Maryam Ashoori, Head of Product for watsonx.ai at IBM, joins Ryan and Eira to talk about the complexity of enterprise AI, the role of governance, the AI skill gap among developers, how AI coding tools impact developer productivity, what chain-of-thought reasoning entails, and what observability and monitoring look like for AI.

|
Sr. Content Developer at Microsoft, working remotely in PA, TechBash conference organizer, former Microsoft MVP, Husband, Dad and Geek.
|

Pennsylvania, USA

Introduction: The Era of AI Agents in JavaScript
During the AI Agents Hackathon, one of the most anticipated sessions was presented by Wassim Chegham, Senior AI Developer Advocate for JavaScript at Microsoft. The topic? "How to Create Your First AI Agent with JavaScript and Azure AI Agent Service" — a powerful tool designed for modern developers looking to build AI-first applications with security, scalability, and productivity in mind.
In this article, we explore the main highlights of the session, focusing on how you can create your own AI agent using JavaScript and Azure AI Agent Service.
The video’s goal is clear: walk through the step-by-step process of creating AI agents using JavaScript and TypeScript with Azure AI Foundry, and explain all the key concepts behind this new development paradigm.
If you missed the session, don’t worry! You can watch the recording:
What Are AI Agents?
Wassim starts the session with a historical overview: from traditional chatbots to the intelligent and autonomous agents we know today. He highlights:
- LLM-based Agents (Large Language Models) that understand natural language.
- Tool-using Agents that perform real-world tasks like API calls, searches, code execution, etc.
- Multi-agent Systems, coordinating multiple agents to solve complex problems.
The main advantage of Azure AI Agent Service is how it simplifies all of this by offering a managed platform that handles orchestration, security, tracking, and agent execution.
Solution Architecture with Azure AI Agent Service
During the session, Wassim provided a clear view of a typical AI agent app architecture built with JavaScript. He explained that while you can use a graphical interface (Frontend) with frameworks like Angular or React, it’s not mandatory — the app can work just fine from a terminal, as demonstrated live.
In the Backend, the focus is on using Node.js, often combined with frameworks like Express.js or Fastify to expose APIs that communicate with agents. This API layer acts as a bridge between users and the agent’s logic, coordinating messages, executions, and tool invocations.
The agent itself is created and managed using the azure/ai-projects SDK, which provides a simple API to register agents, define instructions, attach tools, and control executions. Wassim emphasized how this approach reduces complexity compared to other agent frameworks that require manual state configuration, orchestration, and context management.
Additionally, there is a layer of integrated tools that greatly expand the agent's capabilities:
- Code Interpreter: sandboxed Python code execution
- Function Calling: user-defined function invocation
- Azure AI Search: vector search and RAG (Retrieval-Augmented Generation)
- Bing Search: real-time web data grounding
All these tools are available plug-and-play through the Azure AI Agent Service infrastructure.
This architecture is powered by an Azure AI Foundry instance, which centralizes control over models, tools, connections, and data, providing a robust, secure, and scalable base for AI-first applications. Wassim made it clear: the agent is the true "brain" of the application — receiving instructions, reasoning over them, and coordinating task execution with external tools, all with just a few JavaScript commands.
Creating Your First Agent: Hands-on with JavaScript
During the hands-on demo, Wassim walks participants through every step to create a working AI agent using JavaScript and Azure AI Agent Service. He begins by highlighting that all code is publicly available in a GitHub repository, so anyone can clone, run, and adapt it.
> Repository link: Azure AI Agent Service - Demonstration
The first step is installing the required packages. The core one is the azure/ai-projects SDK (npm package), which handles agent interactions. You’ll also need azure/identity to securely authenticate with Azure credentials using, for example, DefaultAzureCredential.
Once the environment is set up, Wassim shows how to create an authenticated client using a connection string from the Azure Foundry portal. This string is stored in a .env file and allows secure communication with the agent service.
With the client ready, the next step is to create the agent. You define its name, the language model (like GPT-4), and clear instructions about what the agent should do — whether it’s calculating, answering questions, interpreting data, or interacting with external tools.
Wassim then introduces the thread concept, which acts as a conversation space between the agent and user. This is where messages are stored, executions are initiated, and interaction history is tracked. He shows how to create a thread, send a message, and launch a run, or agent execution.
The session then showcases tool usage. In the first example, the agent solves a simple equation using its internal knowledge — a classic case demonstrating reasoning capabilities based on instructions. Next, Wassim activates a custom function call: the agent fetches local CPU usage, demonstrating environment interaction.
Another impressive example is using the Code Interpreter tool to run Python code remotely. Wassim uploads a CSV with car sales data, and the agent processes the data and generates charts in real-time.
He also demonstrates using Bing Grounding to fetch up-to-date info from the internet (e.g., stock prices). Finally, he shows how Azure AI Search queries a vector index with healthcare plan data to answer specific questions — with precise source citations. A great RAG (Retrieval-Augmented Generation) example.
These examples prove that with just a few JavaScript commands, you can build powerful agents capable of interacting with users, data, and tools seamlessly and securely.
Understanding the Inner Workings: How an Agent Works
Wassim explains the key concepts in an agent's lifecycle:
- Agent: configured with model and instructions.
- Thread: represents conversation (context).
- Run: task execution.
- Run Steps: steps in the execution.
- Tools: defined via schema and triggered as needed.
- Events: emitted during execution (streaming, tool-call, response, error, etc).
He also showcases a personal project: a visual tracing tool to track agent steps in real-time — helpful for understanding and debugging.
A Bit About the Technologies Used
For the tech-curious, Wassim highlighted the stack powering the project:
- 📦 SDKs
- 🔧 Integrated tools
- Function Calling: run functions based on LLM input.
- Code Interpreter: safely run Python remotely.
- Azure AI Search: vector and full-text search (RAG).
- Bing Search Grounding: real-time web info.
- File Search (coming soon): search uploaded files.
- ⚙️ Security & Compliance
- Keyless authentication
- Private Networking (VNet)
- Content Filtering
- Tracing/logging to prevent hallucinations
Conclusion: The Future of AI Agents with JavaScript
Wassim Chegham's session at the AI Agents Hackathon was a masterclass in how to create AI agents using JavaScript and Azure AI Agent Service. He not only introduced the core concepts, but demonstrated how quick and easy it is to develop intelligent apps with this new approach.
Again, if you missed the session, you can watch the full recording here.
And don’t forget to check out the GitHub repo with all the examples and code used in the session: Azure AI Agent Service - Demonstration.
Wassim’s closing message was clear: the future of AI agents is bright. With the right tools, any developer can build impactful and innovative solutions. So don’t wait — start building your AI agent with Azure today!
Useful Links
- Azure AI Agent Service: Official docs for Azure AI Agent Service.
- Azure AI Foundry: Platform for creating and managing AI agents.
- Azure AI Agent Service - Demo: GitHub repo with session code and examples.
- AI Agents Hackathon: Event gathering developers to explore AI agent potential.
- Wassim Chegham: LinkedIn profile of the session speaker.
- Azure AI Foundry - Getting Started: Quickstart guide for Azure Foundry.
- Agent Service Quickstart: Get started with your first agent.
- Agent Service Tools: Learn about tools available in the Agent Service.
- Function Calling Docs
- Code Interpreter Docs
Pennsylvania, USA
Introduction
Have you ever thought about to build a Visual Studio Code extension as your capstone project? That’s what I did: Part 1 - Develop a VS Code Extension for Your Capstone Project.
I have created a Visual Studio Code Extension, API Guardian, that identifies API endpoints in a project and checks their functionality before deployment. This solution was developed to help developers save time spent fixing issues caused by breaking or non-breaking changes and to alleviate the difficulties in performing maintenance due to unclear or outdated documentation.
Let's build your very own extension!
Now, let’s do it step by step.
Step 1 – Install the NPM package for generator-code
Ensure Node.js is installed before proceeding. Verify by running node -v, which will display the installed version.
Once Node.js is verified to be installed, run the following command to install the generator-code, “npm install -g yo generator code”
After installation is complete, run this command, “yo code”, in your desired folder to create the project. For this tutorial, I will choose to create a new extension using JavaScript.
You can then fill in the relevant information.
Once completed your project has been created.
Step 2 – Customize Command
To customize your command, open "package.json" and modify the relevant text.
Keep in mind that if you change the “Command” in "package.json", you'll also need to update it in "extension.js".
Step 3 – Adding the logic for your extension
In this section of the tutorial, we will explore and utilize the Quick Pick functionality offered by the Visual Studio Code API. This feature allows us to create interactive menus that let users quickly select from a list of options, streamlining their workflow within the extension. I’ve provided a code snippet as an example: if users select "Say Hello", a "Hello World" message will be displayed, and if they choose "Say Goodbye", a "Goodbye!" message will appear.
Step 4 – Testing the Extension
To test your extension, go to the Run menu and select Start Debugging. This will open a new instance of VS Code, called the Extension Development Host, where you can test your extension.
In the Command Palette of the development host go to Show and Run Command, type the name of your custom command, such as "Say Hello," and select it.
This triggers the extension to run according to the logic in your extension.js file, allowing you to interact with and debug its functionality.
Summary
Congratulations! You've just created your first Visual Studio Code extension. Building your extension for your capstone project can be challenging, as you’ll encounter various obstacles while ensuring everything works as expected. Not only does this strengthen your technical skills, but it also enhances key soft skills such as problem-solving, critical thinking, collaboration, and time management. Overcoming these challenges builds resilience and adaptability, preparing you for real-world software engineering roles and professional teamwork.
Acknowledgement
I would like to express my sincere gratitude to Dr. Peter Yau and Mr. Francis Teo for their invaluable guidance and support throughout this project. I would also like to extend my appreciation to the Singapore Institute of Technology, University of Glasgow, and Wizvision Pte Ltd for their ongoing support and for providing me with the opportunity to work on this project.
API Guardian
https://marketplace.visualstudio.com/items?itemName=APIGuardian-vsc.api
About the Authors
Main Author - Ms Joy Cheng Yee Shing, BSc (Hon) Computing Science
Academic Supervisor - Dr Peter Yau, Microsoft MVP
Pennsylvania, USA
1081. Is an epitome a summary or a shining example? We look at why this word trips people up and how its meaning has changed over time. Then, we take a linguistic safari through the world of baby animal names—and what they tell us about language, culture, and human history.
The "baby animal names" segment is by Karen Lunde, a career writer and editor. In the late '90s, as a young mom with two kids and a dog, she founded one of the internet's first writing workshop communities. These days, she facilitates expressive writing workshops, both online and off. Find her at chanterellestorystudio.com
🔗 Grammar Girl AP style webinar (use the code MACMIL for $50 off).
🔗 Share your familect recording in a WhatsApp chat.
🔗 Watch my LinkedIn Learning writing courses.
🔗 Subscribe to the newsletter.
🔗 Take our advertising survey.
🔗 Get the edited transcript.
🔗 Get Grammar Girl books.
🔗 Join Grammarpalooza. Get ad-free and bonus episodes at Apple Podcasts or Subtext. Learn more about the difference.
| HOST: Mignon Fogarty
| VOICEMAIL: 833-214-GIRL (833-214-4475).
| Grammar Girl is part of the Quick and Dirty Tips podcast network.
- Audio Engineer: Dan Feierabend
- Director of Podcast: Brannan Goetschius
- Advertising Operations Specialist: Morgan Christianson
- Digital Operations Specialist: Holly Hutchings
- Marketing and Video: Nat Hoopes
| Theme music by Catherine Rannus.
| Grammar Girl Social Media: YouTube. TikTok. Facebook.Threads. Instagram. LinkedIn. Mastodon. Bluesky.
Download audio: https://dts.podtrac.com/redirect.mp3/tracking.swap.fm/track/0bDcdoop59bdTYSfajQW/media.blubrry.com/grammargirl/stitcher.simplecastaudio.com/e7b2fc84-d82d-4b4d-980c-6414facd80c3/episodes/e22de58b-9c58-426b-9b57-6bff2906cea6/audio/128/default.mp3?aid=rss_feed&awCollectionId=e7b2fc84-d82d-4b4d-980c-6414facd80c3&awEpisodeId=e22de58b-9c58-426b-9b57-6bff2906cea6&feed=XcH2p3Ah
Pennsylvania, USA
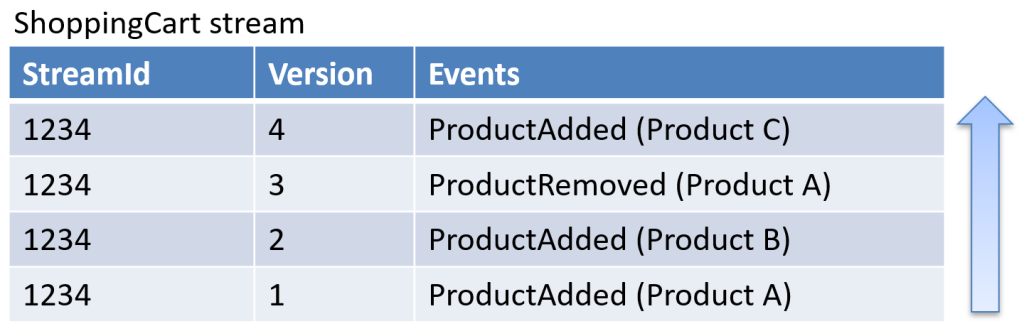

Pennsylvania, USA
This blog post is originally published on https://blog.elmah.io/soft-deletes-in-ef-core-how-to-implement-and-query-efficiently/
What does your application actually do with a record when a user deletes it? Can your application afford to delete a record permanently? One mistake can result in irreparable damage to the application. Today, I will shed light on D of the CRUD. Among all the CRUD operations, Delete is the most critical. Removing a record using a database delete is a simple way, but it does not provide a rollback option. In many cases, you don't want a cascading chain of deletes, which cannot be recovered. Soft delete is a common practice for such scenarios, where the record is flagged as deleted, allowing you to rollback using the same flag.

What is a soft delete?
Soft delete is a data persistence strategy that provides a secure way to manage data without permanently removing it. Instead of deleting records, the system marks them as inactive by toggling a deletion flag. Soft delete ensures that sensitive or critical data can remain available for restoration, auditing, or historical reference. A hard delete can result in cascade deletion, losing essential relations or associated data.
Traditionally, a hard delete performs the following:
DELETE FROM [dbo].[Book]
WHERE [Book].[Id] = 02;
Our rescuer soft delete does
UPDATE [dbo].[Book]
SET [dbo].[Book].[IsDeleted] = 1
WHERE [Book].[Id] = 02;
It is like telling your database, "Hide this record, but don't actually delete it.' to fetch records filtered by the IsDeleted flag.
SELECT *
FROM [Book]
WHERE IsDeleted = 0;
We have seen the introduction of the soft delete, but now our purpose was to know "How to implement soft delete efficiently?"
Way 1: Simplest - Manual Flagging
Step 1: Define the model
public class Book
{
public int Id { get; set; }
public string Name { get; set; }
public string IBN { get; set; }
public int PageCount { get; set; }
// Setting the flag false by default for any new record
public bool IsDeleted { get; set; } = false;
}
Step 2: Configure ApplicationDbContext
public class ApplicationDbContext: DbContext
{
public DbSet<Book> Books { get; set; }
public ApplicationDbContext(DbContextOptions<ApplicationDbContext> options) : base(options)
{
}
}
Step 3: Implement the Remove method
public async Task RemoveBookAsync(int id)
{
var book = await context.Books.FirstOrDefaultAsync(id);
book.IsDeleted = true;
await context.SaveChangesAsync();
}
Step 4: Filter in the get methods
public async Task GetBooksAsync () =>
await context.Books.Where(b => !b.IsDeleted).ToListAsync();
Manual flagging is the most straightforward way to handle deletion softly. However, if the application grows larger, managing IsDeleted for each model becomes troublesome.
Way 2: Global Query Filter
Defining common properties in a base model is a cleaner and OOP-based approach. To avoid repetitive code, you can define the IsDeleted property in such a model and inherit it across other classes.
Step 1: Declare the base model
public abstract class SoftDeletableModel
{
public bool IsDeleted { get; set; } = false;
public DateTime? DeletedAt { get; set; }
}
We added DeletedAt to record the time of deletion.
Step 2: Create Book model as an inherited class
public class Book: SoftDeletableModel
{
public int Id { get; set; }
public string Name { get; set; }
public string IBN { get; set; }
public int PageCount { get; set; }
}
Step 3: Configure ApplicationDbContext
public class ApplicationDbContext: DbContext
{
public DbSet<Book> Books { get; set; }
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Entity<Book>().HasQueryFilter(b => !b.IsDeleted);
}
}
Here, we applied a filter in the DbContext itself, so it will filter book records while fetching.
Step 4: Implement the Remove method
public async Task RemoveBookAsync(int id)
{
var book = await context.Books.FirstOrDefaultAsync(id);
book.IsDeleted = true;
book.DeletedAt = DateTime.UtcNow();
await context.SaveChangesAsync();
}
The remove method remains the same.
Step 5: Filter in the get methods
public async Task GetBooksAsync () => await context.Books.ToListAsync();
No explicit filter required.
By configuring the IsDeleted filter, all the book records will be filtered out during fetching. However, if you need to skip the filter for complex joins, you can use IgnoreQueryFilters() like:
await context.Books.IgnoreQueryFilters().ToList();
Way 3: SaveChanges Override to Intercept Deletes
Now we are moving one step ahead, we will change the SaveChangesAsync default behavior for this purpose.
Step 1: Declare the base model
public abstract class SoftDeletableModel
{
public bool IsDeleted { get; set; } = false;
public DateTime? DeletedAt { get; set; }
}
We added DeletedAt to record the time of deletion.
Step 2: Create Book model as an inherited class
public class Book: SoftDeletableModel
{
public int Id { get; set; }
public string Name { get; set; }
public string IBN { get; set; }
public int PageCount { get; set; }
}
Step 3: Configure ApplicationDbContext soft delete via SaveChanges interception
public class ApplicationDbContext: DbContext
{
public DbSet<Book> Books { get; set; }
public ApplicationDbContext(DbContextOptions<ApplicationDbContext> options) : base(options)
{
}
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Entity<Book>().HasQueryFilter(b => !b.IsDeleted);
base.OnModelCreating(modelBuilder);
}
public override int SaveChanges()
{
foreach (var entry in ChangeTracker
.Entries()
.Where(e => e.State == EntityState.Deleted && e.Entity is SoftDeletableEntity))
{
entry.State = EntityState.Modified;
((SoftDeletableEntity)entry.Entity).IsDeleted = true;
((SoftDeletableEntity)entry.Entity).DeletedAt = DateTime.UtcNow;
}
return base.SaveChanges();
}
public override async Task<int> SaveChangesAsync(CancellationToken cancellationToken = default)
{
foreach (var entry in ChangeTracker
.Entries()
.Where(e => e.State == EntityState.Deleted && e.Entity is SoftDeletableEntity))
{
entry.State = EntityState.Modified;
((SoftDeletableEntity)entry.Entity).IsDeleted = true;
((SoftDeletableEntity)entry.Entity).DeletedAt = DateTime.UtcNow;
}
return await base.SaveChangesAsync(cancellationToken);
}
}
Here we applied a filter in the DbContext itself, hence it will filter book records while fetching.
You can also define a separate interceptor and register it. The DbContext code becomes:
public class ApplicationDbContext: DbContext
{
public DbSet<Book> Books { get; set; }
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Entity<Book>().HasQueryFilter(b => !b.IsDeleted);
base.OnModelCreating(modelBuilder);
}
}
And define a separate inceptor.
public sealed class SoftDeleteInterceptor: SaveChangesInterceptor
{
public override ValueTask<InterceptionResult<int>> SavingChangesAsync(
DbContextEventData eventData,
InterceptionResult<int> result,
CancellationToken cancellationToken = default)
{
if (eventData.Context is null)
return base.SavingChangesAsync(eventData, result, cancellationToken);
var entries = eventData.Context.ChangeTracker
.Entries<ISoftDeletable>()
.Where(e => e.State == EntityState.Deleted);
foreach (var entry in entries)
{
entry.State = EntityState.Modified;
entry.Entity.IsDeleted = true;
entry.Entity.DeletedAt = DateTime.UtcNow;
}
return base.SavingChangesAsync(eventData, result, cancellationToken);
}
}
Register it in the services
services.AddSingleton<SoftDeleteInterceptor>();
services.AddDbContext<ApplicationDbContext>((sp, options) =>
options.UseSqlServer(configuration.GetConnectionString("DefaultConnection"))
.AddInterceptors(sp.GetRequiredService<SoftDeleteInterceptor>()));
Step 4: Implement the Remove method
public async Task RemoveBookAsync(int id)
{
// Soft delete via the Remove method
var book = await context.Books.FindAsync(1);
context.Books.Remove(book); // ← Intercepted by SaveChanges
await context.SaveChangesAsync();
}
Remove() acts as a soft delete.
Step 5: Filter in the get methods
public async Task GetBooksAsync () => await context.Books.ToListAsync();
Here, you don't need to use Update logic in the RemoveBookAsync method.
Way 4: With Repository Pattern
The repository pattern will utilize a generic type to implement soft deletion in the Remove method. The first two steps are the same as Way 2
Step 3: Define ApplicationDbContext
public class ApplicationDbContext: DbContext
{
public DbSet<Book> Books { get; set; }
public ApplicationDbContext(DbContextOptions<ApplicationDbContext> options) : base(options)
{
}
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Entity<Book>().HasQueryFilter(b => !b.IsDeleted);
base.OnModelCreating(modelBuilder);
}
}
Step 4: Define a generic repository
public class Repository<T> where T : SoftDeletableModel
{
private readonly ApplicationDbContext _context;
public Repository(ApplicationDbContext context) => _context = context;
public async Task RemoveAsync(int id)
{
var entity = await _context.Set<T>().FindAsync(id);
if (entity != null)
{
entity.IsDeleted = true;
entity.DeletedOnUtc = DateTime.UtcNow;
await _context.SaveChangesAsync();
}
}
public IQueryable<T> GetAll() => _context.Set<T>();
}
Step 5: Use the code
To Remove:
var repo = new Repository<Book>(context);
await repo.RemoveAsync(1);
To Get:
var books = await repo.GetAll().ToListAsync();
Conclusion
Traditional hard delete methods can be problematic in many ways. They permanently erase data from the database, and you cannot roll back that data. Such operations are expensive if your application is prone to mistakes and becomes troublesome when cascade deleting occurs. Additionally, many law enforcement bodies have established data retention and disposal procedures, and deleting data permanently could result in penalties for non-compliance. A soft delete strategy that deletes records logically by setting a flag on the record, indicating it as "deleted." It maintains the foreign key integrity and ensures the consistency of other associated documents. This approach allows the application to ignore these records during regular queries. However, you can restore these records if necessary. We discussed some standard methods for implementing soft deletion in EF Core.

Pennsylvania, USA
Next Page of Stories