboration.
Extending PostgreSQL responsibly for AI‑driven and cloud‑native workloads.
Preserving developer trust through open standards and transparency.
These priorities shape ongoing investments in Azure Database for PostgreSQL, Azure HorizonDB, developer tooling, and community engagement. Updates across these areas are now shared regularly through the Microsoft for PostgreSQL LinkedIn page.
A clear takeaway
PostgreSQL’s success has always been rooted in engineering discipline and community trust. Sustaining that success requires meaningful, long‑term investment, not just in services, but in the project itself and the people behind it.
Microsoft’s commitment to PostgreSQL reflects that belief: contributing upstream, building thoughtfully, and supporting an ecosystem that continues to move the database forward.
I spent the day applying the agent-readiness playbook — first written for apis.io — across twenty-two subdomains of the API Evangelist network. The result is end-to-end agent-readable infrastructure built on RFCs rather than vendor conventions, sitting in front of a network of static Jekyll sites that humans browse the same way they always have.
This isn’t a hypothetical exercise. It is the concrete operational answer to the question I keep getting in conversations: what does an agent-readable site actually look like, end to end? Here is what I shipped.
Every Subdomain Has a Machine-Readable Front Door
Every site under *.apievangelist.com now publishes three things at well-known locations that an agent can hit before it parses any HTML:
/.well-known/api-catalog — an RFC 9264 linkset, served under RFC 9727’s well-known URI. Each entry has an anchor (the resource’s canonical URL), a title, description, and zero or more of service-desc (OpenAPI / AsyncAPI URLs), service-doc (human documentation), and describedby (JSON Schema / JSON-LD). On apis.apievangelist.com the linkset has 6,310 entries — one per API across the entire network. On contracts.apievangelist.com it has 5,280 entries — one per provider. The smaller sites carry per-resource catalogs of their own.
/apis.json — the site’s own machine-readable identity in the APIs.json format. Name, description, tags, maintainers, support contact, GitHub repo. The “who are you and what do you offer” file an agent reads instead of crawling.
/robots.txt — with explicit AI consent signals. Beyond the usual Allow: /, every site now publishes:
Search indexing, AI inference, and AI training are explicitly permitted. The Cloudflare Content Signals and IETF AIPREF formats are both included for coverage. Consent moves from terms-of-service prose into a header an agent can parse.
That is three machine-readable files times twenty-two sites — sixty-six new artifacts that didn’t exist this morning. None of them require an agent to scrape HTML to discover what the site offers.
A Cloudflare Worker Doing What Static Hosting Can’t
GitHub Pages does a lot of things well. It does not let you set arbitrary Content-Type headers. It does not let you inject Link headers. It does not let you content-negotiate on Accept. It does not let you read inbound signed bot headers and surface them.
So I shipped a single Cloudflare Worker in front of *.apievangelist.com doing four jobs:
Sets Content-Type: application/linkset+json on the /.well-known/api-catalog files. Pages serves them as text/plain otherwise, which makes the most important machine-readable file on the site look like a blob of unstructured text to a strict client.
Injects RFC 8288Link headers on every HTML response — rel="api-catalog", rel="agent-skills", rel="sitemap", and rel="alternate"; type="text/markdown". Hit any page with curl -I and you can find the machine surface without parsing the page body. This is the single highest-leverage change in the whole project. Every HTML page is now self-describing for agents.
Markdown content negotiation. Send Accept: text/markdown to https://apis.apievangelist.com/store/anthropic-messages-api/ and you get this back, synthesized from the catalog entry:
One URL, two representations. Humans get the HTML page they have always gotten. Agents get clean structured markdown synthesized from the same catalog data. The HTML response advertises the markdown alternate in its Link headers so agents don’t have to guess that it exists. This works on every *.apievangelist.com/store/<slug>/ URL across the network — apis, contracts, standards, policies, rules, strategies, properties, the lot.
Web Bot Auth observability. The Worker detects RFC 9421 HTTP Message Signatures tagged web-bot-auth (draft-meunier) and surfaces them in an x-bot-auth response header. Cloudflare’s edge verdict (cf-verified-bot: true) is trusted when present. Full Ed25519 verification is scaffolded for a follow-up; observability today gives me the logs to drive that work.
About 250 lines of JavaScript, sitting in front of a network of static origins. It is the cheapest way I know of to graft an agent-ready edge onto a Jekyll site without rewriting any of the Jekyll.
Agent Skills — A Published Operating Manual
I shipped three Agent Skills at apievangelist.com/skills/:
discover-apievangelist — primes an agent with the network’s structure, the discovery endpoints, the content-negotiation conventions. The skill an agent should hit first.
search-apis — keyword / provider / tag search against the catalog endpoints. Includes a runnable Python recipe.
fetch-api-spec — given an apis.apievangelist.com or contracts.apievangelist.com URL, pull the OpenAPI / AsyncAPI directly from the provider’s GitHub repo.
Skills are the closest thing the agent ecosystem has to a published “operating manual.” Shipping them means agents do not have to infer how to use the site — they read instructions I wrote. The index lives at /skills/index.json with a $schema reference to the agentskills.io schema. The Worker advertises this index in every HTML response’s Link: rel="agent-skills" header.
JSON-LD Context for the API Evangelist Vocabulary
Published at /context.jsonld. It defines the API Evangelist terms — Provider, API, Contract, Property, Spec, Capability, Policy, Rule, Standard, Strategy, Experience, plus the apis.yml-specific keys (aid, baseURL, humanURL, specificationVersion) and the RFC 9264 linkset terms — and maps each to Schema.org where applicable. Provider is a schema:Organization. API is a schema:WebAPI. name is schema:name. The enriched catalogs reference this context so downstream consumers can resolve terms to standard vocabulary.
This is the smallest defensible JSON-LD step. A larger pass — per-resource contexts published as their own dereferenceable IRIs — is on the list.
A Source Widget On Every Detail Page
Every API detail page on apis.apievangelist.com and every contract page on contracts.apievangelist.com now renders the upstream YAML inline, with Prism syntax highlighting, line numbers, search-within-source, a YAML ↔ JSON toggle, and a download button. Humans see exactly what agents see. The structured data is not hidden behind the prose — it is the page, displayed alongside it.
I cribbed this from the apis.io implementation. The fact that I could lift a 375-line include from one Jekyll site to another and have it work is itself a testament to keeping the structured data at the surface rather than buried.
Why the Edge Layer Is the Hinge
If I had to point at one decision that made all the rest of this work, it is the Worker. Every other piece of the playbook depends on it.
The /.well-known/api-catalog is useless if the content-type isn’t application/linkset+json. The Worker fixes that.
The Link headers are how agents discover the catalog, the skills, and the markdown alternates. The Worker injects them.
Markdown content negotiation is the agent-readable representation of every detail page. The Worker is what does the synthesis.
Web Bot Auth observability is how I will know which agents are showing up, what they sign as, and whether their signatures verify. The Worker is the only place that signal exists.
Static hosting could not do any of this. Adding a Worker did not require rewriting the static origins. The Worker sits between the agent and Pages and grafts on the four things Pages cannot do. Two-hundred-fifty lines of JavaScript. One configuration file. Two-hundred-something subdomains’ worth of pages becoming meaningfully more agent-readable as a single deploy.
Where the Web Sits Today
Most public sites still treat agents as a hostile species — gated, rate-limited, crawled apologetically by web archives, and parsed via HTML even when the underlying data is structured. The result is a web that is much harder for agents to read than it should be, and structured data buried under HTML that nobody wants to scrape.
I do not think this is sustainable. The volume of agent traffic is climbing, and the cost of every agent visit re-doing HTML parsing the site already paid to render is a tax the whole ecosystem is paying. The fix is the boring one — publish your data the way you want it consumed, advertise where it lives in Link headers an agent can read in one request, and consent explicitly in robots.txt about what you do and do not permit.
Twenty-two sites. Sixty-six new machine-readable artifacts. A Worker in front of all of it. The cost was a day of work on top of infrastructure I already had. The cost of not doing this — across the API economy — is going to be hundreds of millions of agent requests scraping HTML they did not need to scrape because the structured data was never published next to the page.
What I Didn’t Do
To be honest about the limits:
No llms.txt. The RFC 9264 catalog plus markdown content negotiation cover the same use case using existing standards. I did not want to ship a third overlapping discovery file.
No bespoke “agent API.” One URL, two representations, via content negotiation. Splitting the human surface from the agent surface creates two surfaces to maintain. I’d rather keep them coupled.
No full Web Bot Auth verification yet. Observability is in place. Ed25519 signature verification against the agent’s published key directory is a follow-up. The scaffolding I shipped gives me the logs to drive that work.
No per-resource JSON-LD contexts. One network-level context for now. Per-resource is the next layer.
What’s Next
Verify the Web Bot Auth signatures rather than just observing them. RFC 9421 over the canonical message, key fetch from the agent’s directory, store a verification verdict.
Capability-shaped MCP surfaces in front of the same catalog. Every API in apis.apievangelist.com has a description, an OpenAPI, a JSON Schema, and now an agent-readable representation. The next step is to expose them as MCP-callable capabilities — not just discoverable APIs, but executable capabilities, which is what the agent ecosystem actually wants.
The same playbook applied to the Naftiko network. Same RFCs, same Worker pattern, same agent skills. The Naftiko surface is younger and more concentrated, so the application should be cleaner.
Most of what is in this playbook is not new technology. RFC 8288 has been around since 2017. RFC 9264 since 2022. RFC 9727 since 2025. Schema.org since 2011. APIs.json since 2014. What is new is treating them as a coherent stack — the catalog is the index, the linkset is the format, the Worker is the edge, the markdown is the alternate representation, the skill is the manual, the JSON-LD is the vocabulary, the robots.txt is the consent. Stack them together and a network of static Jekyll sites starts feeling like a single agent-readable surface.