Microsoft is on a mission to fix Windows 11, and part of that involves improving the often-frustrating Windows Update experience. While you'll soon be able to pause updates indefinitely, Microsoft is also adding a new feature that automatically rolls back problematic drivers that have been installed through Windows Update.
Microsoft has created a new "Cloud-Initiated Driver Recovery" feature that can replace a faulty driver installed on a PC with a previously working driver through Windows Update. Right now, Windows 11 users have to manually roll back a driver or hardware vendors have to publish a new one to work around any problems, but th …
1185. Today, we look at why English spelling is secretly optimized for readers. Colin Gorrie, linguist and creator of the Dead Language Society newsletter, shared the real history of silent letters, why medieval scribes weren't bothered by inconsistent spelling, and how the printing press and social ambition drove standardization. We also look at the surprisingly dramatic origin of "went" — a past tense stolen from an entirely different verb.
If you've heard that your job in the agentic coding era is to "become a manager of agents," you may have noticed something doesn't quite fit. Most of us never trained to be managers, and frankly, that's not the role most engineers want. In today's episode, I unpack what that shift _actually_ means — it's closer to a tech lead or architect mindset — and zoom in on a specific interviewing and on-the-job skill that will help you stay employable: how you think about, talk about, and take ownership of failure.
Don't Just Bring Star Stories — Bring Failure Stories: Interviewers don't only want to hear how you succeeded. They want to know what you do when the pressure's on and things fall apart. If every story you tell is a highlight reel, there's a built-in social signal that you're hiding something. Get comfortable telling the other kind of story.
Identify the Real Problem, Not the Proximal One: The most common failure story I hear in interviews is "the knowledge transfer was bad" or "the docs weren't good." That's not wrong — it's just incomplete. The senior mindset asks why that happened. Why didn't we have docs? Why was context insufficient? Walk it back until you hit something actionable but not too abstract.
The Systemic Diagnosis is the Leveled-Up Answer: Fixing the proximal cause fixes this instance. Fixing the root cause fixes the system that keeps producing instances like this. When you connect what you learned to a systemic adjustment, you stop sounding like someone who survived a bad project and start sounding like someone who improves the organization around them.
Ownership Means Owning the Outcome, Not the Task: Use the homeowner metaphor. A homeowner doesn't personally fix every leaking pipe — but the outcome of the home is theirs. As an engineer, your scope of ownership has expanded dramatically in the agentic era. You're now responsible for outcomes of code you may not have even read, and the deciding skill is how you carry that responsibility.
The Word to Pair With Ownership is Relentlessness: Not in an anxious, burn-yourself-out way. Relentlessness means following a thread to its natural end — through escalation, through asking the next question, through finding the right person if it's not you. It's the antidote to "I'll let someone else handle it" syndrome.
You Don't Have to Do It All Yourself: Relentless ownership is not "carry every task across the finish line personally." If you're not qualified, the owner's job is to find who is, communicate risk to stakeholders, and keep the trail alive until the outcome is resolved. That's the differentiator between a senior thinking engineer and a junior one working through assigned tickets.
Failure Is Usually a Lapse in Ownership: If you make a list of five things you've failed at (and you should), you'll often find the through-line isn't lack of skill — it's that you stopped escalating, stopped following up, stopped staying with the thing until it was actually resolved.
Episode Homework: Write down five real failures. For each one, ask: where did I stop being relentless? What system produced this outcome — and what would I change upstream next time?
No matter what you're building, SerpApi is the web search API for your needs. If you're building an application that needs real-time search data—whether that's an AI agent, an SEO tool, or a price tracker—SerpApi handles it for you. ● Make an API call and get back clean JSON. ● They handle the proxies, CAPTCHAs, parsing, and all the scraping so you don't have to. ● They support dozens of search engines and platforms, and are trusted by companies like NVIDIA, Adobe, and Shopify. ● If you're building with AI, they even have an official MCP to make getting up and running a simple task. Get started with a free tier to build and test your application before you commit. Go to serpapi.com.
📮 Ask a Question
If you enjoyed this episode and would like me to discuss a question that you have on the show, drop it over at: developertea.com.
If you want to be a part of a supportive community of engineers (non-engineers welcome!) working to improve their lives and careers, join us on the Developer Tea Discord community today!
🗞️ Subscribe to The Tea Break
We are developing a brand new newsletter called The Tea Break! You can be the first in line to receive it by entering your email directly over at developertea.com.
🧡 Leave a Review
If you're enjoying the show and want to support the content head over to iTunes and leave a review!
Azure App Service (Linux) is a fully managed PaaS offering that supports a broad range of languages, including Python, Node.js, .NET, PHP, and Java. Developers can push source code or deploy a pre-built artifact; the platform handles the rest, including dependency installation, application containerization, and running the application at cloud scale.
More customers are building intelligent applications using Azure AI Foundry and other AI services, and Python has become a language of choice for these workloads. The performance and reliability of the Python deployment pipeline directly shape the developer's experience on the platform, so we looked across the deployment path for opportunities to reduce latency and improve reliability. The first set of changes has reduced Python deployment latency on Azure App Service Linux by approximately 30%. This is the first step in a broader effort to make the platform better suited for AI application development, but the gains resulting from this effort will benefit all apps on the platform. Let's look at the details.
Where Deployment Time Was Going
Python web application deployments on Azure App Service Linux rely on Oryx, the platform's open-source build system, to produce runnable artifacts during remote builds. Platform telemetry showed that around 70% of Python app deployments use remote builds, and the majority of those resolve dependencies via requirements.txt using pip install.
To understand where time was going, we profiled a stress workload: a 7.5 GB PyTorch application. Most production builds are smaller, but stress-testing a dependency-heavy application made the pipeline bottlenecks clear.
When a Python app is deployed via remote build, the build container in Kudu (the App Service deployment service) runs Oryx to:
Extractthe uploaded source code.
Createa Python virtual environment.
Install dependencies via pip install; 4.35 min (~34% of build time).
Copy files to a staging directory; 0.98 min (~8%).
Compress via tar + gzip into an archive; 7.53 min (~58%).
Writethe archive to /home (Azure Storage SMB mount).
The app container then extracts this archive to the local disk on every cold start.
Why the Archive-Based Approach?
The /home directory is backed by an Azure Storage SMB mount, where small-file I/O is comparatively expensive. Python dependencies are file-heavy: virtual environments commonly contain tens of thousands of files, and dependency-heavy ML applications can exceed 200,000 files. Writing those files individually over SMB would be prohibitively slow. Instead, the pipeline builds on the container's local filesystem, writes a single compressed archive over SMB, and the app container extracts it locally on startup for efficient module loading.
Key insight: Compression was the single largest phase at 58% of build time, longer than installing the packages themselves.
What We Changed
Zstandard Compression (Replacing gzip)
Standard gzip compression is single-threaded. In our benchmark, compression accounted for 58% of total build time, making it the dominant bottleneck. Because the archive is also decompressed during container startup, decompression time affects runtime startup latency as well.
We evaluated three compression algorithms: gzip, LZ4, and Zstandard (zstd). The following results are averaged across multiple deployments of a 7.5 GB Python application with PyTorch and additional ML packages:
Metric
gzip
LZ4
zstd
Compression time
7.53 min
1.20 min
1.18 min
Decompression time
2.80 min
1.18 min
1.07 min
Archive size
4.0 GB
5.0 GB
4.8 GB
Both zstd and LZ4 were more than 6× faster than gzip for compression and more than 2× faster for decompression. We selected zstd for the following reasons:
Comparable speed to LZ4, with smaller archive sizes (4.8 GB vs. 5.0 GB).
Mature ecosystem:zstdis based onRFC 8878published in 2021and ships with many common Linux distributions.
Native tar support:tar –I zstdworks out of the box; no extra packages required.
Result:Compression time dropped from 7.53 min → 1.18 min(6.4× faster). Decompression improved from 2.80 min → 1.07 min(2.6× faster), directly reducing cold-start latency.
Faster Package Installation with uv
pipis implemented in Python and has historically optimized compatibility over maximum parallelism. In dependency-heavy workloads, package download, resolution, and installation can become a major part of deployment time. In our 7.5 GB PyTorch benchmark, package installation accounted for ~34% of total build time (4.35 min out of 12.86 min).
We introduced uv, a Python package manager written in Rust, as the primary installer for compatible requirements.txt deployments. Its uv pip install interface works with standard pip workflows.
Fallback strategy: Compatibility remains the priority. When uv cannot handle a deployment, the platform retries with pip, preserving the behavior customers already depend on.
Cache behavior:Package caches remain local to the build container. When the same app is deployed again before the kudu (build) container is recycled, both pip and uv can reuse cached packages and avoid repeated downloads.
Result: Package installation time dropped from 4.35 min → 1.50 min (3× faster).
Reducing File Copy Overhead
A file copy showed up in two places. First, before compression, the build process copied the entire build directory (application code plus Python packages) to a staging location. This existed historically as a safety measure; creating a clean snapshot before tar reads the file tree. But the cost was steep for the large number of files inherent in Python dependencies.
The fix was straightforward: create the tar archive directly from the build directory, skipping the intermediate copy entirely.
Second, for pre-built deployment scenarios, we replaced the legacy Kudu sync path with Linux-native rsync. That gave us a better optimized tool for large Linux file trees and reduced the overhead of moving files into the final deployment location. Because this path is used beyond Python, the improvement benefits pre-built apps across the broader App Service Linux ecosystem.
Result: Eliminated the 0.98-minute staging copy (8% of build time), reduced temporary disk usage, and improved the remaining file sync path.
Pre-Built Python Wheels Cache
We added a complementary optimization: a read-only cache of pre-built wheels for commonly used Python packages, selected using platform telemetry. The cache is mounted into the Kudu build container at runtime for Python workloads, allowing the installer to use local wheel artifacts before downloading packages externally.
When a matching wheel is available, the installer uses it directly, avoiding a network fetch for that package. Cache misses fall back to the upstream registry (e.g., PyPI) as usual.
The cache is managed by the platform and kept up to date, so supported Python builds can use it without any app change.
Combined Results
Controlled Benchmark (PyTorch 7.5 GB, P1mv3 App Service Tier)
The following benchmark was measured on the P1mv3 App Service tier. Values in the "After" column reflect the optimized pipeline with zstd compression, uv package installation, direct tar creation, and the pre-built wheels cache enabled together.
Phase
Before
After
Improvement
Package installation
4.35 min
1.50 min
~3× faster
File copy
0.98 min
0 min
Eliminated
Compression
7.53 min
1.18 min
~6× faster
Total build time
12.86 min
~2.68 min
~79% reduction
Production Fleet (All Python Linux Web Apps)
Production telemetry across Python deployments shows the impact of these changes: deployment latency decreased by approximately 30% after the rollout.
The controlled benchmark shows a larger improvement (~79%) because it exercises a dependency-heavy workload where package installation, file copy, and compression dominate total build time. Typical production apps are smaller and spend less time proportionally in those phases.
Beyond Faster Builds: Reliability and Runtime Performance
Faster builds only help when deployment requests reliably reach a worker that is ready to build. We updated the primary deployment clients Azure CLI, GitHub Actions, and Azure DevOps Pipelines to warm up Kudu before initiating deployments. Clients now issue a lightweight health-check request to the Kudu endpoint, helping ensure the deployment container is running and ready before the deployment begins.
Clients also preserve affinity to the warmed-up worker using the ARR affinity cookie returned by the first request. This increases the chance that the deployment uses a worker with Kudu already running and local package caches already available from recent deployments.
Together, these client-side changes reduced deployment failures from transient infrastructure issues and helped the pipeline optimizations reach the build phase reliably.
Result: Deployment failures caused by cold-start errors (502, 503, 499) dropped by ~30%.
We also improved the default runtime configuration for Python apps using the platform-provided Gunicorn startup path. Previously, the platform defaulted to a single worker, leaving most CPU cores idle. Now, it follows Gunicorn's recommended worker formula, fully utilizing available cores on multi-core SKUs and delivering higher request throughput out of the box.
workers = (2 × NUM_CORES) + 1
Key Takeaways
Measure before optimizing: Platform telemetry showed that remote builds and requirements.txt based installs were the dominant Python deployment paths, which helped us focus on changes that would benefit the most customers.
Compression was the biggest bottleneck: In the dependency-heavy benchmark, archive compression took longer than package installation. Replacing gzip with zstdreduced both build time and cold-start extraction time.
File count matters: Python virtual environments can contain tens of thousands of files, and AI workloads can contain many more. Reducing unnecessary file copies and using Linux-native file sync helped lower overhead.
Compatibility needs a fallback path: Introducing uv improved the common path, while falling back to pip preserved compatibility for apps that depend on existing Python packaging behavior.
Deployment reliability is part of performance: Faster builds only help if deployment requests consistently reach a ready worker. Warm-up and worker affinity made the optimized path more reliable for customers.
Beyond deployment:Runtime defaults, such as Gunicorn worker configuration, also affect how production apps perform once deployment is complete.
Together, these changes made Python deployments faster and more reliable while preserving compatibility through safe fallbacks. We will continue improving the platform to make Azure App Service faster, more reliable, and better suited for AI application development.
Quantum computers capable of breaking RSA and elliptic-curve cryptography don't exist yet, but the threat is real enough that NIST finalized three post-quantum cryptography (PQC) standards in 2024: FIPS 203 (ML-KEM), FIPS 204 (ML-DSA), and FIPS 205 (SLH-DSA). The concern isn't just future decryption. "Harvest now, decrypt later" attacks mean that encrypted data captured today could be broken once quantum hardware catches up.
.NET 10 ships first-class support for all three FIPS-standardized PQC algorithms, plus a hybrid approach called Composite ML-DSA that combines classical and post-quantum signatures. No hand-waving. Let's write code.
TLDR; GenAI is a powerful new instrument, but it doesn't exempt you from the engineering disciplines that have always separated successful technology projects from expensive disappointments. Based on our experience helping organisations navigate enterprise-scale GenAI adoption, we've distilled seven principles that consistently separate the projects that deliver value from those that generate noise.
Whether you're a CTO embarking on your first enterprise AI initiative or an engineering lead wondering why your pilot isn't scaling, we hope our experiences which are distilled in this blog will help you on the path to success.
Adoption of Generative AI (GenAI) is like introducing a powerful new instrument to an orchestra.
Yes, GenAI creates possibilities that didn't exist before. But it still requires musicians who have mastered playing and can read music, a conductor with a vision, rehearsal time, and the discipline to play together as a team. An orchestra that lacks these fundamentals won't be saved by a new instrument, they'll just make new kinds of noise.
The learnings have been distilled into seven principles for GenAI success. Each is framed as a contrast pair — a choice between the approach that leads to success and the approach that leads to expensive disappointment.
These principles will feel familiar — because they're the same disciplines that have always separated successful technology projects from expensive disappointments.
Goal-driven, not technology-led
The latest GenAI foundation models are genuinely remarkable. But remarkable technology has a gravitational pull that can divert attention away from the most important question: why does this matter to the organisation?
GenAI initiatives which cannot answer this question tend to become "solutions looking for a problem." They attract feature requests from stakeholders who see this as their one chance to secure budget for anything GenAI-related. They drift, lose focus, and eventually collapse under the weight of expectations. All of the hard graft goes unrecognised and morale suffers.
Successful GenAI initiatives look different. They start with a clear and compelling business goal that existed before anyone mentioned GenAI. The technology serves that goal, not the other way around. The discipline of choosing those goals well is the subject of a companion piece: AI Strategy: Think Top-Down, Experiment Bottom-Up.
One practical step: avoid labelling the project as an "AI project" at all. Frame it as a business initiative that happens to use GenAI. In doing so, you will give the initiative a clear purpose and keep the focus where it belongs.
Transformational, not incremental
The trap is to apply GenAI to existing processes for incremental gains, rather than re-imagining how the process itself could be transformed. Bolting AI onto an unchanged workflow rarely generates significant impact; the value comes from rethinking how the work gets done. McKinsey identifies this as the single strongest predictor of value, yet very few organisations commit to it.
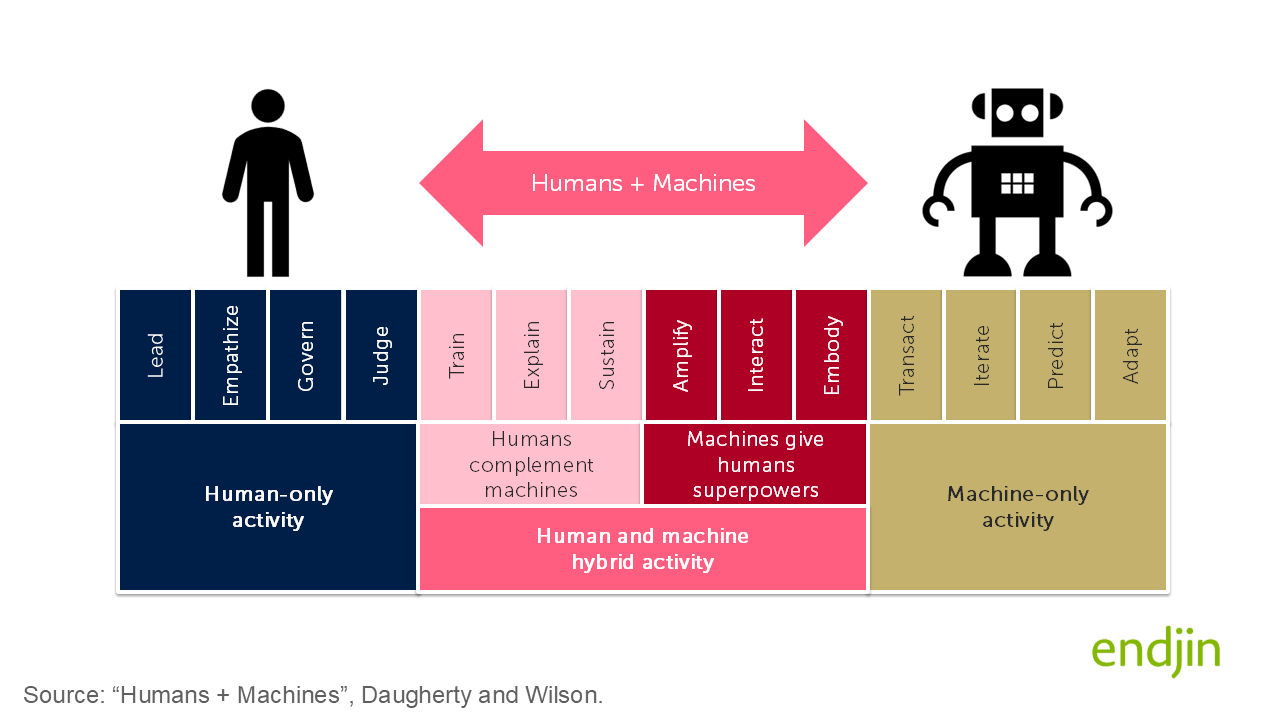
In their book Human + Machine: Reimagining Work in the Age of AI Paul Daugherty and H. James Wilson argue that the central opportunity of AI is not the automation or replacement of human work, but the design of new ways for humans and machines to collaborate. The authors describe a "missing middle": the space where humans and AI work together, with humans amplifying machines (training, explaining, sustaining their behaviour) and machines amplifying humans (by extending their cognitive, analytic and physical capabilities). Their core contention is that the firms unlocking the greatest value from AI are those that have explicitly reimagined business processes around this collaboration rather than bolting AI onto existing workflows.
The true total cost of ownership (TCO) extends far beyond licenses and token consumption: you will still need people to build it, evaluate it, govern it, audit its outputs, and intervene when it gets things wrong. What you are really designing is a new operating model in which humans and AI work together which is a harder design problem than swapping one for the other.
Before committing investment, ask two questions:
Is GenAI actually cheaper? - is the anticipated TCO significantly less than the current operating cost? Many organisations are surprised to find it is not.
Does GenAI unlock something new? - does it provide benefits beyond what is possible through the current operating model - such as scale, speed, risk mitigation or an innovation that will opens up new growth opportunities?
If the answer to both of these questions is "no," you're automating for the sake of it.
Early projects may focus on simpler, non-transformational use cases to help the organisation learn what it takes to implement enterprise scale GenAI and climb the AI maturity curve. But these should be positioned as stepping stones not the destination.
A rigorous focus on TCO forces better questions: not "how do we automate what we do today?" but "what new operating models does GenAI make possible that were previously out of reach?". This line of questioning will enable you to isolate where the true value of GenAI lies.
In one recent engagement, a client came to us with a requirement to use GenAI to automate an existing process. We pushed back and asked them to look wider. Using a Wardley Map to examine their full value chain, we identified a genuinely transformational opportunity. The payoff of the pivot was roughly tenfold the impact of the original plan.
Focused, not sprawling
Conway's Law and application of Team Topologies reminds us that systems reflect the communication structures of the organisations that build them. AI projects are no exception. If your initiative involves multiple disconnected teams with competing priorities, you will build a disconnected solution that loses sight of the original goal.
Be wary of a new "GenAI team" forming within your organisation. GenAI doesn't exist in isolation.
Adopt "product mindset" using tools such as endjin's Data Product Canvas to focus the initiative on solving a real problem for a specific audience. This will enable you to minimise scope and increase your chances of success.
Aim to form a small, multi-disciplinary team around each "product" idea. This team needs to span software engineering, data engineering, AI skills and most importantly people who understand the business domain. The interaction between these disciplines is where the hard problems get solved. The GenAI will introduce capabilities and behaviours that are new to everyone involved. This is inherently complex. You manage that complexity by keeping the team small, the scope tight, and the communication lines short.
Strong leadership is also required to resist the pressure of stakeholders who want to feature-load the initiative or pull it in a different direction, treating it as their one opportunity to get budget for AI. Every additional requirement increases cognitive load on the team and redirects attention away from the core problem.
And when something new and shiny emerges mid-project, as it inevitably will, resist the temptation to chase it unless it solves an existing blocker. During one engagement, Anthropic's Claude models became available on Microsoft Foundry. Whilst it was tempting to try them out, we had already met our acceptance criteria with existing models. So we put the trial of the new models on the backlog and stayed focused on tasks that were more relevant to our goal.
Exceptional, but not exempt
There is a temptation to treat GenAI as being so novel that normal rules don't apply. New technology, new paradigm, new ways of working: surely we need to throw out the old playbook?
This is a mistake. The GenAI is new. The engineering isn't. GenAI changes what you can build. It doesn't change how you build well. You are adopting a powerful new technology, that is evolving at pace, it now encompasses agentic, reasoning, and tool-using capabilities far beyond its original "chat" origins. But you will always rely on the same core engineering disciplines for success.
GenAI is exceptional but not exempt — exceptional in its capabilities, but not exempt from the disciplines that make software engineering projects successful.
A GenAI project is a software engineering project. It combines application development, systems integration, data engineering skills and devops. You will be required to leverage familiar platforms and patterns: such as REST APIs, responsive user experiences, lakehouse architectures, middleware, ELT and schema-driven validation. The GenAI component, however sophisticated, sits as a component within this broader ecosystem.
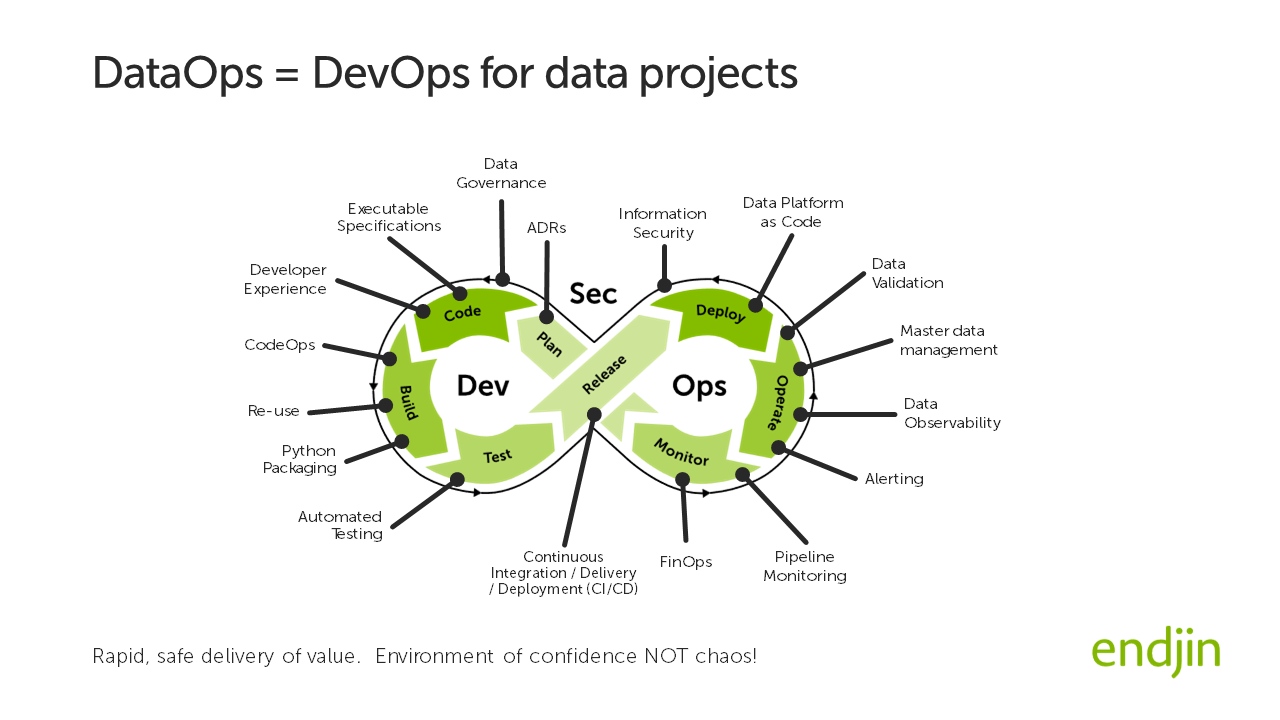
The initiative will place a spotlight on your engineering maturity. If you don't have established DataOps practices, you will struggle to operate with the agility that a production-scale GenAI project demands. Infrastructure as code, robust DTAP environments, automated deployments, observability, least-privilege access and resource tagging for downstream FinOps are examples of first-order capabilities baked into the solution from day one, not bolted on later.
If you have weaknesses in these areas, the GenAI project will expose them. Be honest about the gaps and address them proactively. This may be the moment for an organisational readiness assessment to highlight skills that need strengthening: not just gaps in knowhow about applying AI, but also gaps software and data engineering skills that are necessary to enable the AI to be implemented in a secure, scalable and safe manner.
The same principle applies to technology choices. The GenAI space moves fast; new toolkits and SDKs emerge and fade within months. Choose wisely, but don't agonise of that choice. Start as simple as possible, focused on the initial use case. Understand your software supply chain, and as ever, keep it as shallow as possible. Don't try to design a platform for all possible future scenarios: you will learn so much through the first few implementations that an architectural pivot becomes likely.
On one recent project, we debated whether to use LlamaIndex, LangChain, or Microsoft Agent Framework as the orchestration framework for a RAG solution. In the end, we chose to build our own after hitting limitations baked into these frameworks. The discipline of understanding your requirements before committing to a framework served us better than the framework itself.
Verified, not assumed
GenAI models don't generate knowledge, they generate plausible outputs based on patterns learned from vast quantities of training data and the context you provide as input.
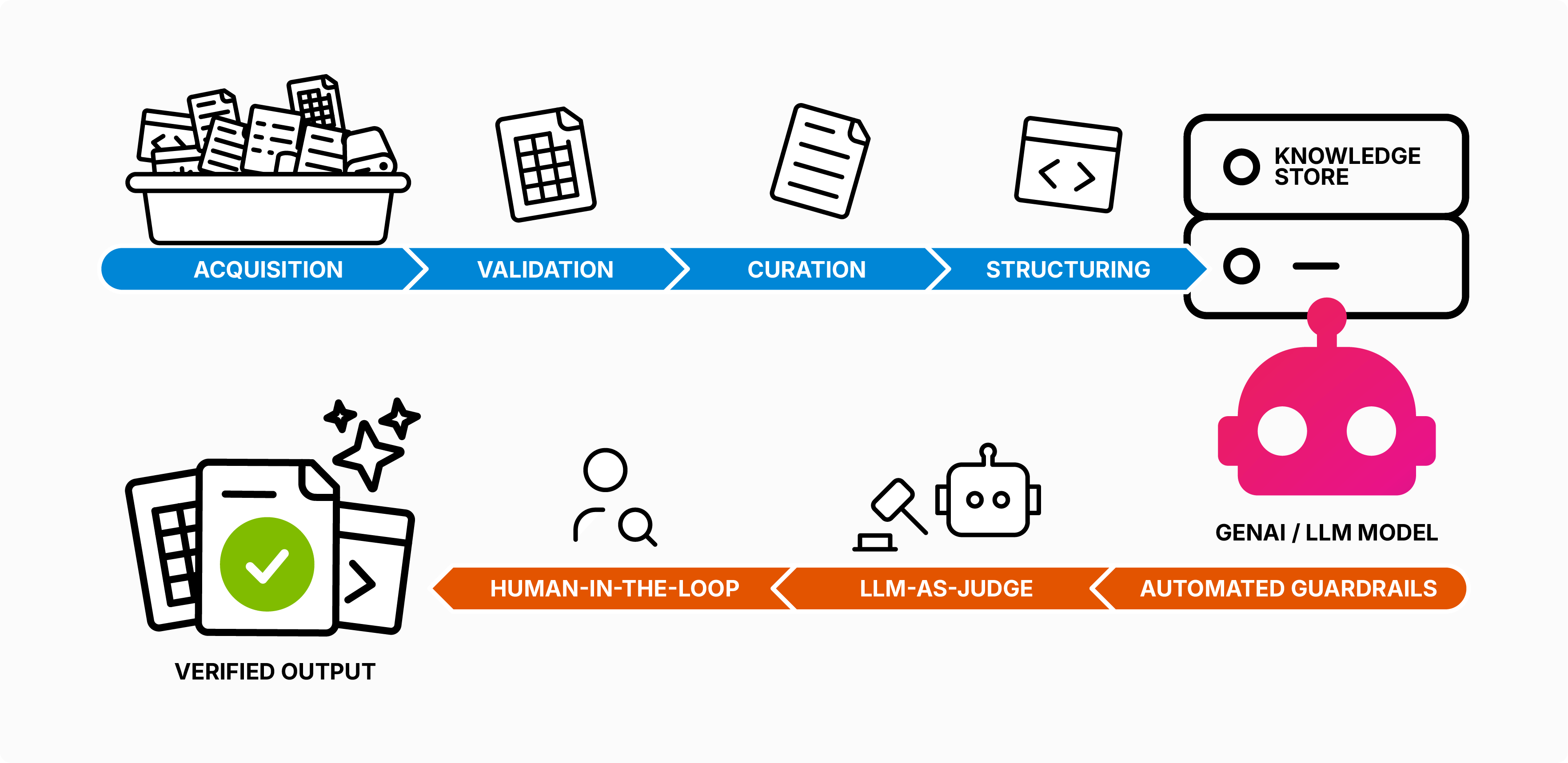
Think of GenAI as a knowledge processor rather than a knowledge generator. We find that 80% of the work required to get value from a GenAI model involves retrieving, validating, curating and structuring knowledge so the model can process it effectively.
GenAI will do is place a spotlight on your data estate. The quality, consistency, and reliability of your data, information, and knowledge become mission-critical when you're feeding it to a model that will confidently generate outputs based on whatever you provide. Organisations that have neglected data governance, have allowed inconsistent taxonomies to proliferate, or tolerated undocumented tribal knowledge will find these sins exposed. Often publicly, in the form of contradictions or confidently wrong answers. GenAI doesn't create data quality problems; it amplifies them. If your foundations are shaky, GenAI will make that painfully visible.
Two principles apply consistently, regardless of how sophisticated your architecture becomes:
Quality in, quality out. - we know that the output of any model is constrained by the quality of the input it is provided. Quantity is also a factor to consider: research into context rot demonstrates that LLM performance degrades with input length, even when the model retrieves relevant information perfectly. Curate ruthlessly. Structure clearly. Less is more.
Don't trust, verify. - everything a GenAI produces should be fact-checked. Your architecture must provide verification at each step, with feedback loops to correct the model when needed. Feedback loops should be established at both build time and run time.
Give the GenAI model concise, well-structured, verified knowledge to process and fact-check what it generates.
We recommend specifying structured outputs such as JSON, then validating both schema and contents. Are categorical values valid? Do citations actually exist? On one project, we discovered the model was confidently hallucinating citations to documents that weren't in the source corpus. This wasn't a prompting failure, it was a side effect of using an LLM. Expect this behaviour and engineer accordingly.
Verification needn't be manual for every output. Think of a factory production line: you don't have a human inspecting every widget, but you do have a laser scanning each one against known tolerances. For GenAI, this means layered verification: automated guardrails validating 100% of outputs, adding an "LLM-as-judge" to flag anomalies and human review for random samples.
In all cases, the human governs the loop setting policy, reviewing edge cases, calibrating the system even when they're not in the loop for every transaction.
Finally, acceptance criteria matter enormously. Don't rely on informal testing. We apply software engineering discipline, by building a suite of executable specifications that run can be run on demand. GenAI is non-deterministic: so we don't expect outputs to be identical every time, or tests to pass every time. But you can define a minimum pass rate that signals the solution is performing within acceptable bounds.
In Q3 2025 our suite of tests enabled us to detect model drift triggered by three separate infrastructure changes implemented by Anthropic that combined to cause a regression that took days to diagnose. We were able to detect this quickly, flip to a different model and prove that this action had restored the performance of the whole system to an acceptable level.
Continuous learning, not just delivering
If you're doing AI, you need to follow the scientific Build, Measure, Learn method across the end-to-end architecture. Software engineering disciplines provide automation and robust processes that enable rapid feedback loops. This allows you to understand, govern and manage the unpredictable, non-deterministic element: the GenAI model.
The most valuable output from a GenAI project is often not the solution itself: it's the learning.
Treat blockers as opportunities. On one project, we discovered that our mental model of how Azure AI Search worked was fundamentally wrong. This wasn't a failure, it was a moment of insight that reshaped our approach. The ability to pause, reflect, and re-orient in response to unexpected findings is becoming critical in an environment where uncertainty is the norm.
There are many variables that dramatically affect GenAI performance: prompt structure, chunk size, retrieval strategy, model selection, temperature settings. Expect timescales and budget to be generally twice to enable continuous learning, deliberately set aside budget and project time for:
Establishing foundations - creating space for the team to align their understanding and put important artefacts in place. Expect the pace to feel slow at the start. Activities such as data curation, agreeing terminology (the ubiquitous language) and alignment on success criteria all take time. Hold your nerve. Pushing forward without these foundations costs more downstream.
Experimentation time build time into the plan for experimentation, don't treat it as an indulgence to squeeze in if there's time left over. For example, a short experiment on one project to evaluate models lead us to understand that Gemini Flash 2 performed as well as Gemini 2.5 Pro for the specific use case generated significant benefit because it enabled us to reduce latency and cost.
Re-evaluating prior decisions against new models. The pace of change is so fast that a use case that doesn't work in September might work well in October with the next model increment.
Sharing lessons learned - set aside time for the team to share what they have learned at regular intervals, not just what has worked but what has worked but also what has not. We adopt a weekly "show and tell" for this purpose where the meeting is recorded and the video / transcript / AI summary is captured for future reference.
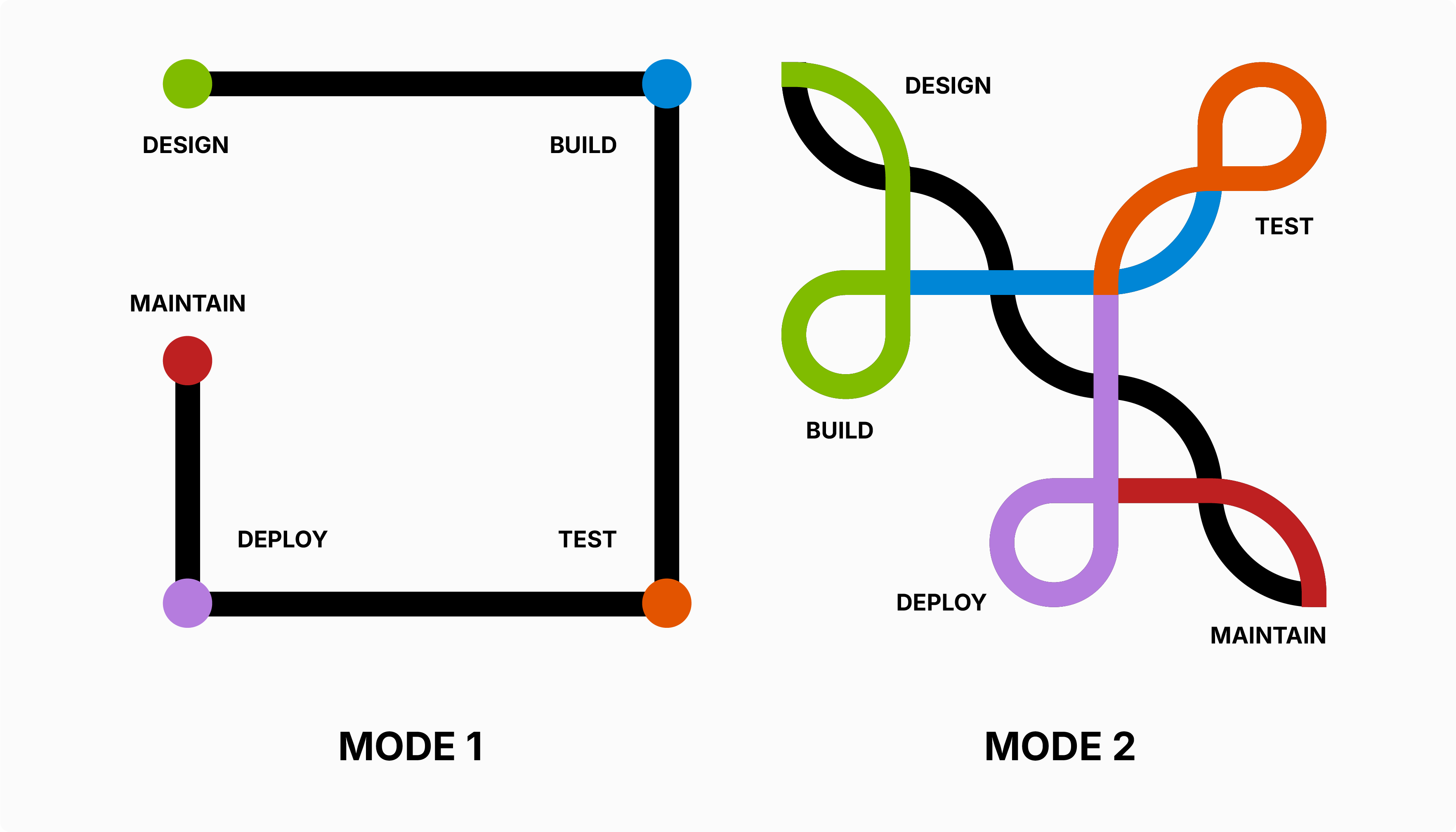
Mode 2, not Mode 1
To succeed your organisation will need to become bi-modal:
Mode 1 - many organisations are comfortable operating in what we might call "Mode 1": waterfall project lifecycles, fixed-price tenders, confident milestones, and a clear line of sight from requirements to delivery. This assumes you broadly understand both the problem and the solution — you're executing against a known destination.
Mode 2 - early-stage GenAI work demands "Mode 2": a fundamentally different posture where you are more focused on learning than delivering. The destination itself is uncertain. You need the flexibility to pivot week to week as you discover what the model can and cannot do, what your data will and will not support, and where the real value lies. Fixed-price contracts and rigid milestone plans are a poor fit for this type of work. Instead, think in terms of time-boxed experiments, learning objectives rather than delivery objectives, and the discipline to stop when the evidence tells you to.
GenAI projects are expensive endeavors, with a high degree of uncertainty: you will hit dead ends, you will need to pivot when the model doesn't perform as expected. Set clear decision points (at least fortnightly) where viability is reviewed openly. Apply a "Mode 2 mindset" to pause the project if it is no longer viable, and treat that decision as a success. Better to release resources to tackle the next initiative than to push on with a thankless task.
Mode 2 isn't permanent. As understanding crystallises and the solution stabilises, you can shift back toward Mode 1 for scaling and operationalisation. But forcing Mode 1 thinking onto Mode 2 problems is a recipe for expensive disappointment.
Ready to tune your orchestra?
GenAI adoption will continue to accelerate. Organisations that treat it as an opportunity to abandon engineering discipline will generate noise. Those that recognise GenAI as a powerful new capability that is exceptional but not exempt will create something worth listening to.
There are aspects of GenAI that genuinely are new: the stochastic nature of outputs, the emergent capabilities that surprise even model creators, the speed at which the frontier moves. These warrant attention. But they don't warrant abandoning the disciplines that make software engineering work.
The principles set out in this blog are not limited to GenAI. The same patterns apply to every disruptive technology wave of the last thirty years: the web, cloud, mobile, blockchain, big data. The hype, the transformational promise, and the engineering disciplines that separate success from failure recur each time. At its heart, this is about effective innovation management. Organisations with solid innovation processes will be well placed for GenAI and whatever appears over the horizon next.
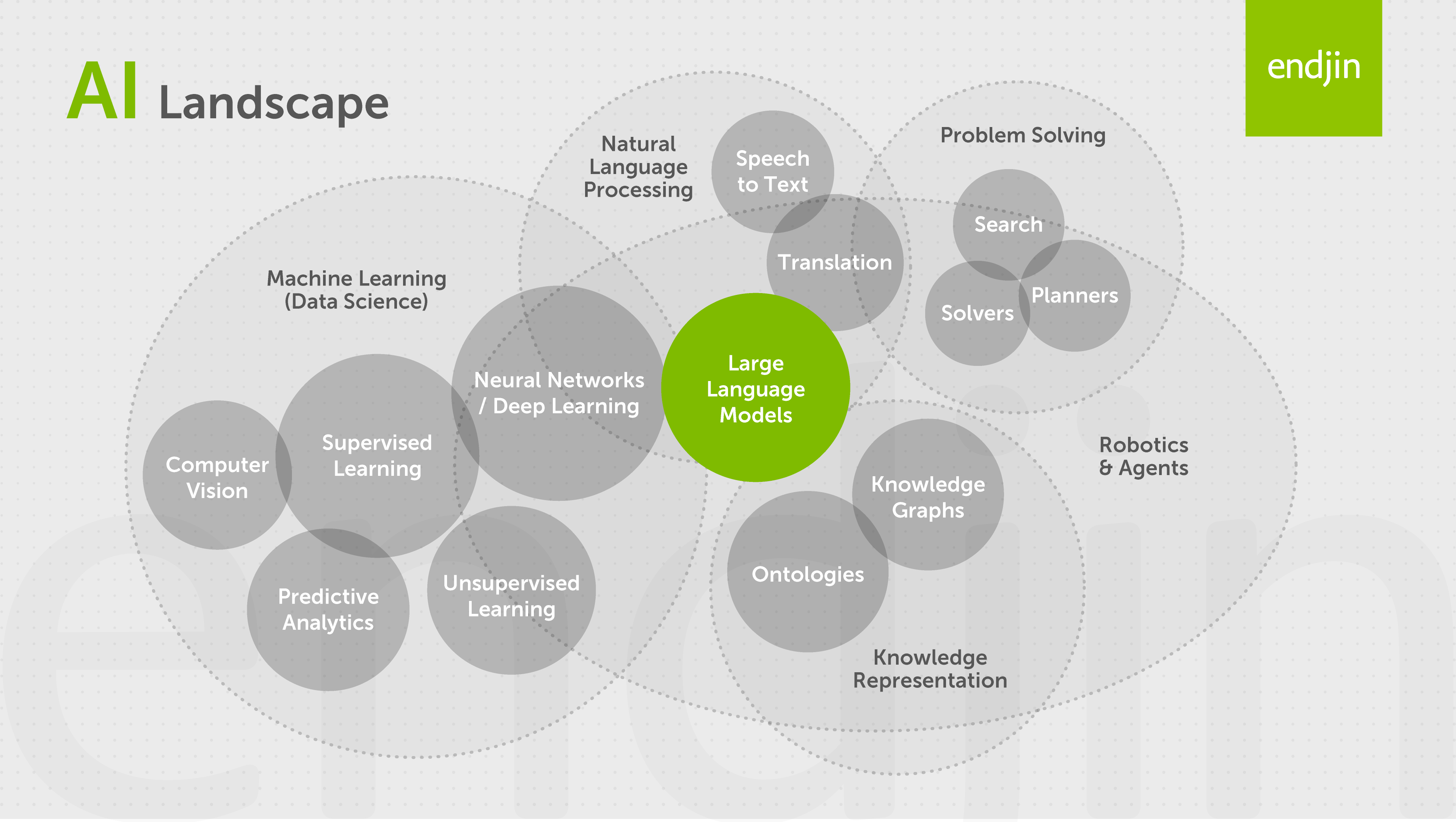
It is also worth disambiguating GenAI from the wider field of AI. "AI" has become an umbrella term — much as "cloud" once was — that conflates GenAI with more traditional and proven Machine Learning techniques. The devil is in the detail and it's best not to talk about it like a silver bullet. When cloud was at the peak of its hype cycle, I was as guilty as anyone of reaching for "we'll just stick it in the cloud" as the answer to every problem. The AI umbrella covers a broad spectrum of capabilities — each with its own strengths, weaknesses, and use cases it is genuinely suited to.
This blog is one half of a pair. It addresses the question "once we've decided to do this, how do we do it well?". Its companion piece, AI Strategy: Think Top-Down, Experiment Bottom-Up, addresses the question that comes first: "how do we decide what to do?". Engineering discipline without strategic clarity produces well-built solutions to the wrong problem. Strategic clarity without engineering discipline produces ambitions that never reach production. Both are needed.
The question isn't whether your organisation will adopt GenAI, it's whether you'll make music or noise. The instrument is ready. The question is: is your orchestra? If you are preparing for your first enterprise-scale AI initiative, or reflecting on one that didn't deliver what you hoped, we would be happy to talk. Our 90-minute Data Strategy Briefing provides an end-to-end view of the data and AI landscape, how it is evolving and how leading organisations are setting themselves up for success.